ChatGPT Images 2.0 출시 - 이미지 생성조차 1위를 차지한 OpenAI
OpenAI가 ChatGPT Images 2.0(모델 ID gpt-image-2)을 공개했다.
이미지 생성의 약점이던 텍스트·다국어·일관성을 크게 끌어올리고,
대화형 편집과 프롬프트 재작성까지 하나의 흐름으로 묶은 OpenAI의 새 이미지 생성 모델이다.
| 항목 | 내용 |
|---|---|
| 공식명 | ChatGPT Images 2.0 (모델 ID gpt-image-2) |
| 공개일 | 2026-04-21 (ChatGPT, API, Codex) |
| 이전 흐름 | gpt-image-1 → gpt-image-1.5 → gpt-image-2 |
| 접근 경로 | ChatGPT + OpenAI API + Codex |
| 가격 (API) | 1024×1024 기준 low 약 $0.006, medium 약 $0.053, high 약 $0.211 |
| 해상도 | 1024×1024부터 2K, 실험적 4K급 출력까지 지원 |
| 폐기 대상 | dall-e-2, dall-e-3 API 스냅샷: 2026-05-12 종료 예정 |
Weekly Tech Trend Talk 스터디(26.04.23)
공개 전부터 화제였던 “Duct Tape”
사실 이 모델, 공식 발표 이전부터 커뮤니티를 들썩이게 만들었다. 2026-04-04 LMArena image arena에 세 개의 익명 변종이 조용히 등장했고, 이름이 모두 접착 테이프 계열이라 커뮤니티는 통칭 “Duct Tape”으로 불렀다.
maskingtape-alphagaffertape-alphapackingtape-alpha
특히 한글·중국어·일본어 텍스트 렌더링이 압도적이라 아시아권 커뮤니티가 먼저 발견해 퍼뜨렸다. 며칠 뒤 세 변종은 아레나에서 조용히 제거됐고, “신모델 사전 테스트다”라는 해석이 정설로 굳어졌다. 2026-04-21 ChatGPT Images 2.0이 공식 출시되면서 “그 Duct Tape이 이거였다”가 확정됐다.
