
[DLS]Sequence Models(1)
Andrew Ng 교수님의 Coursera - Deep Learning Specialization 마지막 강의입니다. 이번에는 RNN을 베이스로 Language Model, LSTM, GRU 등을 다룹니다.
Vocabulary(Dictionary)
각 단어를 숫자로 변환하기 위한 사전이다. 만개의 단어가 존재하는 사전을 사용한다면 각 단어를 1 ~ 10,000으로 분배하고 사용할 때는 주로 one hot encoding을 적용해 각 단어를 (10,000 x 1) 벡터로 만들어 사용한다.
보통 30,000 개 이상의 사전을 사용한다.
대형 모델은 백만이 넘기도 한다.
RNN(Recurrent Neural Networks)
데이터를 왼쪽에서 오른쪽으로 하나씩 확인하며 이전 단어의 activation을 가져와서 계산에 사용한다. 이과정에서 파라미터는 동일하게 사용되어진다.
하지만 뒤의 단어를 보지않고 오직 앞에 만 있는 단어만 보는 단점이 존재한다. Bidrectional RNN(BRNN)이 이 문제를 해결할 수 있다.
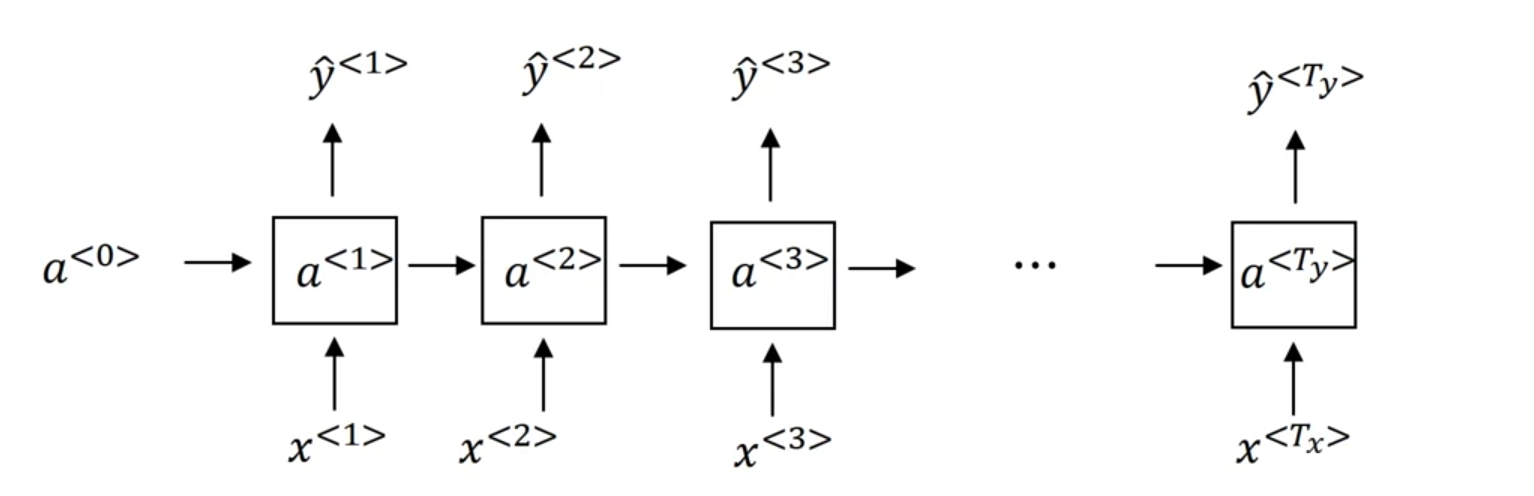
- $W_{ax}$는 $a$를 도출해내기 위한 식에서 $x$에 곱해지는 $W$라는 표기이다.
- $W_{ax}$와 $W_{aa}$를 concat해서 하나의 matrix로 만들어 간략화하였다.
