Claude Opus 4.7 출시 - 업무형 에이전트로 무게가 실린 업데이트
Anthropic이 Claude Opus 4.7을 공개했다. 답변 품질을 조금 올린 챗봇 업데이트가 아니라, 코딩 에이전트, 장기 업무 위임, 고해상도 비전, 엄격한 지시 이행을 축으로 개선된 Anthropic의 최상위 공개 모델이다.
| 항목 | 내용 |
|---|---|
| 공개일 | 2026-04-16 |
| 이전 세대 | Claude Opus 4.6 |
| API 모델 ID | claude-opus-4-7 |
| 가격 | 입력 $5 / 출력 $25 (per 1M tokens) |
| 컨텍스트 / 최대 출력 | 1M / 128K tokens |
| 지식 컷오프 | 2026-01 |
| 포지션 | Anthropic의 most capable GA model |
이번 글에서는 세 가지 질문에 답한다.
- Opus 4.6과 비교해 실제로 무엇이 좋아졌는가?
- GPT-5.4, Gemini 3.1 Pro, Mythos Preview와 비교하면 어디쯤인가?
- 어떤 작업에서는 오히려 기대치를 낮춰야 하는가?
Weekly Tech Trend Talk 스터디(26.04.23)
이번 세대의 개선 축
Opus 4.7이 내세우는 변화는 네 가지로 압축된다. 질문은 “이전보다 똑똑해졌나?”가 아니라 “어떤 업무를 덜 감독하고 맡길 수 있게 됐나?”에 가깝다.
| 개선 축 | 확인할 포인트 |
|---|---|
| 코딩 에이전트 | 실제 GitHub issue·터미널 작업·코드 리뷰에서 오래 버티는가 |
| 장기 업무 위임 | 여러 도구와 긴 컨텍스트를 오가며 흐트러지지 않는가 |
| 고해상도 비전 | 화면·차트·문서·UI를 정확히 읽는가 |
