내 맥에 맞는 로컬 LLM 찾기 - llmfit로 추천 모델 고르는 법
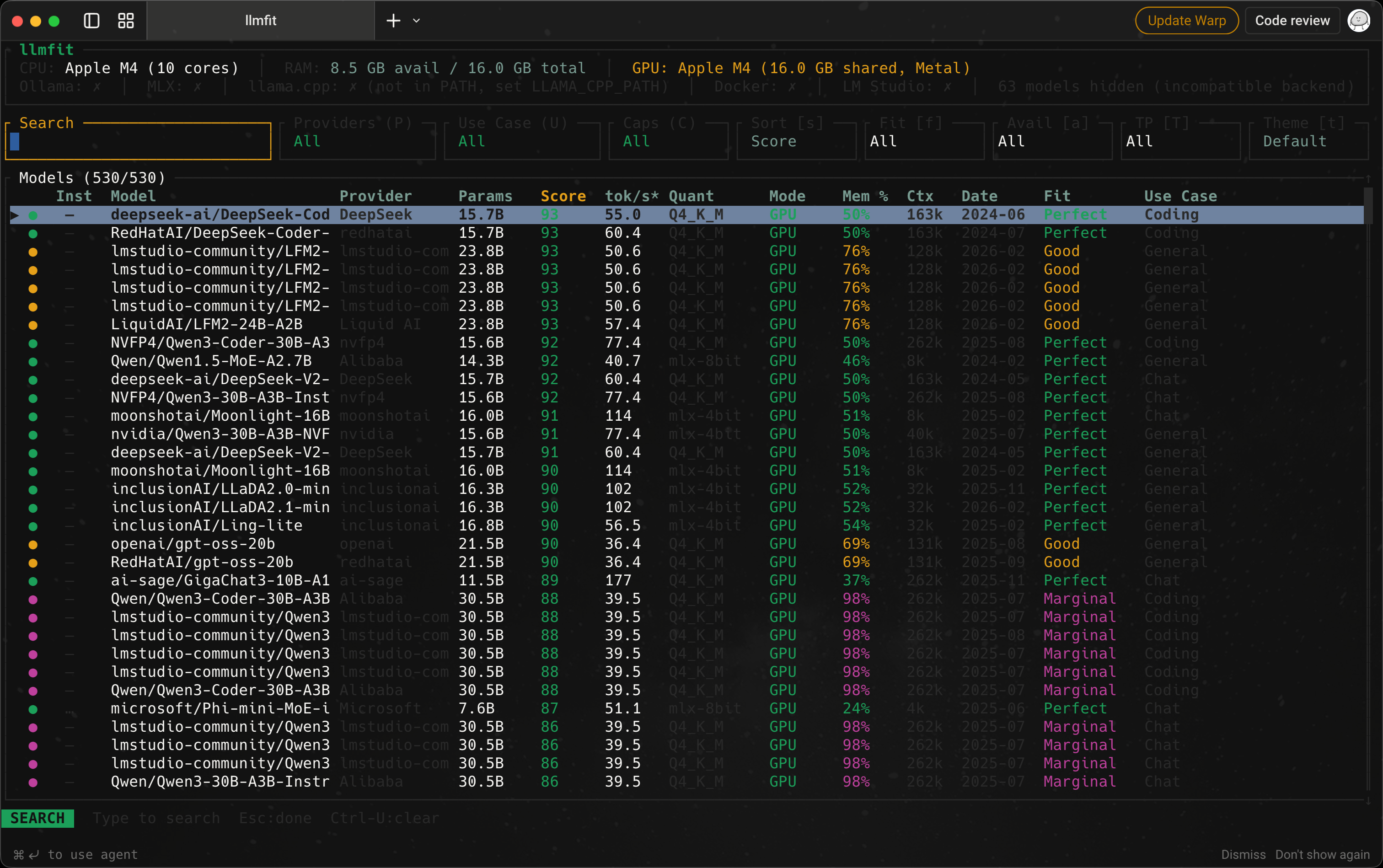
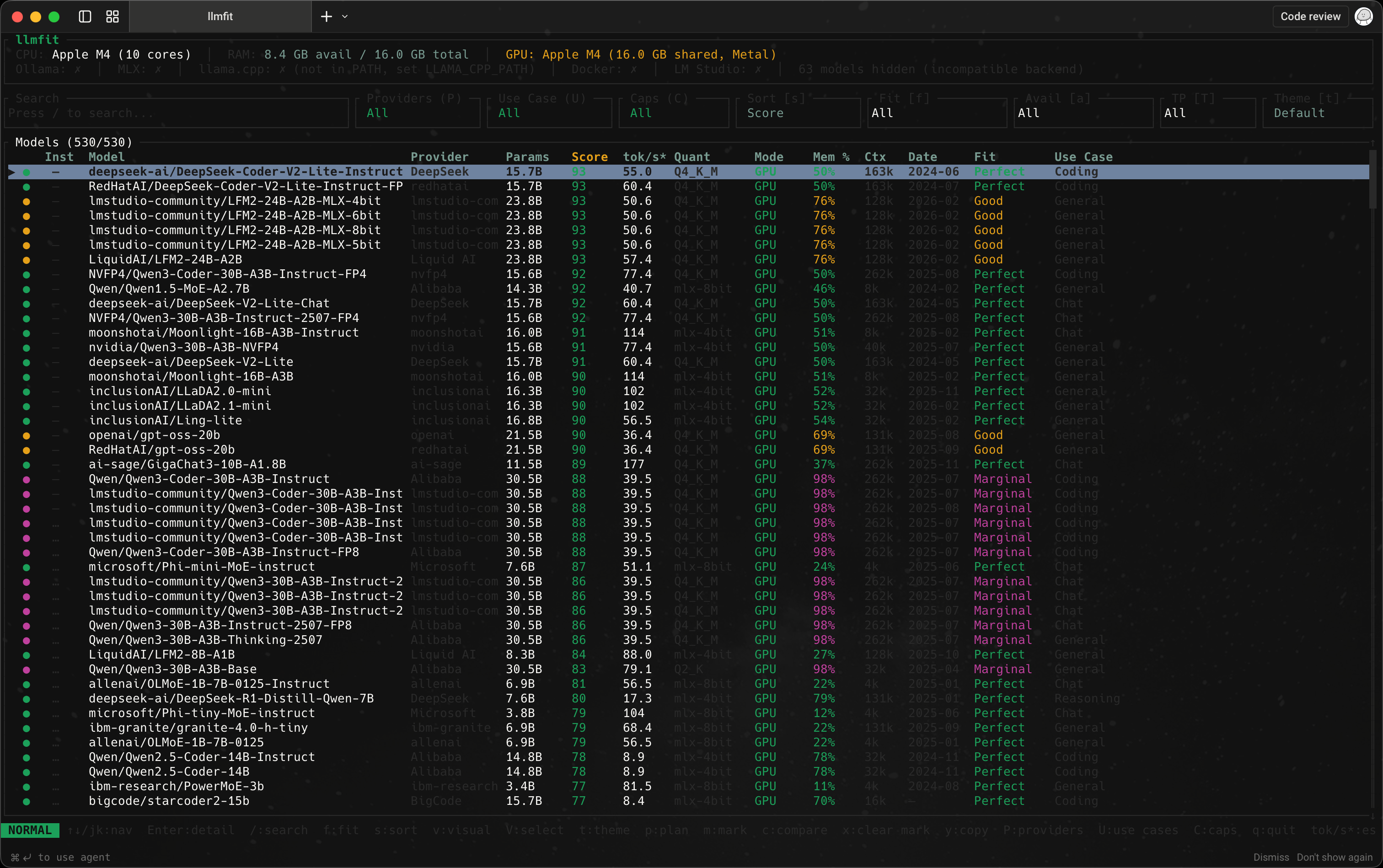
로컬 LLM을 써보려 하면 가장 먼저 부딪히는 문제는 “어떤 모델이 제일 좋나?”보다 “내 맥에서 어떤 모델이 현실적으로 돌아가나?”다. llmfit는 이 질문에 먼저 답해주는 도구다. 모델을 직접 실행하는 프로그램은 아니지만, 내 하드웨어에 맞는 후보를 먼저 좁혀준다는 점에서 로컬 LLM 입문 단계에서 꽤 유용하다.