- $[a^{\langle t - 1\rangle}, x^{\langle t \rangle}]$의 경우 두 벡터를 상하로 쌓은 것이다.
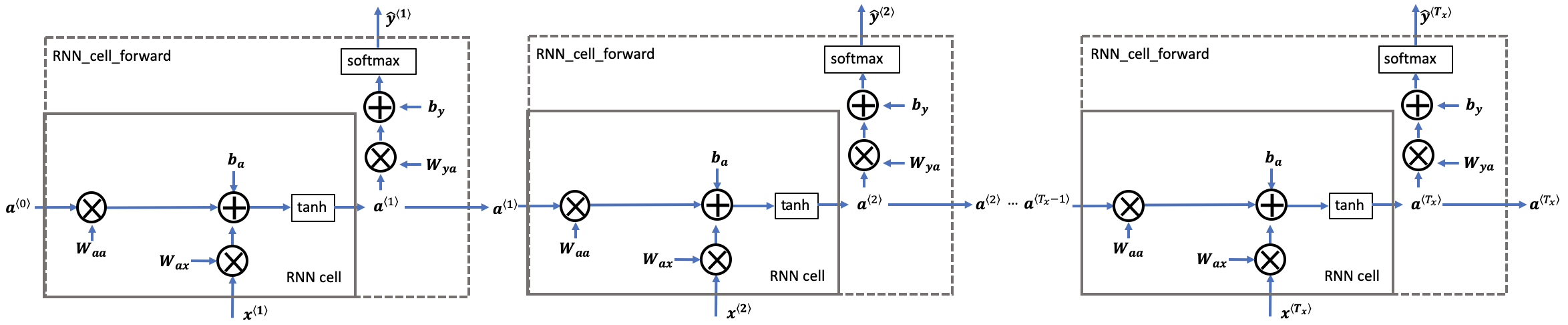
tanh 함수를 activation으로 주로 사용한다.
Backpropagation through time
RNN에서 역전파는 시간을 거슬러 올라가며 전파된다. BTT의 약자로 불리기도 한다.
\[\begin{align} \displaystyle a^{\langle t \rangle} &= \tanh(W_{ax} x^{\langle t \rangle} + W_{aa} a^{\langle t-1 \rangle} + b_{a})\tag{-} \\[8pt] \displaystyle \frac{\partial \tanh(x)} {\partial x} &= 1 - \tanh^2(x) \tag{-} \\[8pt] \displaystyle {dtanh} &= da_{next} * ( 1 - \tanh^2(W_{ax}x^{\langle t \rangle}+W_{aa} a^{\langle t-1 \rangle} + b_{a})) \tag{0} \\[8pt] \displaystyle {dW_{ax}} &= dtanh \cdot x^{\langle t \rangle T}\tag{1} \\[8pt] \displaystyle dW_{aa} &= dtanh \cdot a^{\langle t-1 \rangle T}\tag{2} \\[8pt] \displaystyle db_a& = \sum_{batch}dtanh\tag{3} \\[8pt] \displaystyle dx^{\langle t \rangle} &= { W_{ax}}^T \cdot dtanh\tag{4} \\[8pt] \displaystyle da_{prev} &= { W_{aa}}^T \cdot dtanh\tag{5} \end{align}\]또한, 각 단어를 이진 분류하는 모델의 경우 아래와 같은 손실함수로 정의할 수 있다.
\[L(\hat{y},y) = - \sum_{t=1}^{T_y}{y^{<t>} \cdot log\hat{y}^{<t>} + (1 - y^{<t>}) \cdot log(1 -\hat{y}^{<t>})}\]이 손실함수의 gradient에서부터 시간(t)을 하나씩 거슬러 오르며 parameter에 역전파가 일어난다.