| 엄격한 지시 이행 | 명시한 조건을 문자 그대로 지키는가 |
Opus 4.6 대비 변화
공식 메인 벤치마크 표부터 본다.
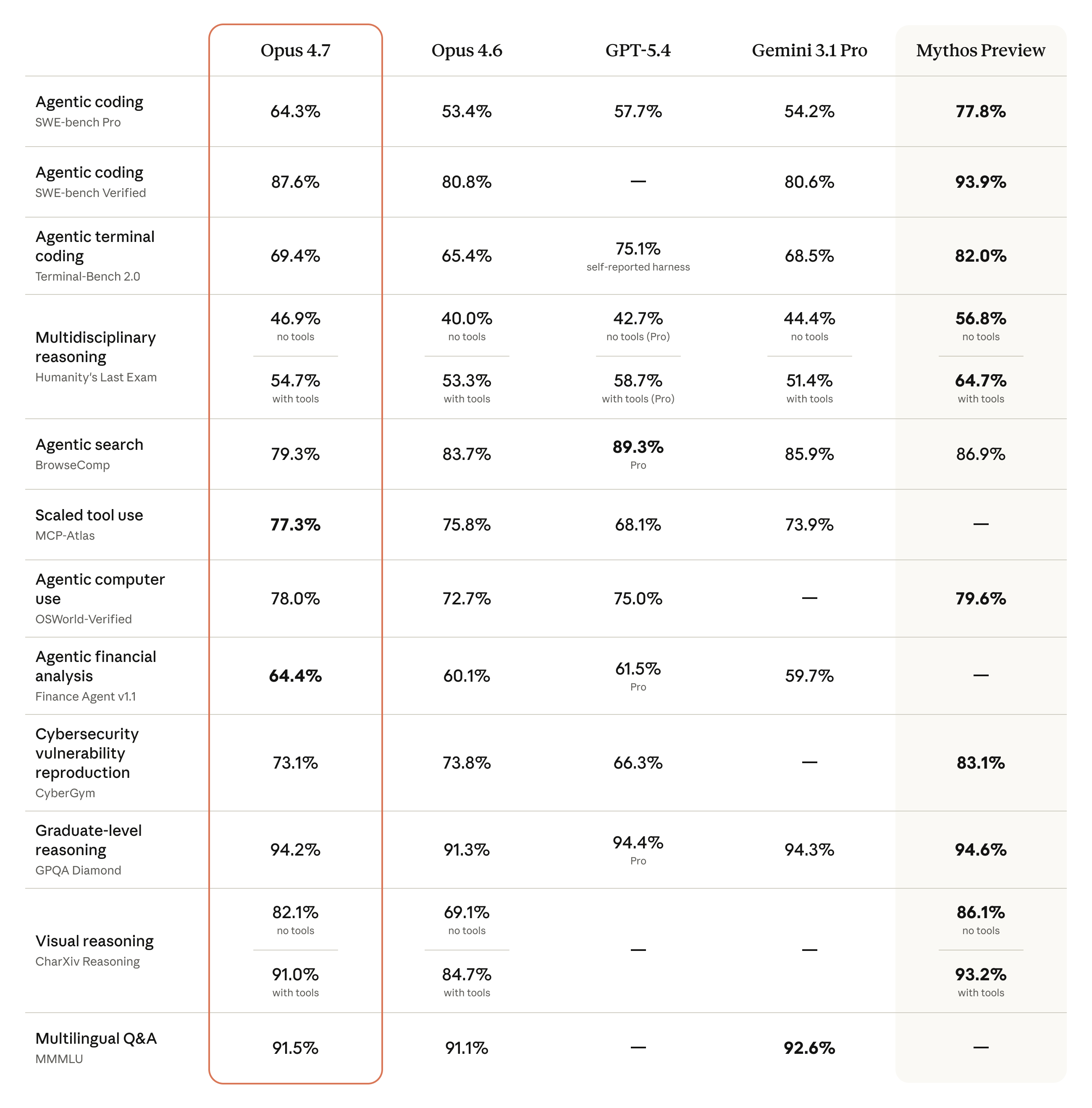
전반적 상승이 아니라 특정 영역에서 선명하게 올랐다.
| 벤치마크 | Opus 4.6 | Opus 4.7 | 변화 | 의미 |
|---|---|---|---|---|
| SWE-bench Pro | 53.4% | 64.3% | +10.9pp | 산업형 코딩 과제에서 큰 상승 |
| SWE-bench Verified | 80.8% | 87.6% | +6.8pp | 검증된 GitHub issue 해결력 강화 |
| Terminal-Bench 2.0 | 65.4% | 69.4% | +4.0pp | 터미널 디버깅·개발 작업 개선 |
| Finance Agent v1.1 | 60.1% | 64.4% | +4.3pp | 업무형 agentic workflow 강화 |
| CharXiv no tools | 69.1% | 82.1% | +13.0pp | 차트·도식 시각 추론 대폭 향상 |
가장 눈에 띄는 것은 SWE-bench Pro와 CharXiv다. 전자는 “진짜 개발 일을 맡길 수 있는가”, 후자는 고해상도 비전이라는 모델 레벨 변화와 직접 연결된다. SWE-bench Verified는 상위 모델들이 포화 구간에 들어가고 있어, 단독 점수보다 어려운 작업형 벤치마크와 같이 읽는 편이 낫다.
다른 모델과 비교한 순위
Artificial Analysis Intelligence Index 기준 Opus 4.7은 57.3점이다. Gemini 3.1 Pro 57.2, GPT-5.4 56.8과 95% 신뢰구간 ±1 안에 들어가 사실상 공동 1위 그룹으로 해석한다.
