ChatGPT Images 2.0 출시 - 이미지 생성조차 1위를 차지한 OpenAI
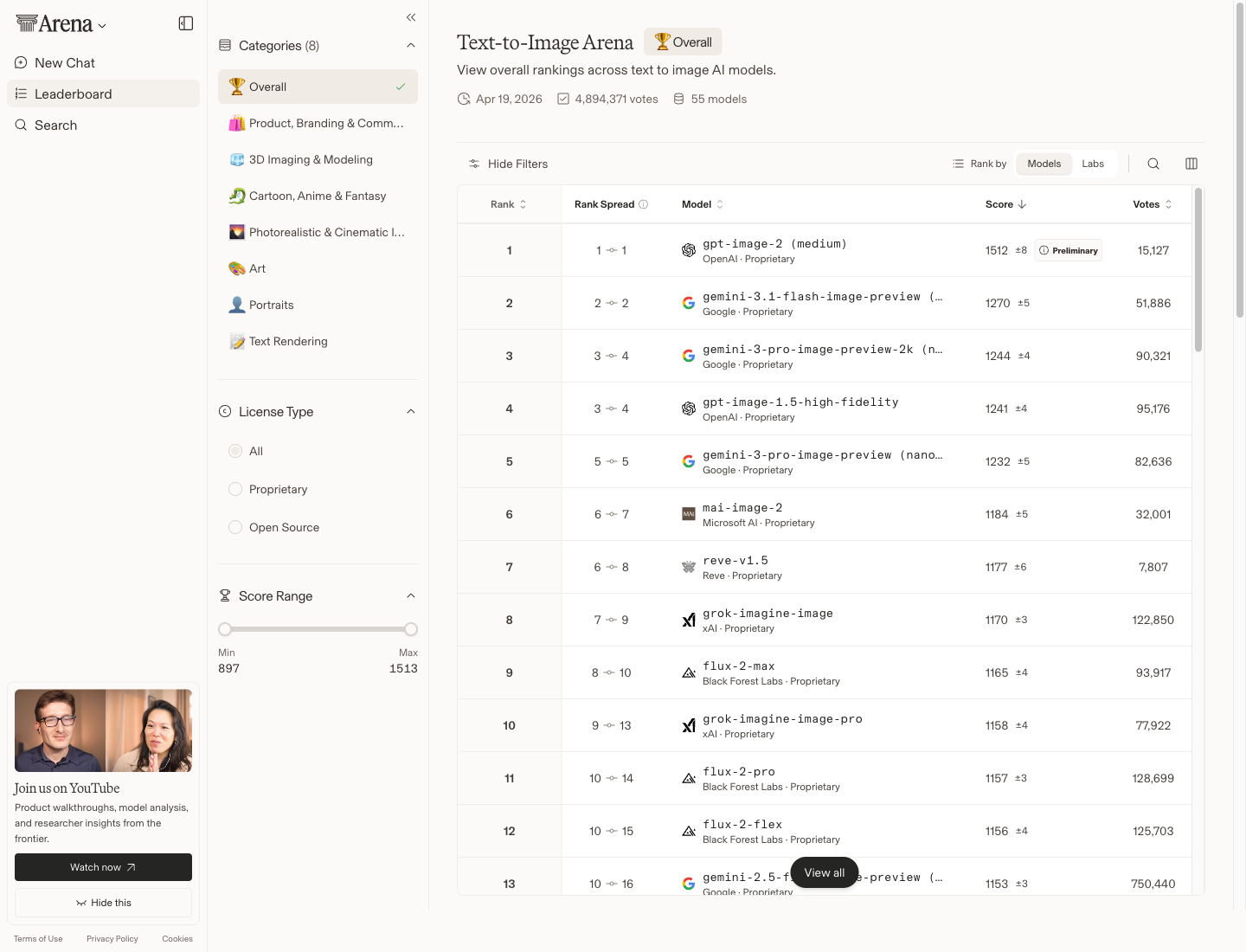
OpenAI가 ChatGPT Images 2.0(모델 ID gpt-image-2)을 공개했다. 이미지 생성의 약점이던 텍스트·다국어·일관성을 크게 끌어올리고, 대화형 편집과 프롬프트 재작성까지 하나의 흐름으로 묶은 OpenAI의 새 이미지 생성 모델이다.