RNN types
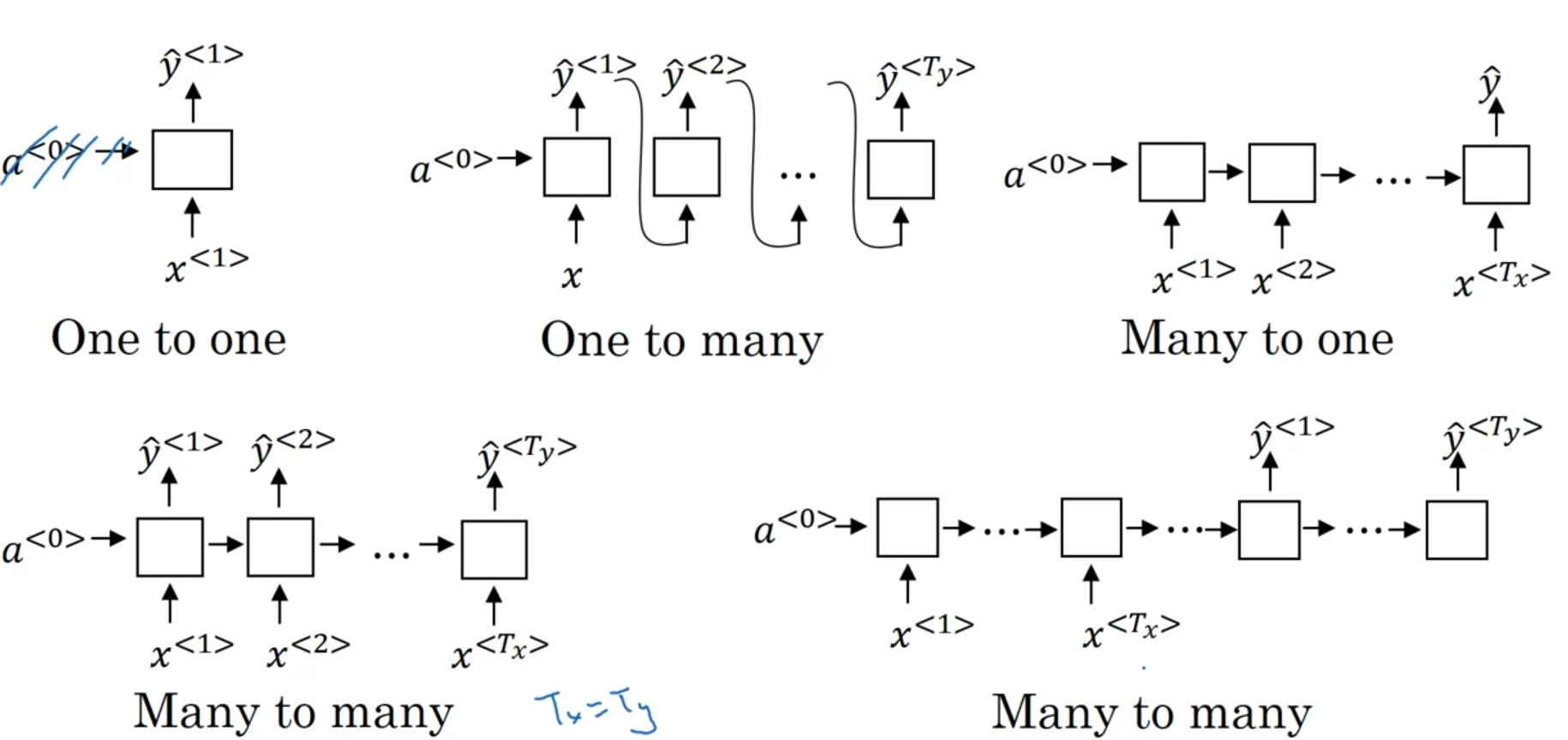
- one to one: 일반적인 NN과 같다.