llmfit Documentation - llmfit
GitHub - AlexsJones/llmfit: Hundreds of models & providers. One command to find what runs on your hardware.
llmfit이란
llmfit는 모델 실행기라기보다 하드웨어 적합도 기반 추천 도구에 가깝다. 여러 모델을 무작정 내려받아 시험해보기 전에, 현재 기기에서 가능성이 높은 후보를 먼저 정리해준다는 점이 핵심이다.
| 항목 | 내용 |
|---|---|
| 역할 | 현재 하드웨어에서 현실적으로 돌릴 수 있는 로컬 LLM 후보 추천 |
| 입력 | CPU, RAM, GPU와 용도별 기준값 |
| 출력 | Fit, Score, tok/s, Mem %, Mode, Quant 등이 포함된 추천 목록 |
| 잘하는 일 | 후보군 좁히기, 비교 기준 제공, 다운로드 전 사전 판단 |
| 하지 않는 일 | 모델 자체 실행, 채팅 UI 제공, 추론 서버 대체 |
llmfit의 강점은 모델 자체의 절대 서열을 보여주는 데 있지 않다. 내 맥에서 어느 정도 여유로 돌아갈지, 어떤 용도에 더 맞는지까지 함께 보여주기 때문에 초기 선택 비용을 줄여준다. 특히 Ollama나 LM Studio에서 어떤 모델을 먼저 받아볼지 고민할 때 유용하다.
설치와 실행
macOS에서는 Homebrew 설치가 가장 단순하다. 설치 후 llmfit를 실행하면 바로 추천 모델 대시보드를 볼 수 있다.
| 단계 | 내용 |
|---|---|
| 1 | Homebrew로 llmfit 설치 |
| 2 | 터미널에서 llmfit 실행 |
| 3 | 대시보드에서 현재 하드웨어 기준 추천 후보 확인 |
brew install llmfit
llmfit
추천 모델 판단 기준
llmfit의 핵심은 컬럼을 전부 외우는 데 있지 않다. 실제로는 몇 개 지표만 잘 읽어도 추천 모델을 꽤 빠르게 좁힐 수 있다.
| 지표 | 의미 | 추천 모델 고를 때의 쓰임 |
|---|---|---|
Fit |
현재 하드웨어에서 무리 없이 도는 정도 | 아예 무리인 후보를 가장 먼저 걸러낸다 |
Score |
현재 환경 기준 종합 추천 점수 | 절대 성능이 아니라, 내 환경에서 균형이 좋은 후보를 찾는다 |
tok/s* |
예상 토큰 처리 속도 | 체감 응답 속도를 가늠한다 |
Mem % |
가용 메모리 대비 사용 비율 | 메모리 여유가 충분한지 확인한다 |
Mode |
GPU, CPU+GPU, CPU 등 실행 경로 |
어떤 자원을 주로 쓰는지 파악한다 |
Use Case |
General, Coding, Reasoning 같은 용도 분류 |
목적에 맞는 모델인지 확인한다 |
Model / Params |
모델 이름과 파라미터 규모 | 비슷한 용도 후보들 사이에서 크기 차이를 본다 |
Quant |
현재 환경 기준 양자화 표기 | 중요하지만 초반에는 보조 지표로만 보고, 자세한 해석은 번외에서 본다 |
추천 모델 판단 순서
추천 모델은 될까를 먼저 보고, 그다음 빠를까와 버틸까를 확인하는 순서가 안정적이다.
| 순서 | 확인 항목 | 보는 이유 |
|---|---|---|
| 1 | Fit |
아예 무리인 모델을 먼저 걸러낼 수 있다 |
| 2 | Score |
현재 하드웨어와 용도 기준의 종합 우선순위를 빠르게 볼 수 있다 |
| 3 | tok/s* |
체감 속도를 가늠할 수 있다 |
| 4 | Mem % |
메모리 여유가 부족한 후보를 피할 수 있다 |
| 5 | Mode |
GPU 활용 여부와 실행 성격을 이해할 수 있다 |
| 6 | Model / Params / Use Case |
최종적으로 모델 성격과 쓰임새를 비교할 수 있다 |
Score는 절대 성능 점수라기보다 여러 요소를 합친 종합 추천 점수다. 그래서 본문에서는 Score를 “내 환경에서 균형이 좋은 후보를 찾는 지표” 정도로 읽고, 실제 계산식과 하위 점수 의미는 맨 뒤 번외에서 함께 보는 편이 흐름상 더 자연스럽다.