OpenAI가 ChatGPT Images 2.0(모델 ID gpt-image-2)을 공개했다. 이미지 생성의 약점이던 텍스트·다국어·일관성을 크게 끌어올리고, 대화형 편집과 프롬프트 재작성까지 하나의 흐름으로 묶은 OpenAI의 새 이미지 생성 모델이다.
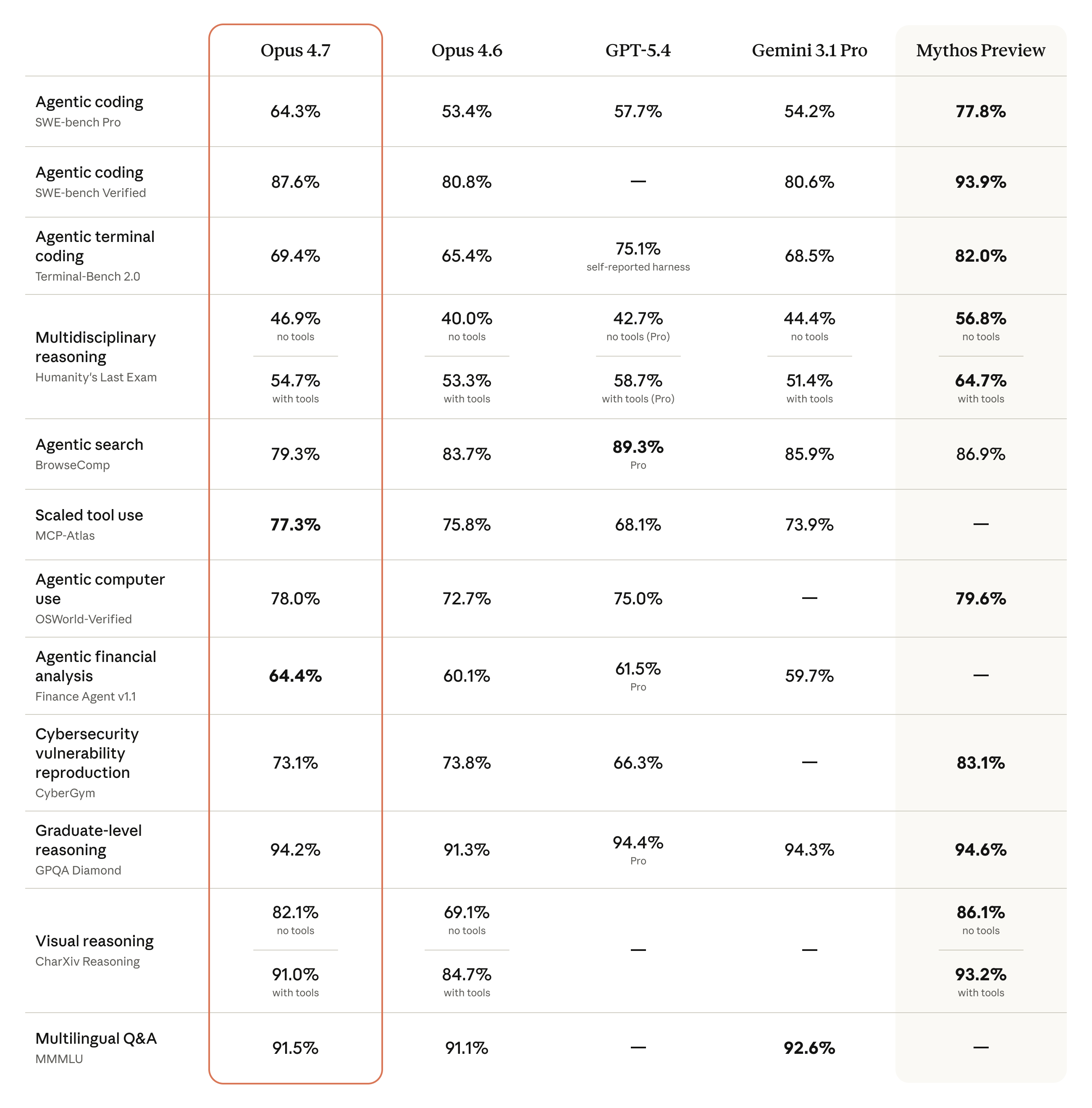
Anthropic이 Claude Opus 4.7을 공개했다. 답변 품질을 조금 올린 챗봇 업데이트가 아니라, 코딩 에이전트, 장기 업무 위임, 고해상도 비전, 엄격한 지시 이행을 축으로 개선된 Anthropic의 최상위 공개 모델이다.