- One to many: Generation(언어 모델 등)
- Many to one: 영화 리뷰글의 평점 분석
- Many to many
- $T_x = T_y$: 문장에서 인명 단어 분류
- $T_x \neq T_y$: Machine Translation(Encoder/Decoder)
Language Modelling
RNN을 사용하여 자연어를 생성하는 언어모델을 만들 수 있다.
Tokenize
말뭉치(Corpus), 즉 학습을 위한 자연어 데이터들을 각각 token으로 만들어야한다.
- 사전에 포함되는 단어 외에 특별한 토큰이 존재한다.
<EOS>: End Of Sentence 문장 종료 나타냄<UNK>: UNKown 사전에 없던 단어는 전부 모르는 토큰이라고 간주
- 10,000개 단어의 사전이라면 10,002개로 분류가 되는 것이다.
Training
훈련은 입력 데이터로 문장을 주며, 이전 단어까지 봤을 때 다음 단어를 예측하는 식으로 이루어진다.
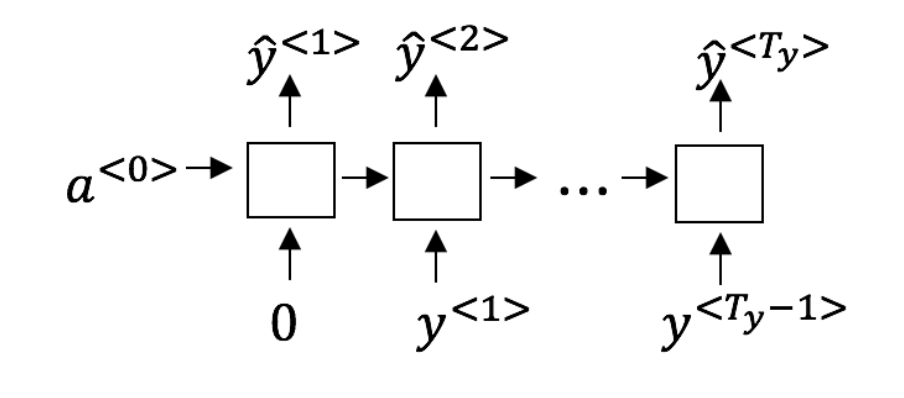
각 시간에서 이전 단어까지 입력으로 들어왔을 때 다음 단어의 확률을 평가한다.
Sampling
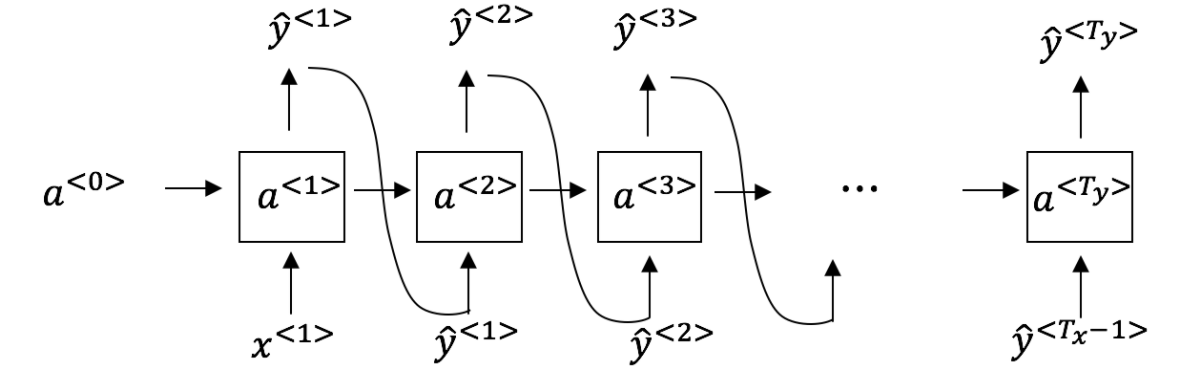
$\hat{y}^{\langle t \rangle}$의 softmax 확률 분포에서 랜덤하게 단어를 선택하고 이를 다음 입력으로 삼아 문장을 생성하게 된다.