활용 흐름
llmfit는 모델을 직접 실행하는 도구라기보다, Ollama나 LM Studio에서 어떤 모델을 먼저 받아볼지 정하는 전 단계 도구로 쓰는 편이 가장 효율적이다.
| 상황 | llmfit에서 볼 것 | 다음 행동 |
|---|---|---|
| 첫 후보를 고를 때 | Fit, Score |
상위 후보 몇 개만 추려서 우선 다운로드 |
| 속도가 중요한 채팅용 모델을 찾을 때 | tok/s*, Chat 기준 Score |
체감 속도가 높은 후보부터 테스트 |
| 코딩용 모델을 찾을 때 | Coding 기준 Score, Context |
긴 문맥과 품질 균형이 좋은 후보 확인 |
| 메모리가 빠듯한 맥에서 고를 때 | Mem %, Fit, Mode |
빡빡한 후보를 피하고 여유 있는 설정을 우선 검토 |
| 실행 도구와 연결할 때 | Model, Quant, Use Case |
Ollama, LM Studio에서 동일 계열 모델 우선 시도 |
결국 핵심은 무작정 모델을 받아보는 대신, 내 컴퓨터에서 구동 가능한 후보 중 우선순위가 높은 모델부터 좁혀보는 데 있다. llmfit는 이 과정에서 “될 모델”과 “당장 시도해볼 모델”을 분리해주는 필터 역할을 한다.
번외: 세부 지표 해설
본문에서는 Score를 해석하는 데 집중했고, 여기서는 계산 방식과 세부 표기를 따로 정리한다. 이런 정보는 유용하지만, 초반에 너무 먼저 들어가면 오히려 모델 선택 기준이 흐려질 수 있다.
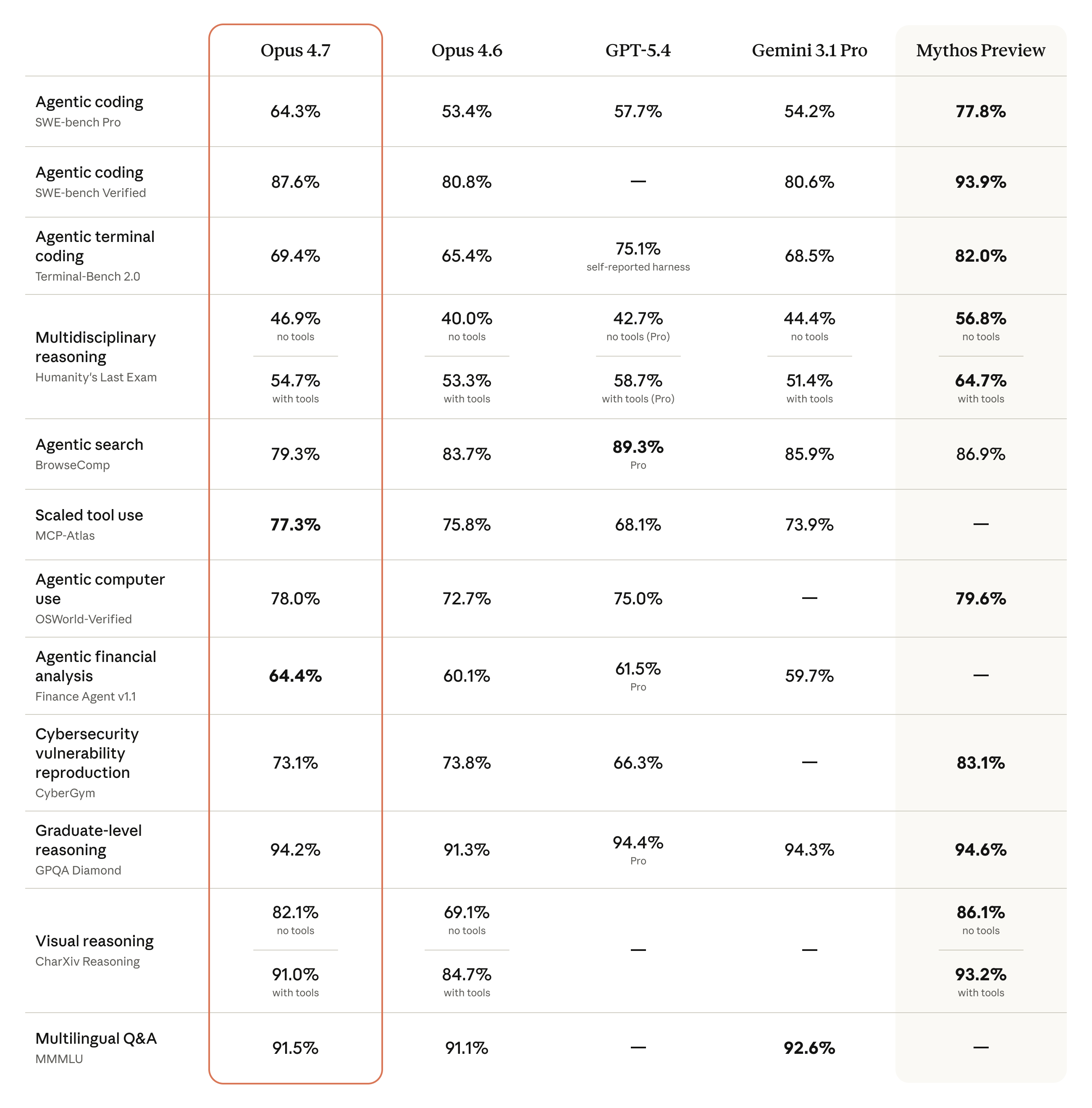
Score 계산 방식
Score는 아래 네 가지 하위 점수의 가중합이다. llmfit는 이 값을 소수점 한 자리까지 반올림해서 보여준다.