처음에는 나도 Obsidian용 기본 스킬 몇 개만 있으면 AI 비서가 금방 돌아갈 줄 알았다. markdown을 읽고, .base를 만지고, CLI로 앱까지 건드릴 수 있으니 얼핏 보면 충분해 보이기 때문이다. 그런데 며칠만 써 보면 금방 차이가 드러난다. 파일을 다룰 수 있는 ...
VS Code 위에서도 개인 비서용 환경을 만들 수는 있다. 문제는 일정 화면, 칸반 보드, 템플릿, 첨부 정리까지 붙이기 시작하면 다시 도구를 만드는 일로 돌아가기 쉽다는 점이다. 내가 Obsidian을 계속 쓰는 이유는 markdown 파일 기반이라서만이 아니라, 이미 잘 만들...
Obsidian 구조를 잘 만들어도 오래 가는 건 별개다. 시간이 지나면 AGENTS.md는 두꺼워지고, 장기 메모리와 임시 판단이 섞이고, 새 규칙이 생길 때마다 어디를 고쳐야 할지 헷갈리기 시작한다. 1편과 2편이 왜 이 시스템을 다시 시도하게 됐는지와 구조를 어떻게 나눴는지를...
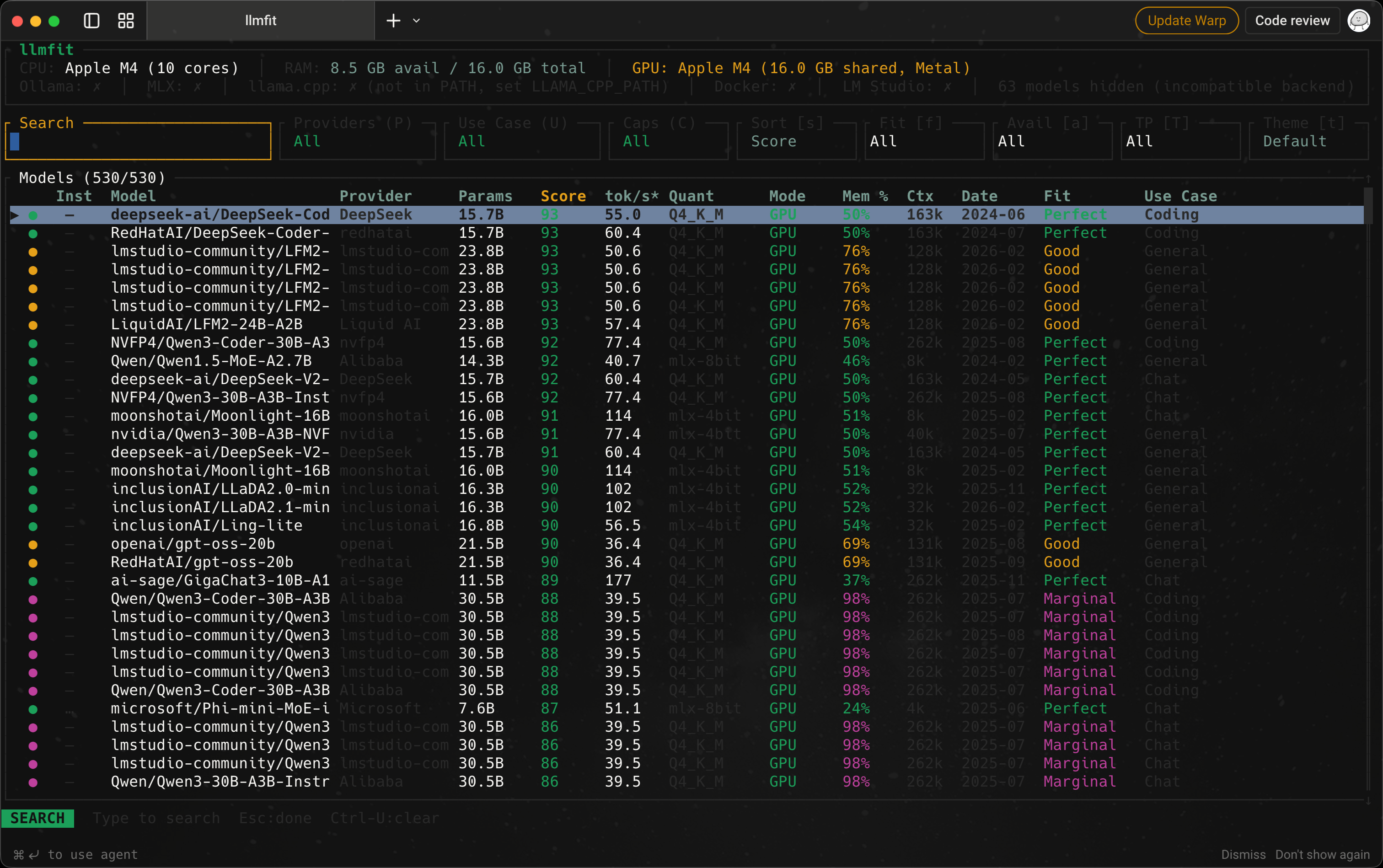