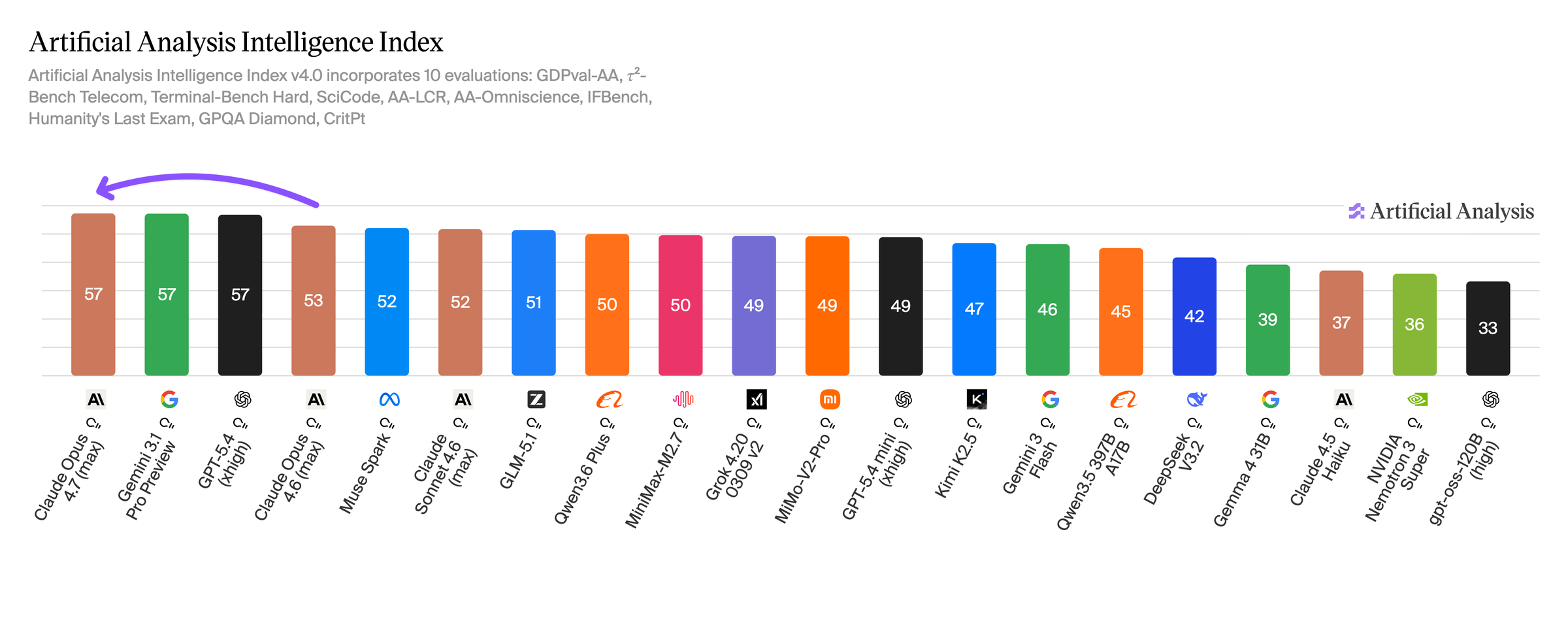
BenchLM 리더보드도 같이 보면 위치가 더 뚜렷해진다. 공개된 exact-source benchmark 결과만 집계하는 사이트인데, Mythos Preview가 1위로 올라와 있고 Opus 4.7이 바로 그 뒤를 잇는다.
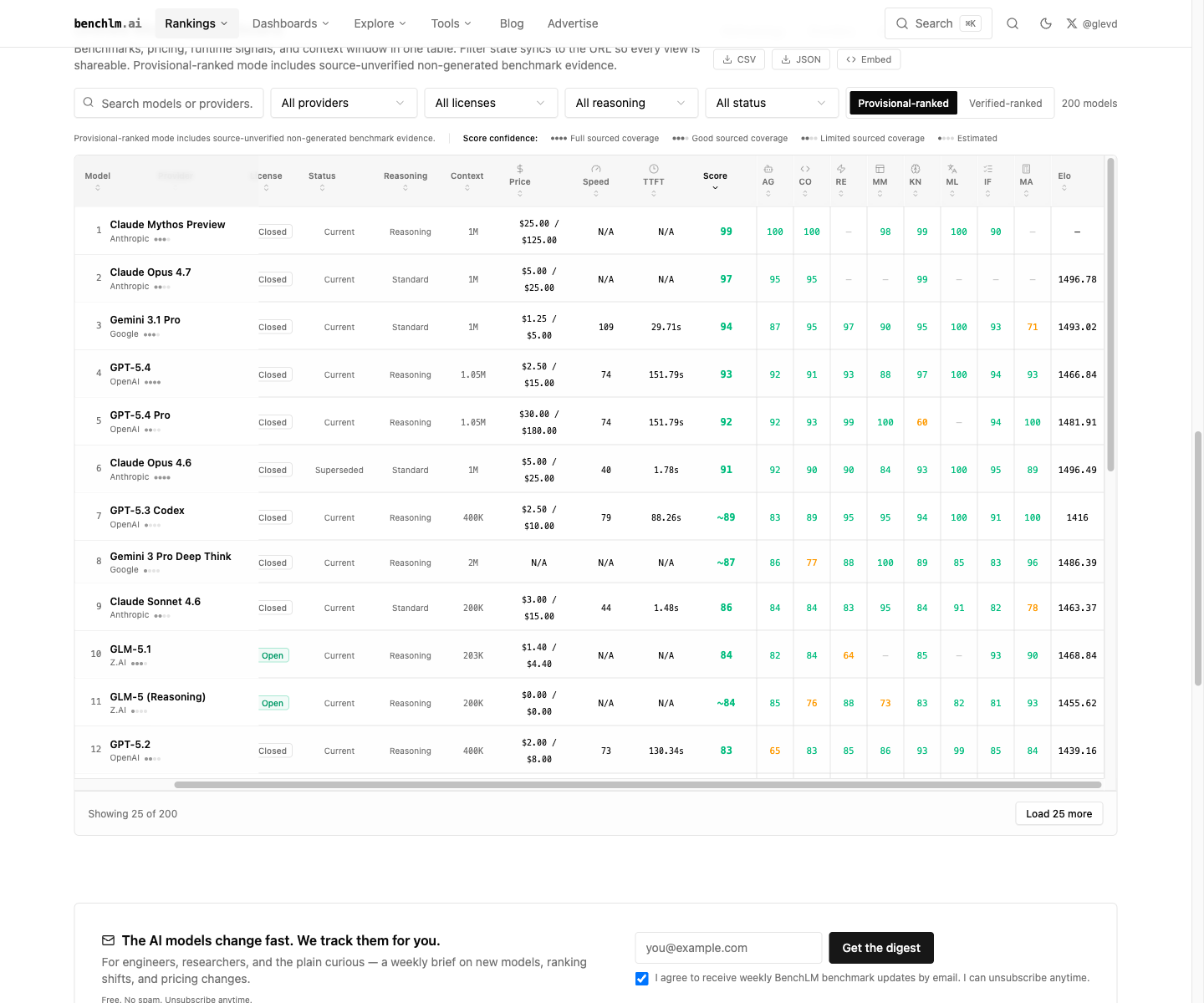
BenchLM은 provisional #2/111, verified #2/15로 표시한다.
단, 공개 exact-source benchmark가 아직 13개뿐이라 확정 순위가 아니라
현재 공개 지표 기반 상위권 위치로 읽는 편이 안전하다.
Mythos Preview는 제한 공개 모델이므로 일반 사용자 기준에서는 Opus 4.7이 사실상 최상단으로 볼 수 있다.
강점
1. 실제 업무형 에이전트 — GDPval-AA 1위
GDPval-AA는 44개 직업·9개 산업의 실제 지식 노동 태스크를 agentic loop로 평가한다. Opus 4.7은 1,753 Elo로 1위, 다음 그룹(Sonnet 4.6, GPT-5.4)보다 약 79 Elo 앞선다.