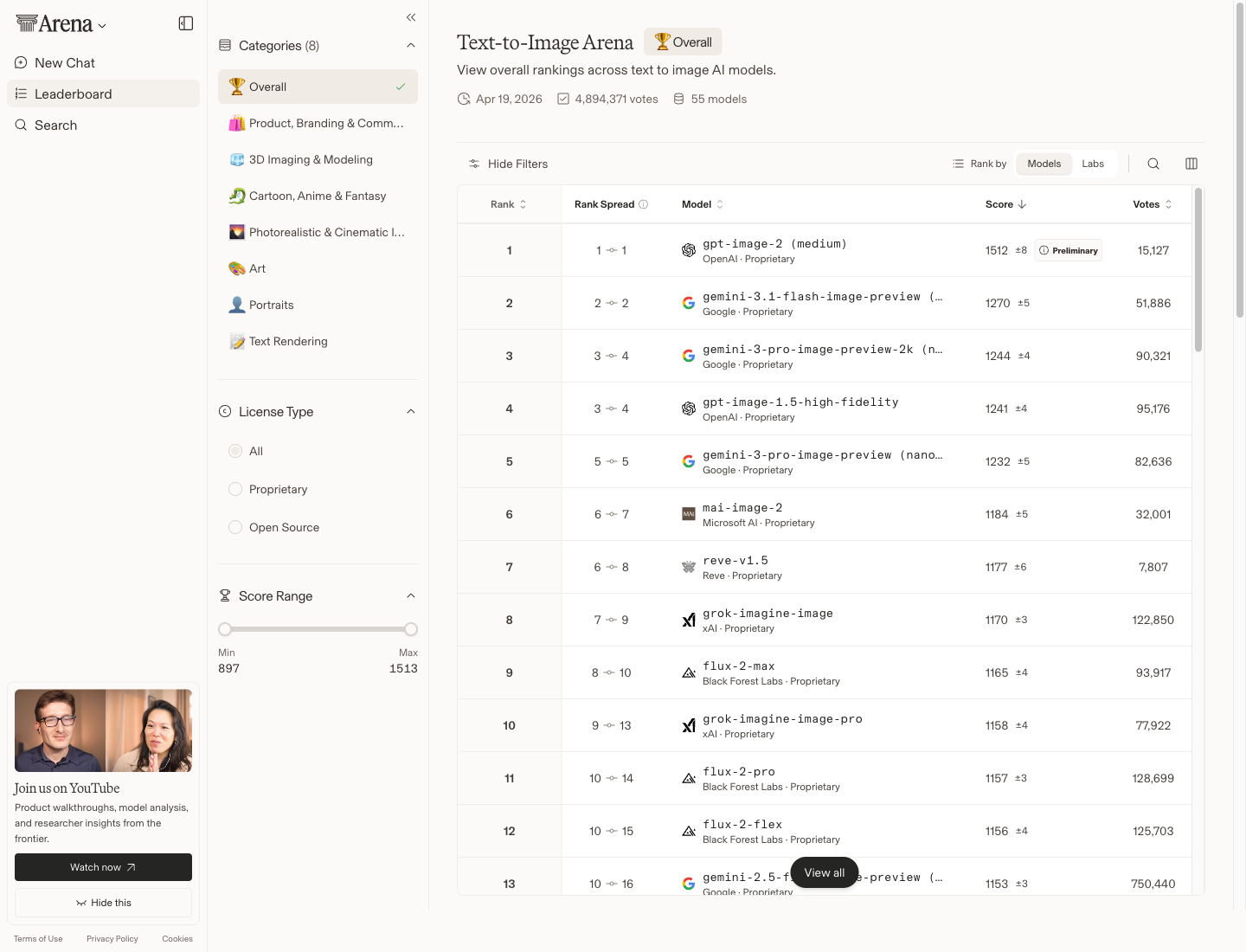
지금도 Arena Text-to-Image Overall 1위다.
gpt-image-2 (medium) 1,512점, 2위 gemini-3.1-flash-image-preview 1,270점으로 +242점 차이가 난다.
공개 전 익명 모델로 먼저 화제가 됐고, 출시 후에도 리더보드 상단을 유지하고 있다.
그럼 세 변종은 각각 뭐였을까?
OpenAI는 세 코드명의 의미를 공개하지 않았다. 커뮤니티 해석은 크게 두 갈래다.
가설 A: 기능 분화설
| 익명 코드명 | 테이프의 실제 용도 | 추정 역할 |
|---|---|---|
maskingtape-alpha |
칠할 때 가려두는 테이프 | 편집 / inpaint 강화형 |
gaffertape-alpha |
촬영장에서 쓰는 강력 전문 테이프 | 고급 / 최종 품질형 |
packingtape-alpha |
박스 포장 테이프 | 배치 / 대량 생성형 |
가설 B: 모드 매핑설
| 익명 코드명 | 추정 매핑 |
|---|---|
maskingtape-alpha, gaffertape-alpha |
Instant Mode (빠른 즉시 생성) |
packingtape-alpha |
Thinking Mode (최대 2분 추론) |
세 변종과 실제 출시 모델의 1:1 대응은 공개되지 않았다.
출시 후 공개된 API에서는 gpt-image-2 단일 모델과 quality 파라미터(low / medium / high)가 핵심이다.
DALL·E에서 GPT Image로
먼저 이름부터 정리해야 한다. DALL·E는 OpenAI의 이전 이미지 생성 모델 라인이고, GPT Image는 2025년부터 ChatGPT·API·Codex 이미지 생성을 묶어 가는 새 모델 패밀리다.