로컬 LLM을 써보려 하면 가장 먼저 부딪히는 문제는 “어떤 모델이 제일 좋나?”보다 “내 맥에서 어떤 모델이 현실적으로 돌아가나?”다. llmfit는 이 질문에 먼저 답해주는 도구다. 모델을 직접 실행하는 프로그램은 아니지만, 내 하드웨어에 맞는 후보를 먼저 좁혀준다는 점에서 로...
이 시리즈의 1편에서는 일일기록 -> AI 후처리 -> Day Planner 흐름을 보여줬다. 그런데 그 자동화가 한두 번 반짝하고 끝나지 않으려면, 그 뒤에서 에이전트가 길을 잃지 않는 구조가 먼저 있어야 한다.
Obsidian을 오래 못 쓰는 이유는 기능이 부족해서가 아니다. 구조를 제대로 잡는 순간, 메모보다 유지 보수가 더 커지기 때문이다.
macOS용 Codex 데스크톱 앱을 쓰다 보면 창 가로폭이 어느 지점 아래로 더 줄어들지 않는 경우가 있다. 사이드바를 닫아도 여전히 넓게 고정돼 있다면, 단순한 레이아웃 문제가 아니라 내부 상태값이 꼬인 경우일 수 있다. 내가 겪은 경우에는 창이 정확히 1200px 근처 아래로...
AI가 손쉽게 브라우저를 조작할 수 있도록 만들어주는 Playwright를 사용해보자. GPT 5.4에서 playwright-interactive 스킬 기반으로 웹 앱/게임을 만들었다고 하는데, 이 Playwright가 뭘까?