Score = Quality × wq + Speed × ws + Fit × wf + Context × wc
하위 점수 의미
본문에서 보던 Score는 결국 이 네 가지 질문을 한 번에 요약한 값이다.
| 하위 점수 | 무슨 질문에 답하는가 | 실전에서 볼 포인트 |
|---|---|---|
Speed |
얼마나 빠른가 | 채팅처럼 반응 속도가 중요한 경우 중요하다 |
Fit |
내 하드웨어에 얼마나 맞는가 | 메모리 제약이 큰 환경에서는 가장 먼저 본다 |
Context |
필요한 문맥 길이를 감당하는가 | 코딩이나 긴 추론 작업에서 더 중요하다 |
Quality |
모델 자체 잠재력이 어느 정도인가 | 큰 모델이 유리할 수 있지만, 실제 추천은 다른 지표와 함께 봐야 한다 |
| 하위 점수 | 계산 기준 | 해석 포인트 |
|---|---|---|
Speed |
estimated_tps / target_tps × 100을 0~100으로 제한 |
용도별 목표 tok/s에 얼마나 가까운지 본다 |
Fit |
required / available 비율 기반 |
메모리 사용이 적절한 구간에 들어오는지 본다 |
Context |
목표 컨텍스트 길이 대비 충족 정도 | 필요한 문맥 길이를 감당하는지를 본다 |
Quality |
파라미터 수 기반 점수 + 모델 계열 가산점 - 양자화 패널티 + 용도별 가산점 | 모델 자체 잠재 성능을 추정한다 |
세부 계산 기준
Speed: 체감 응답 속도와 가장 직접적으로 연결된다.Fit: 메모리 적합도를 가장 직접적으로 보여주는 지표다.Context: 긴 문맥을 얼마나 감당할 수 있는지를 뜻한다.Quality: 모델 자체 성능 기대치를 추정하는 축이다.
Fit은 50~80% 사용 구간을 가장 좋은 영역으로 보고 100점을 준다. Context는 목표 길이를 넘기면 100점, 절반 이상이면 70점, 그보다 작으면 30점으로 잡힌다. 이런 세부 규칙까지 보면 Score가 단순한 인기 순위가 아니라 현재 환경에 맞춘 계산 결과라는 점이 더 분명해진다.
Use Case별 가중치
용도에 따라 무엇을 더 중요하게 볼지가 다르기 때문에, 같은 모델이라도 Use Case가 바뀌면 점수 해석도 달라진다.
| Use Case | Quality | Speed | Fit | Context |
|---|---|---|---|---|
General |
0.45 | 0.30 | 0.15 | 0.10 |
Coding |
0.50 | 0.20 | 0.15 | 0.15 |
Reasoning |
0.55 | 0.15 | 0.15 | 0.15 |
Chat |
0.40 | 0.35 | 0.15 | 0.10 |
Multimodal |
0.50 | 0.20 | 0.15 | 0.15 |
Embedding |
0.30 | 0.40 | 0.20 | 0.10 |
Coding과 Reasoning은 Quality 비중이 높고, Chat은 Speed 쪽 비중이 더 높다. 그래서 채팅용 모델과 코딩용 모델의 추천 순위가 다르게 나오는 것이 자연스럽다.