<UNK>의 경우 다시 샘플링을 할 수 있으며 <EOS> 토큰이 출현할 때까지 생성하게 된다.
Vanishing gradients
하지만 Weight가 반복적으로 곱해지면서 최초의 입력값이 소멸하는 일이 발생하게 된다.
이를 위해 고안된 방법이 LSTM과 GRU 등으로 출력과 별개로 저장되어 다음 시퀀스로 전달하는 메모리가 존재한다.
Exploding gradients의 경우 발산하며 overflow가 일어나 NaN이 생기는데 이는 상한선을 둠으로써 쉽게 해결가능하다.
GRU(Gated Recurrent Unit)
메모리 셀 c 가 존재한다.
GRU의 경우 $a^{\langle t \rangle}$의 출력이 $c^{\langle t \rangle}$ 셀의 값이다.
\[\begin{aligned} \tilde{c}^{\langle t \rangle} &= \tanh(W_c[\Gamma_r * c^{\langle t-1 \rangle}, x^{\langle t \rangle}] + b_c) \\ \Gamma_u &= \sigma(W_u[c^{\langle t-1 \rangle}, x^{\langle t \rangle}] + b_u) \\ \Gamma_r &= \sigma(W_r[c^{\langle t-1 \rangle}, x^{\langle t \rangle}] + b_r) \\ c^{\langle t \rangle} &= \Gamma_u * \tilde{c}^{\langle t \rangle} + (1 - \Gamma_u) * c^{\langle t-1 \rangle} \\ a^{\langle t \rangle} &= c^{\langle t \rangle} \end{aligned}\]- $\tilde{c}$: 이번 출력의 후보값
Update Gate
\[\Gamma_u = \sigma(W_u[c^{\langle t-1 \rangle}, x^{\langle t \rangle}] + b_u)\]$\Gamma_u$는 시그모이드를 적용하여 0 ~ 1 사이 값을 가지게 된다. RNN과 같이 계산된 값은 후보로 존재하며, 후보와 이전 셀 값을 어느 정도씩 적용할 지 비율을 결정하게 된다.