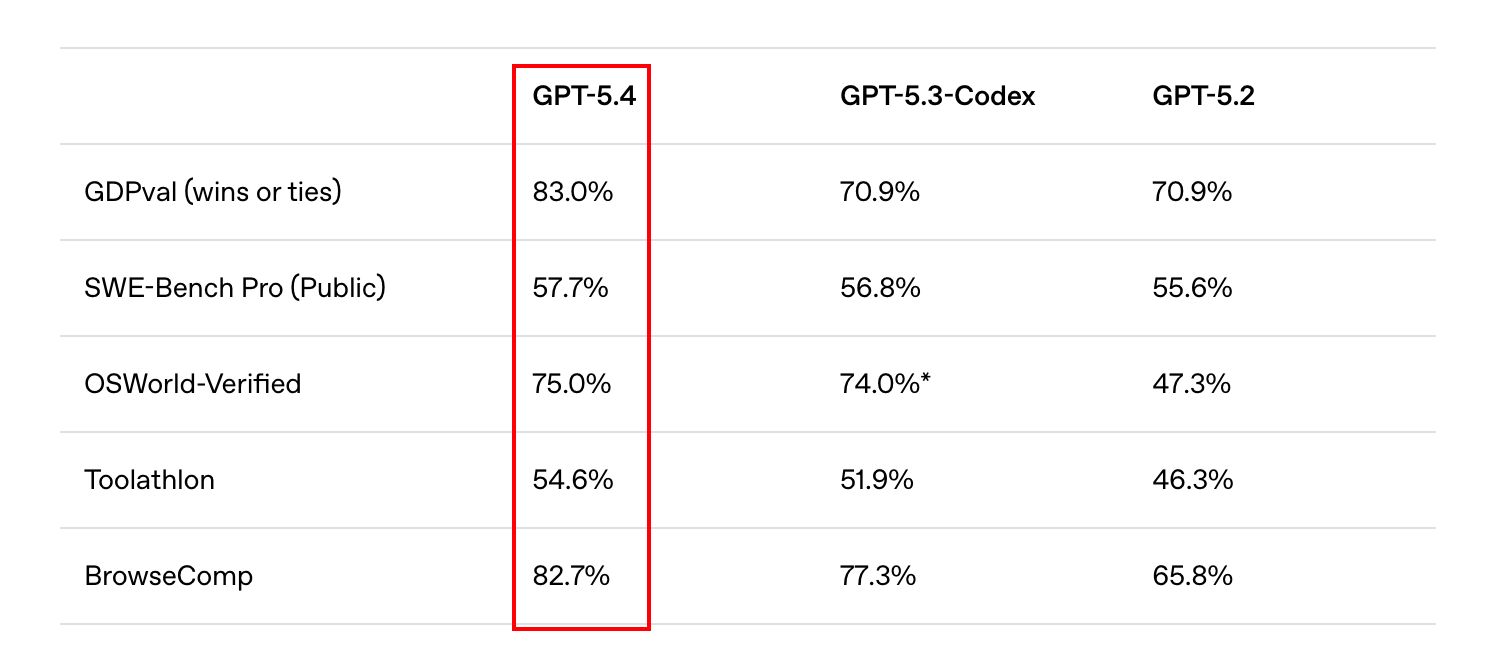
OpenAI가 GPT 5.4를 출시했다. Tool Calling, Computer Use 등 Agent 성능이 크게 향상되었으며, 주요 벤치마크에서 타 모델들을 확연히 이기며 명실상부한 SOTA에 등극했다.
2월에 Google은 Gemini의 창작 기능을 음악과 이미지 양쪽으로 대폭 확장했다. Lyria 3로 음악 생성을, Nano Banana 2로 이미지 생성을 한 단계 끌어올렸고, 관련 내용을 이 글로 통합 정리했다.