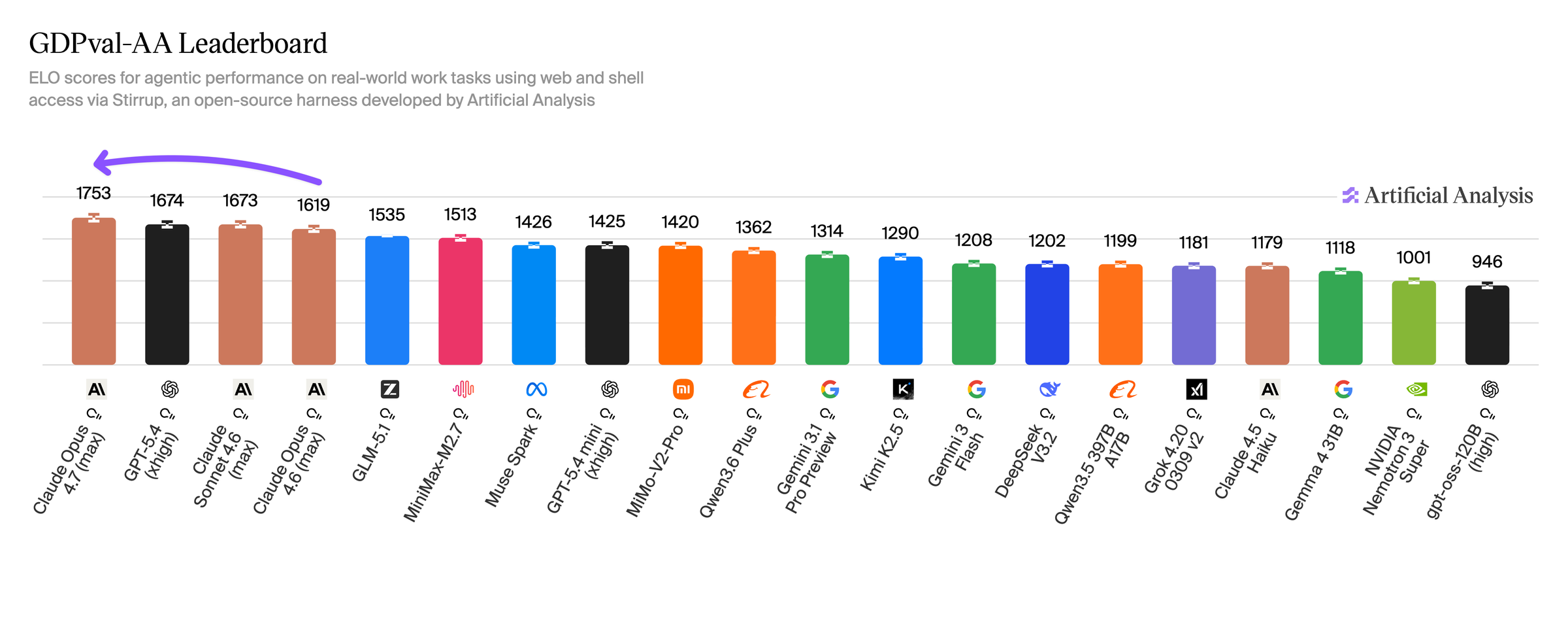
퀴즈형 지식이 아니라 웹·셸을 쓰며 산출물을 만드는 업무에 강하다는 뜻이다. 기대할 변화도 “질문에 잘 답한다”보다 “기획·조사·작성·검증이 섞인 업무를 더 오래 맡긴다” 쪽이다.
2. 코딩 에이전트와 도구 사용
공식 표 기준 Opus 4.7은 일반 공개 모델 중 SWE-bench Pro, SWE-bench Verified, MCP-Atlas에서 강하다. 특히 MCP-Atlas는 복잡한 multi-turn tool-calling을 본다는 점에서 Claude Code 같은 도구의 체감 강점과 직결된다.
코드를 한 번에 쓰는 능력보다 작업을 나누고, 도구를 부르고, 실패를 회복하고, 검증까지 이어가는 능력이 올라간 쪽이다.
3. 고해상도 비전과 시각 추론
이미지 입력 한계가 1568px → 2576px(약 3.75MP)로 확장됐다.
변화는 CharXiv에서 그대로 드러난다.
| 지표 | Opus 4.6 | Opus 4.7 | 변화 |
|---|---|---|---|
| CharXiv no tools | 69.1% | 82.1% | +13.0pp |
| CharXiv with tools | 84.7% | 91.0% | +6.3pp |
| OSWorld-Verified | 72.7% | 78.0% | +5.3pp |
앞으로 차트·논문 그림·대시보드·앱 화면·스크린샷 디버깅에서 이전보다 높은 기대를 걸 수 있다.
4. 모르면 멈추는 능력
AA-Omniscience 결과에서 Opus 4.7은 Opus 4.6보다 hallucination rate가 크게 내려갔다. 정확도가 극적으로 오른 게 아니라, 모르는 문제에서 더 자주 abstain하는 쪽에 가깝다.
