
[DLS]Convolutional Neural Networks(1)
Andrew Ng 교수님의 Coursera - Deep Learning Specialization 네번째 강의입니다.
Computer Vision
CNN은 주로 이미지 처리에 사용된다. 따라서 Computer Vision 알고리즘도 함께 사용된다.
2023년에 수강했던 computer vision 강의를 정리한 github repo를 참고하자
Convolution
(M x N)의 행렬에 대해 어떤 작은 (f x f)행렬(filter 혹은 kernel)이 적용되어 (M-f+1 x N-f+1)의 행렬을 만드는 연산이다.
만들어진 행렬의 (i,j)요소는 기존 행렬의 (i,j)요소부터 filter 크기의 행렬을 추출하여 filter와 elementwise product를 수행한 결과이다.
CNN에서의 convolution 연산은 엄밀히 말하면 cross-correlation 연산이다. 하지만 Neural Network에서는 filter를 뒤집든 안뒤집든 결국 filter의 parameter들이 이전 layer의 출력에 일괄 적용된다는 것이 중요하기 때문에 뒤집지 않더라도 Convolution 연산이라고 부른다.
Padding
filter를 적용하면 이미지 출력의 크기가 줄어들 수 밖에 없다. 또한 테두리나 모서리의 픽셀은 중간의 픽셀에 비해 반영이 적게 되는 문제도 존재한다.
가장자리에 padding을 추가하여 크기를 키우고 convolution을 적용하여 원래 크기를 보존할 수 있다.
- Valid convolution: padding 없는 연산
- Same convolution: output size와 input size를 같게 만드는 padding 추가한 연산
보통 filter의 크기는 홀수를 사용한다.
Stride
기존 연산은 한번에 1칸씩 filter가 움직이지만 stride를 적용하면 stride 간격만큼 건너뛰어 계산한다.
\[output\,size = \left\lfloor \frac{n + 2p - f}{s} \right\rfloor + 1\]Channels
RGB 같이 이미지의 픽셀에 여러개의 값이 겹칠 수 있다. 이 경우 input의 채널이 3개라고 할 수 있다.
이전 layer의 채널이 c라면 필터 또한 c의 채널을 가져야한다. 즉, (f x f x c)가 된다. 이 3차원 필터가 여러개가 될 수 있고 필터가 여러개가 되면 다음 레이어에 필터의 개수만큼 채널이 생긴다.
Bias
앞서 배운 Neural Network와 마찬가지로 각 filter에는 bias라는 단일 scalar 값이 하나씩 존재한다. filter로 convolution 연산을 적용하고 bias 값을 더해준다.
Notation
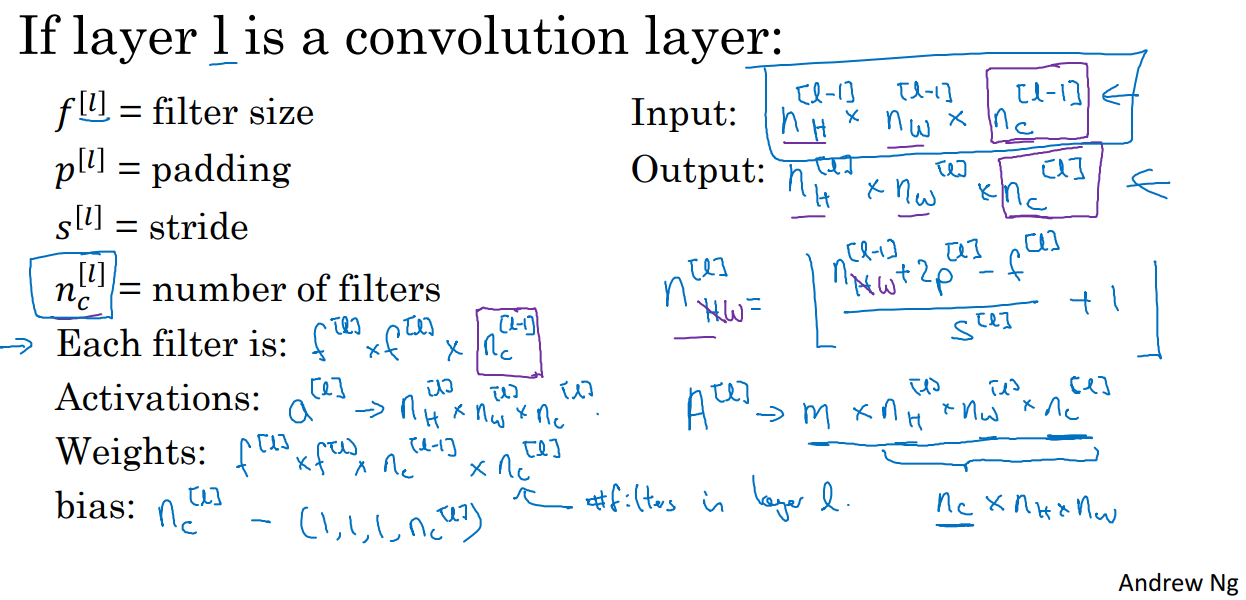
복잡해 보이지만 하나씩 읽어보면 당연한 형태이다.