| 시기 | 모델 / 제품 | 의미 |
|---|---|---|
| 2021-01 | DALL·E |
텍스트 프롬프트로 이미지를 만드는 OpenAI 초기 연구 모델 |
| 2022 | DALL·E 2 |
현실감, 편집, variation을 강화하며 제품형 이미지 생성으로 진화 |
| 2023 | DALL·E 3 |
ChatGPT가 사용자의 요청을 더 좋은 프롬프트로 바꿔 이미지 모델에 넘기는 흐름이 본격화 |
| 2025-03 | GPT-4o Image Generation / ChatGPT Images 1.0 |
ChatGPT 안에서 이미지 생성이 대화형 기능으로 들어오기 시작 |
| 2025-04 | gpt-image-1 |
GPT Image 패밀리의 첫 API 모델. DALL·E 이후의 새 이미지 API 라인 |
| 2025-12 | gpt-image-1.5 |
gpt-image-1 개선판. 편집 안정성, 지시 이행, 속도와 비용 효율 보강 |
| 2026-04 | gpt-image-2 / ChatGPT Images 2.0 |
텍스트·다국어·레이아웃·참조 이미지·고해상도 워크플로를 크게 강화한 최신 세대 |
핵심 변화는 “DALL·E 이름이 GPT Image로 바뀌었다”가 아니다. DALL·E 3까지는 이미지 전용 모델에 ChatGPT가 프롬프트를 잘 써주는 느낌이 강했다면, GPT Image 계열은 생성·편집·참조 이미지·멀티턴 대화를 하나의 작업 흐름으로 묶는 쪽으로 진화하고 있다.
| 항목 | gpt-image-1 / gpt-image-1.5 |
gpt-image-2 |
|---|---|---|
| 대표 위치 | GPT Image API 1세대와 중간 개선판 | ChatGPT Images 2.0의 API 모델 |
| API 흐름 | 단일 이미지 생성·편집 중심 | 단일 작업은 Image API, 대화형·멀티턴 편집은 Responses API 권장 |
| 텍스트 렌더링 | 개선됐지만 텍스트 밀도 높은 이미지에서는 실패가 남음 | 더 선명한 글자, 일관된 레이아웃, 다국어 텍스트 렌더링 개선 |
| 다국어 스크립트 | 제한적 | 한글·CJK·남아시아권 문자 등 글로벌 스크립트 대응 강화 |
| 일관성 | 단일 이미지와 간단한 편집 중심 | 참조 이미지·멀티턴 편집에서 인물·제품·브랜드 요소 보존 강화 |
| 해상도 | 1024x1024, 1024x1536, 1536x1024 중심 |
제약 조건 안에서 유연한 size 지원. 2K 초과는 실험적 |
| Reasoning | 이미지 생성 전 의도 해석은 제한적 | 메인 대화 모델의 요청 해석·프롬프트 재작성과 gpt-image-2의 시각 구성력이 결합 |
DALL·E API 스냅샷은 2026-05-12부로 종료된다.
새 이미지 생성 작업은 이제 gpt-image-2를 기본 선택지로 두고 보는 편이 자연스럽다.
무엇이 바뀌었나: 개선의 네 축
| 축 | 체감 포인트 |
|---|---|
| 텍스트 렌더링 | 라틴·CJK·힌디·벵갈리 같은 다국어 텍스트 렌더링이 크게 개선. 포스터·메뉴·인포그래픽 같은 실사용 이미지에 강함 |
| 다국어 혼합 레이아웃 | 한글·일본·중국·영어가 한 이미지에 섞여도 각 스크립트 규칙을 지킴 |
| 참조 이미지·편집 일관성 | 멀티턴 편집과 참조 이미지 기반 작업에서 같은 캐릭터·제품·브랜드 요소를 더 잘 유지 |
| Reasoning / planning | 구조·레이아웃·세계지식 이해와 메인 대화 모델의 프롬프트 재작성·도구 호출이 결합된 흐름 |
수치·공식 제약 근거는 다음과 같다.
- LMArena Image Arena 1,512 Elo, 2위와 +242pt 마진
gpt-image-2는 최대 edge 3840px, 비율 3:1 이내, 총 8,294,400px 이하의 유연한 해상도 지원- OpenAI 프롬프트 가이드는 핵심 능력으로 photorealism, identity preservation, reliable text rendering, structured visuals, real-world knowledge/reasoning을 명시

이미지 생성에서 말하는 Reasoning
여기서 reasoning은 모델의 생각을 문장으로 보여준다는 뜻이 아니다. 사용자의 요청을 이미지로 바꾸기 전에 무엇을 그려야 하는지, 어떤 레이아웃이 맞는지, 어떤 정보와 맥락을 유지해야 하는지를 더 잘 구조화한다는 의미에 가깝다.