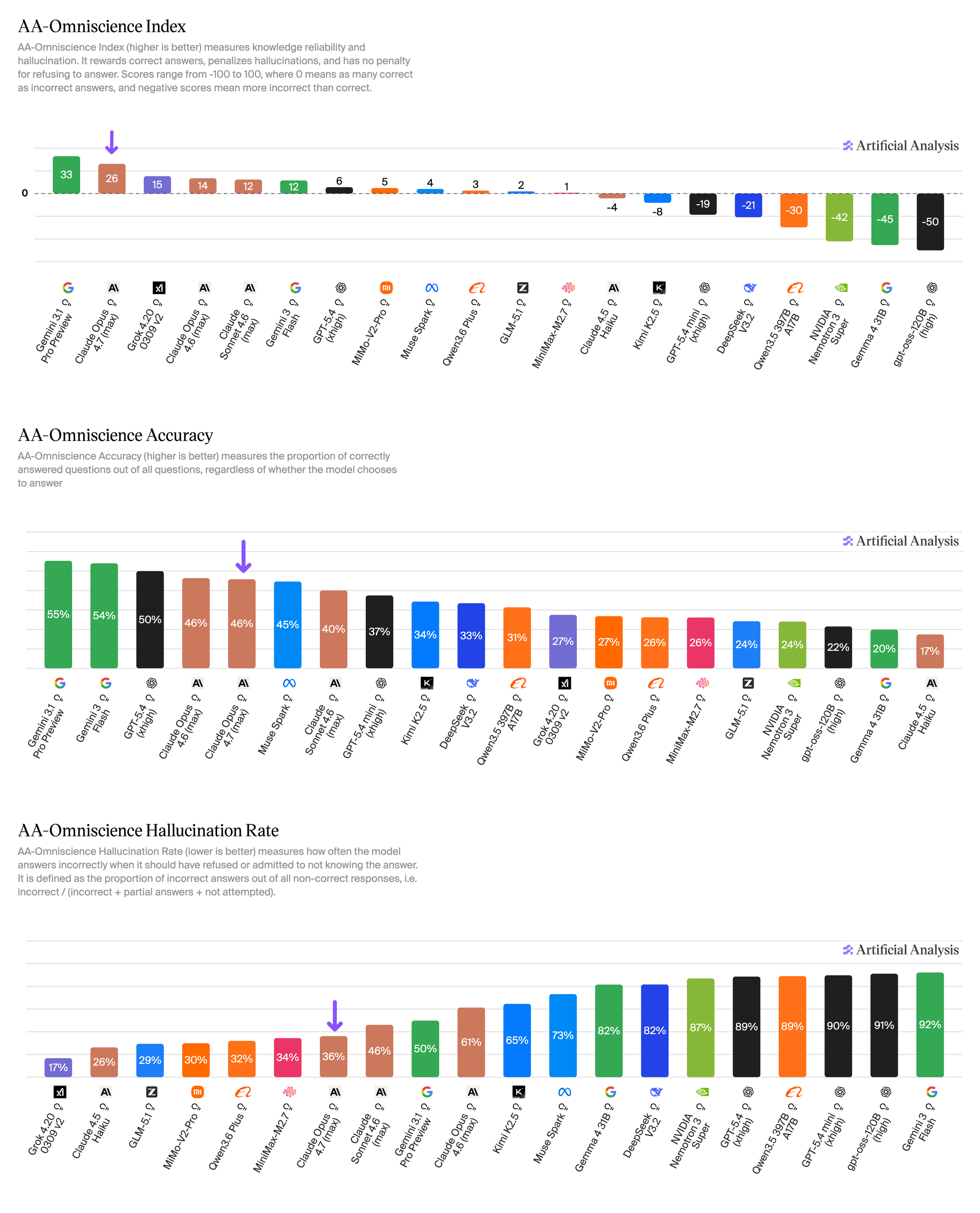
업무용 에이전트에서는 “그럴듯한 오답”보다 “자료 부족 명시 + 다음 확인 단계 제안”이 훨씬 안전하다.
약점과 주의점
공식 발표만 보면 약점이 잘 보이지 않는다. 외부 자료와 표에서 후퇴하거나 밀리는 지점을 따로 봐야 한다.