$\Gamma_u$가 0의 경우 이전 셀 값을 그대로 적용하며, 1의 경우 계산한 후보 값을 그대로 적용한다.
Reset Gate
\[\Gamma_r = \sigma(W_r[c^{\langle t-1 \rangle}, x^{\langle t \rangle}] + b_r)\]$\tilde{c}^{\langle t \rangle}$ 계산에 사용될 이전 셀 값을 어느 정도 적용할지(잊을 지) 결정한다.
LSTM(Long-Short Term Memory)
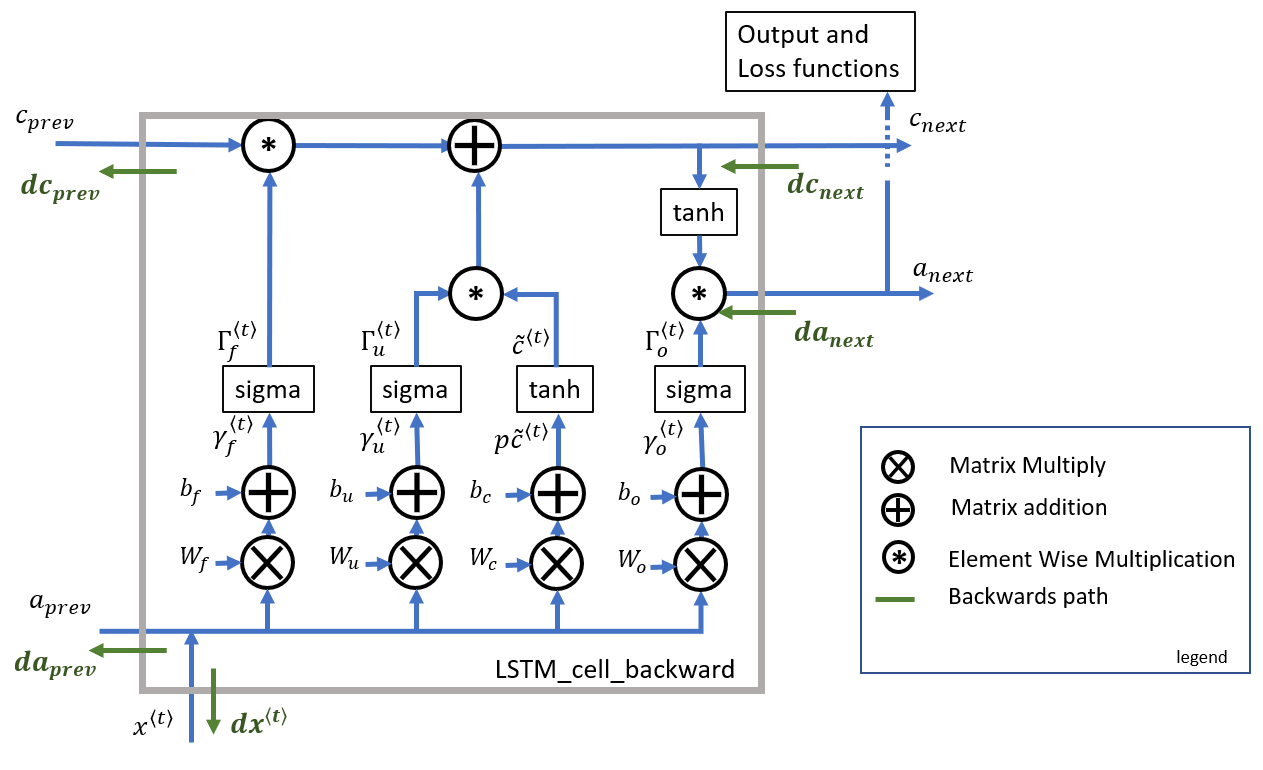
GRU처럼 update gate 하나로 적용 비율을 결정하는 것이 아닌 별도의 forget gate가 추가된다.
또한 reset gate가 존재하지 않으며 cell 값이 그대로 출력되는 게 아닌 activation 값을 만들기 위한 별도의 output gate가 추가되었다.
gate들에 추가로 $c^{\langle t-1 \rangle}$을 끼워넣어 계산하는
peephole connection라는 변형도 존재한다.
Bidirectional RNN
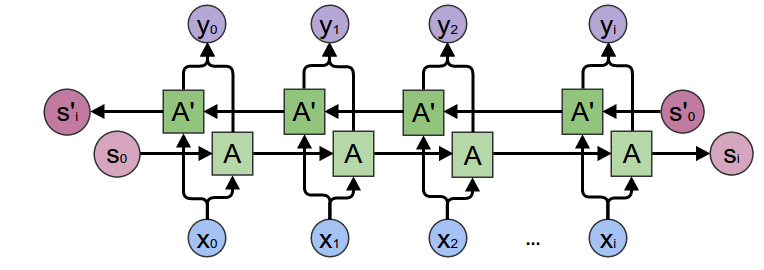
이후의 단어를 고려하지 못하는 점을 해결하기 위해 고안되어졌다. 왼쪽에서 시작하는 Recurrent Units과 오른쪽에 시작하는 Recurrent Units이 각각 존재한다.
양방향으로 계산이 완료된후 각 단계에서 두 activation을 합쳐 최종 $\hat{y}$를 계산할 수 있다.
하지만, 모든 문장을 다 확인 한 후 연산이 가능하다는 단점이 존재해 실시간 번역 같은 곳에는 사용하기 어렵다.
Deep RNN
보통 3개 정도의 Recurrent layer면 충분히 많다. 이후에 cell 연결이 없는 일반 DNN을 위에 더 붙이기도 한다.
댓글남기기