| 질문 | 답 |
|---|---|
| reasoning token이 따로 보이나? | 아니다. 외부에 보이는 것은 텍스트 응답, image_generation_call, revised_prompt, 최종 이미지다. |
| 자연어 답변을 하다가 이미지 생성으로 넘어가나? | 반드시 그런 순서는 아니다. API 응답에서는 텍스트 메시지와 이미지 생성 호출이 별도 아이템으로 분리된다. |
| ChatGPT가 프롬프트를 대신 다듬나? | Responses API에서는 메인 대화 모델이 프롬프트를 자동 개선하고 revised_prompt로 남긴다. |
| 그래서 기존 프롬프트 래퍼와 뭐가 다른가? | 대화 맥락, 참조 이미지, 멀티턴 편집, generate/edit 선택이 하나의 흐름으로 묶인다. |
실제 API 흐름은 다음처럼 이해하면 된다.
| 단계 | 역할 |
|---|---|
| 요청 해석 | gpt-5.4 같은 메인 대화 모델이 사용자의 의도를 읽는다. |
| 프롬프트 재작성 | 이미지 모델이 잘 그릴 수 있도록 요청을 더 구체화한다. |
| 이미지 도구 호출 | image_generation 도구가 호출된다. |
| 렌더링 | gpt-image-2가 최종 이미지를 만든다. |
| 후속 편집 | 이전 응답이나 이미지 ID를 이어받아 다시 수정한다. |
핵심은 “이미지 모델이 속으로 생각한다”가 아니라 이미지 생성이 대화형 작업 흐름 안으로 들어왔다는 점이다. 이제 사용자는 프롬프트를 한 번 던지는 사람이 아니라, 결과물을 보며 계속 디렉팅하는 사람에 가까워진다.
어디서, 누가, 어떻게 쓰나
플랫폼
| 경로 | 상태 |
|---|---|
| ChatGPT 앱 | 2026-04-21 공개 |
OpenAI API (gpt-image-2) |
2026-04-21 공개 |
| Codex | 2026-04-21 공개. Codex 내장 이미지 생성은 gpt-image-2 사용 |
API 핵심 옵션
| 옵션 | 의미 |
|---|---|
quality |
low / medium / high로 속도와 품질을 조절 |
size |
정사각형, 세로형, 가로형, 2K, 4K급 출력 크기 지정 |
action |
새 이미지 생성과 기존 이미지 편집을 자동 선택하거나 강제 |
format |
PNG, JPEG, WebP 출력 선택 |
compression |
JPEG / WebP 압축률 조절 |
입출력 포맷
지원 입력은 텍스트 프롬프트(다국어 포함), 참조 이미지(style reference), 마스크(inpaint), 멀티턴 대화형 편집이다. 출력은 다음과 같이 조절한다.
| 항목 | 옵션 |
|---|---|
| 포맷 | PNG (기본) / JPEG / WebP |
| 압축 | output_compression 0~100% |
| 품질 | low / medium / high |
| 해상도 | 1024x1024, 1536x1024, 2048x2048, 3840x2160 등 |
| 비율 | 최대 3:1 |
| 멀티턴 편집 | 이전 이미지나 응답을 이어받아 다시 수정 |
| 투명 배경 | 직접 출력은 미지원. 배경 제거 후처리로 해결 |
대표 활용
| 작업 | 활용 포인트 |
|---|---|
| 신규 생성 | 텍스트 → 이미지 |
| 편집(inpaint) | 마스크 영역만 교체, 나머지 보존 |
| 스타일 전이 | 참조 이미지의 스타일 적용 |
| 다국어 텍스트 | 포스터·메뉴·간판 한글·CJK 직접 렌더링 |
| 인포그래픽 | 데이터·범례·색상 의미론 고려 |
| 다중 패널 만화 | 말풍선·페이싱·캐릭터 일관 |
| UI 목업 | 타이포·레이아웃 추론 |
| 제품 컨셉 이미지 | 동일 제품 여러 앵글 유지 |
가격
API 가격은 text token, image input token, image output token을 합산한다. 첫 추산은 “이미지 한 장당 대략 얼마인가”에서 시작하면 된다.
| 1024×1024 기준 | 예상 비용 |
|---|---|
low |
약 $0.006 / image |
medium |
약 $0.053 / image |
high |
약 $0.211 / image |
| 토큰 단가 | 입력 | Cached 입력 | 출력 |
|---|---|---|---|
| Image | $8 / 1M | $2 / 1M | $30 / 1M |
| Text | $5 / 1M | $1.25 / 1M | $10 / 1M |
참조 이미지가 많거나 멀티턴 편집이 길어질수록 입력 토큰 비용도 함께 늘어난다.