1. 검색형 에이전트는 오히려 하락
BrowseComp는 multi-step web research 지표인데, Opus 4.6 83.7% → Opus 4.7 79.3%로 -4.4pp 하락했다.
| 모델 | BrowseComp |
|---|---|
| GPT-5.4 Pro | 89.3% |
| Claude Mythos Preview | 86.9% |
| Gemini 3.1 Pro | 85.9% |
| Claude Opus 4.6 | 83.7% |
| Claude Opus 4.7 | 79.3% ↓ |
에이전트 전반에서 무조건 상위호환이 아니다. 웹 검색을 많이 하고 여러 페이지를 종합하는 리서치 워크플로우라면 GPT-5.4나 Gemini 3.1 Pro가 더 맞을 수 있다.
2. 비용은 같지만 사용량이 달라질 수 있다
가격표는 Opus 4.6과 동일($5 / $25)이지만,
마이그레이션 가이드에 따르면 tokenizer가 바뀌어서
같은 입력이 최대 약 1.35배 더 많은 토큰으로 계산될 수 있다.
xhigh·max effort는 더 오래 생각하고 출력 토큰을 더 쓴다.
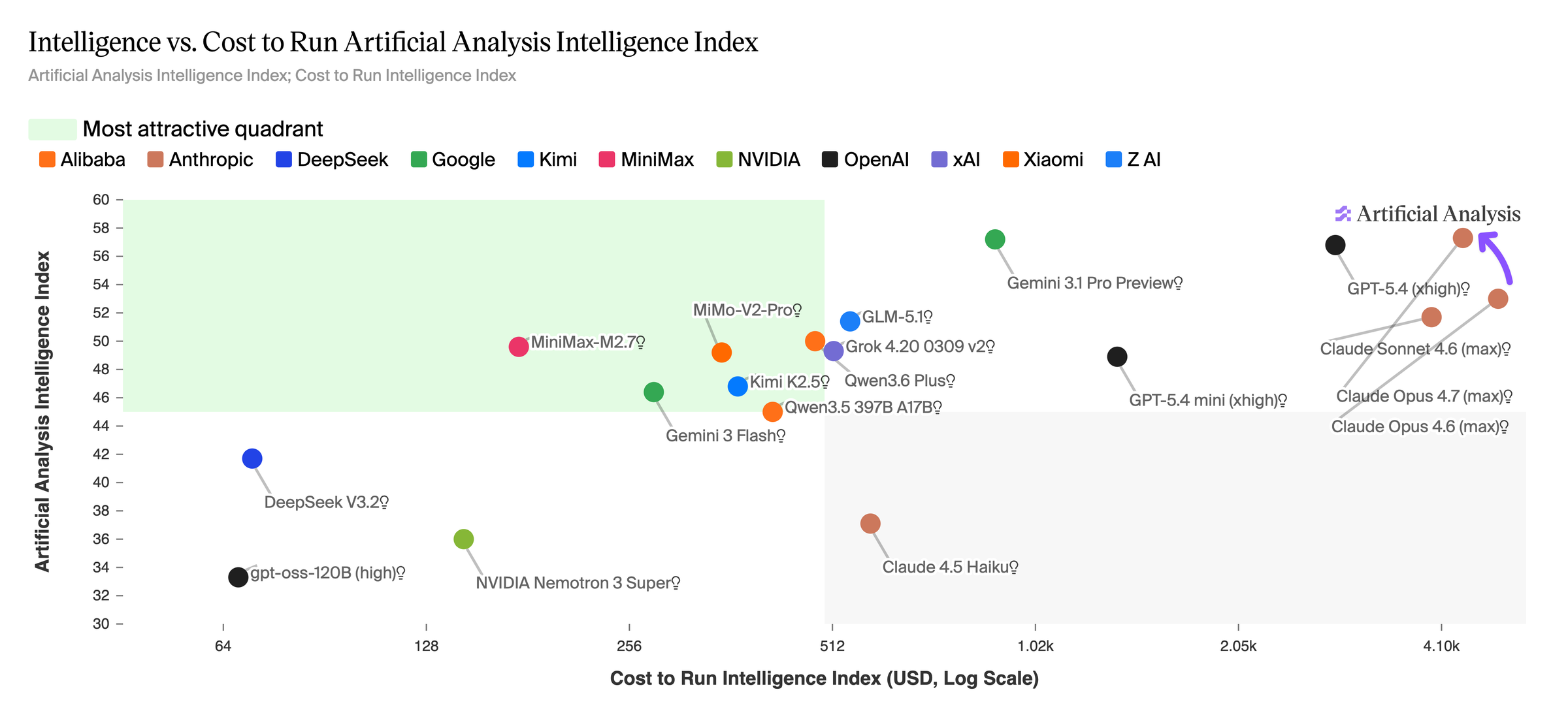
단, Artificial Analysis 자체 측정에서 Intelligence Index 실행 비용은 오히려 낮게 나왔다. Opus 4.7 ≈ $4,406 < Opus 4.6 ≈ $4,970로, 더 높은 점수를 내면서 출력 토큰을 덜 썼다.