Quant 표기 해설
Quant가 헷갈리는 이유는 같은 모델이라도 어떤 런타임을 기준으로 보느냐에 따라 표기가 달라질 수 있기 때문이다. Apple Silicon에서는 MLX 쪽 표기가 자주 보이고, GGUF 계열에서는 Q4_K_M, Q5_K_M, Q8_0 같은 이름이 많이 보인다.
| 표기 | 런타임 | 의미 | 실전 해석 |
|---|---|---|---|
mlx-8bit |
MLX |
Apple Silicon용 8비트급 포맷 | 품질 손실은 적지만 메모리를 더 쓴다 |
mlx-4bit |
MLX |
Apple Silicon용 4비트급 포맷 | 메모리 절약 폭이 크고 Apple Silicon에서 자주 본다 |
Q8_0 |
GGUF / llama.cpp |
거의 8비트급에 가까운 양자화 | 품질 지향이지만 더 무겁다 |
Q6_K |
GGUF / llama.cpp |
품질 쪽으로 기운 K-quant |
Q4_K_M보다 무겁지만 손실이 적은 편이다 |
Q5_K_M |
GGUF / llama.cpp |
절충형 5비트급 K-quant |
여유가 있으면 Q4_K_M보다 나은 선택이 될 수 있다 |
Q4_K_M |
GGUF / llama.cpp |
대표적인 4비트급 절충안 | 로컬 LLM에서 가장 자주 보는 균형형 선택지다 |
Q3_K_M |
GGUF / llama.cpp |
강하게 압축한 3비트급 | 메모리는 줄지만 품질 손실 가능성이 커진다 |
Q2_K |
GGUF / llama.cpp |
매우 공격적인 압축 | 메모리가 매우 부족할 때 맞추는 쪽에 가깝다 |
AWQ-4bit |
CUDA/NVIDIA 계열 | 사전 양자화 4비트 포맷 | Apple Silicon 주력 선택지라고 보기는 어렵다 |
GPTQ-Int4 |
CUDA/NVIDIA 계열 | 4비트 정수 양자화 포맷 | 주로 NVIDIA 생태계에서 본다 |
F16 / BF16 |
여러 런타임 | 원본에 가까운 부동소수점 weight | 품질 손실은 적지만 크고 무겁다 |
Q4_K_M 같은 이름은 “대략 4비트급 K-quant 계열의 M variant” 정도로 읽으면 충분하다. 중요한 건 표기 하나를 외우는 것보다, 현재 런타임과 하드웨어 기준으로 어떤 절충을 의미하는지 이해하는 것이다.
Apple Silicon 기준 해석
Apple Silicon에서는 llmfit가 MLX 쪽을 우선 보기 때문에, GGUF 계열 모델도 mlx-*처럼 보일 수 있다. 그래서 Quant는 혼자 보기보다 Fit, Score, Mode와 함께 읽는 편이 맞다.
| 상황 | 우선 해석 | 실전 판단 |
|---|---|---|
mlx-4bit가 보일 때 |
Apple Silicon에 맞춘 경량 선택지일 가능성이 크다 | 메모리와 속도를 먼저 확인한다 |
mlx-8bit가 보일 때 |
품질은 유리하지만 더 무거울 수 있다 | Mem %가 높다면 부담이 커질 수 있다 |
Q4_K_M나 Q5_K_M가 보일 때 |
GGUF 계열의 절충형 선택지다 | 실행 런타임과 메모리 여유를 함께 본다 |
| 낮은 비트 양자화가 보일 때 | 더 작은 하드웨어에 맞추는 방향일 수 있다 | 품질 손실 가능성을 감안해야 한다 |
결국 Quant는 고정된 절대값이 아니라 현재 하드웨어와 런타임 기준으로 읽어야 하는 값이다. 아주 단순하게 보면, 더 높은 비트와 덜 공격적인 양자화는 품질 쪽에 유리하고, 더 낮은 비트와 더 강한 압축은 메모리 쪽에 유리하지만 품질 손실 가능성도 커진다.
마무리
llmfit는 모델을 직접 돌리는 프로그램이라기보다, 내 맥에서 먼저 시도할 만한 로컬 LLM 후보를 좁혀주는 도구다. Fit, Score, tok/s*, Mem %를 먼저 읽고 후보를 줄인 뒤, 필요할 때만 번외의 세부 지표까지 확인하면 로컬 LLM 선택 과정의 시행착오를 꽤 줄일 수 있다.
공유하기
X LinkedIn'AI' 카테고리의 다른 글



댓글남기기