공식이 밀고 있는 활용 카테고리
| 카테고리 | 예시 |
|---|---|
| 다국어 마케팅 | 로컬라이즈된 광고·SNS 이미지 |
| 인포그래픽 | 리서치 요약, 통계 시각화 |
| 메뉴판·포스터 | 식당·행사·공연 실사용 가능한 타이포 |
| UI 프로토타이핑 | 앱 화면 mock, 랜딩 페이지 |
| 다중 패널 만화 | 짧은 웹툰, 스토리보드 |
| 매거진 레이아웃 | 표지, 본문 페이지 |
| 슬라이드 | 발표 자료 키비주얼 |

한계와 주의점
| 주의점 | 이유 |
|---|---|
| 복잡한 요청은 느리다 | 고품질, 고해상도, 참조 이미지, 멀티턴 편집이 붙을수록 대기 시간이 길어진다 |
| 비용 차이가 크다 | low와 high의 이미지당 비용 차이가 크므로 대량 생성은 품질 전략이 필요하다 |
| 사실 정확도는 검증해야 한다 | 지도, 과학 도해, 수치, 해부학처럼 정확성이 중요한 이미지는 별도 검수가 필요하다 |
| 투명 배경은 후처리 영역 | gpt-image-2는 투명 배경 직접 출력을 지원하지 않는다 |
| 권리 이슈가 남는다 | 실제 인물, 로고, 브랜드, IP가 들어가는 이미지는 사용 권한과 정책을 따로 봐야 한다 |
Google Nano Banana Pro, Midjourney, Ideogram 등 이미지 생성 경쟁자도 공격적이다.
gpt-image-2의 우위는 오래 고정되지 않을 수 있다.
특히 텍스트 렌더링 격차는 빠르게 좁혀질 가능성이 높다.
결론
DALL·E 3의 최대 약점이었던 텍스트·다국어·일관성을 크게 개선했고, reasoning 모델과 이미지 생성 도구가 결합된 agentic image workflow를 주류화했다.
| 상황 | 권장 |
|---|---|
| 다국어·CJK 포스터·메뉴·인포그래픽 | gpt-image-2 1순위 |
| 동일 캐릭터·제품 연작 | gpt-image-2 + 참조 이미지·멀티턴 편집 |
| 복잡한 레이아웃·텍스트 밀도 높은 이미지 | medium / high 품질과 구조화된 프롬프트 활용 |
| 실시간 대량 생성 | quality: low부터 검증하거나 경량 모델 병행 |
| 사실 정확도가 중요한 지도·과학 이미지 | 결과물을 반드시 검증 |
이미지 생성은 더 이상 “프롬프트 한 줄로 결과를 받는” 작업이 아니다.
대화 맥락 위에서 디렉팅하고 편집하는 흐름으로 옮겨가고 있고,
gpt-image-2는 그 흐름의 현재 기준선이다.
참고 자료
1차 공식 자료
- DALL·E: Creating images from text
- DALL·E 2
- DALL·E 3
- Introducing 4o Image Generation
- Introducing our latest image generation model in the API
- The new ChatGPT Images is here
- Introducing ChatGPT Images 2.0
- Image generation guide
- gpt-image-2 모델 페이지
- GPT Image Generation Models Prompting Guide
- Introducing gpt-image-2: available in API and Codex
외부 평가 자료
- TechCrunch: ChatGPT’s new Images 2.0 model is surprisingly good at generating text
- The Decoder: ChatGPT Images 2.0 thinks before it generates
- VentureBeat: Multilingual text, infographics, slides, maps, even manga seemingly flawlessly
- Axios: Images in ChatGPT major update
- The New Stack: ChatGPT Images 2.0
- DEV Community: OpenAI’s ‘duct-tape’ model appeared on Arena, then vanished
공유하기
X LinkedIn'AI' 카테고리의 다른 글




댓글남기기