tokenizer가 바뀌어서 같은 출력이 더 비싸 보일 수 있지만, 더 효율적인 처리 덕에 실제 쓰는 토큰의 절대량이 오히려 줄어들 수도 있다. 최종 비용은 workload, effort level, 이미지 사용량, 캐시 사용 여부에 따라 갈린다.
3. 마이그레이션 리스크
Opus 4.7은 이전보다 지시를 문자 그대로 따른다. 잘 만든 프롬프트에서는 장점이지만, 기존 프롬프트가 모델의 관대한 해석에 기대고 있었다면 결과가 달라질 수 있다.
| 항목 | 변화 |
|---|---|
| reasoning 방식 | extended thinking 제거 → adaptive thinking 중심 |
| effort 단계 | low / medium / high / xhigh / max |
| sampling | temperature, top_p, top_k 비기본값 사용 불가 |
| tokenizer | 같은 입력이 최대 약 1.35배 토큰으로 잡힐 수 있음 |
| 이미지 | 고해상도 이미지는 토큰 비용 증가 가능 |
| 프롬프트 해석 | 예전보다 문자 그대로 해석 |
production에서는 모델 ID만 바꾸지 말고, 대표 작업에 대한 regression eval을 먼저 돌리는 편이 맞다.
실전 사용 가이드
기대치를 올려도 되는 작업
| 작업 | 근거 |
|---|---|
| 큰 코드베이스 버그 수정 | SWE-bench Pro, SWE-bench Verified 상승 |
| Claude Code 장기 세션 | tool use, Terminal-Bench, xhigh effort와 연결 |
| 코드 리뷰·리팩터링 | 엄격한 지시 이행과 자기 검증 경향 |
| 화면 기반 자동화 | 고해상도 비전, OSWorld/CharXiv 상승 |
| 금융·법률·업무 문서 분석 | GDPval-AA, Finance Agent 강세 |
| 불확실성 관리 | AA-Omniscience에서 hallucination 감소 |
기대치를 낮춰야 할 작업
| 작업 | 이유 |
|---|---|
| 순수 웹 리서치 에이전트 | BrowseComp에서 Opus 4.6보다 하락 |
| 최저 비용 대량 처리 | Opus 라인 자체가 비싸고 effort에 따라 증가 |
| 기존 프롬프트 무수정 전환 | 문자 그대로 따르는 성향 탓에 결과 변화 가능 |
| 보안 연구·침투 테스트 | 고위험 사이버 요청 safeguard와 별도 verification program |
결론
Claude Opus 4.7은 Anthropic이 어디에 집중하는지를 보여주는 모델이다. 예쁘게 답하는 챗봇보다, 코드를 고치고·도구를 쓰고·긴 작업을 끝까지 가져가고·모르면 멈추는 업무형 에이전트 쪽에 무게가 실려 있다.
다만 “최강 모델 하나로 통일”이라고 말하기엔 조심해야 한다. Artificial Analysis 기준으로는 GPT-5.4, Gemini 3.1 Pro와 사실상 공동 1위 그룹이고, 웹 리서치처럼 오히려 후퇴한 영역도 있다.
| 상황 | 권장 |
|---|---|
| 복잡한 코딩·업무 위임·시각 자료 분석 | Opus 4.7 1순위 후보 |
| 순수 웹 리서치·비용 민감 대량 처리 | 다른 모델과 반드시 비교 |
빠르면 오늘 밤 GPT-5.5가 공개될 예정이다. 5.5가 나오면 이 순위는 곧바로 뒤집힐 가능성이 농후하다.
참고 자료
공유하기
X LinkedIn'AI' 카테고리의 다른 글




댓글남기기