ConvNet
Conv1 -> Pooling -> Conv2 -> Conv3 -> fully-connected -> logistic/softmax
위와 같은 형태로 layer를 쌓아 Convolutional Neural Network 혹은 ConvNet을 구성한다.
Conv layer
위에서 설명한 Convolution 연산을 하는 filter와 bias를 파라미터로 가지는 레이어이다.
pool layer
데이터를 좀 더 간결하게 표현할 수 있도록 압축하는 레이어이다.
filter 사이즈에 맞춰 해당 공간에 max를 적용(Max pooling)하거나, Average를 적용(Average pooling)하는 등의 역할을 한다.
정해진 pooling 연산을 수행하므로 파라미터는 존재하지 않는다.
Max Pooling이 많이 쓰인다.
FC layer
Fully connected layer로 일반적인 Neural Network처럼 이전 레이어의 모든 출력을 flatten하여 W weight 행렬을 적용해 다음 레이어를 만든다.
많은 채널로 이루어진 2차원 데이터들을 최종적으로 하나로 모아 하나의 결과값을 얻어내기 위해 필요하다.
Classic networks
LeNet-5
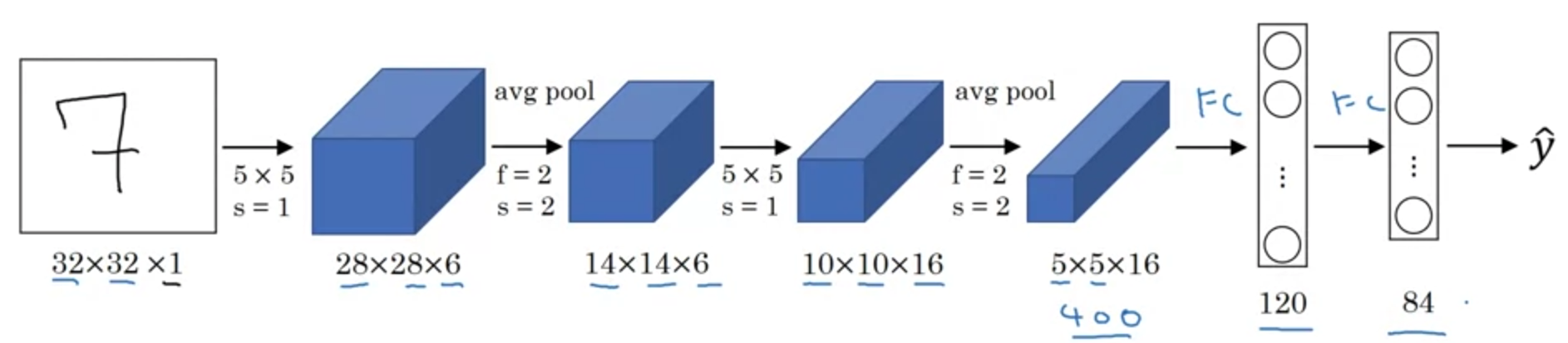
- 손으로 쓴 숫자 인식하기 위한 모델
- 60k 개 정도의 parameters
- 당시는
ReLU보다sigmoid/tanh를 주로 사용했었다.
LeCun et al., 1998. Gradient-based learning applied to document recognition
AlexNet
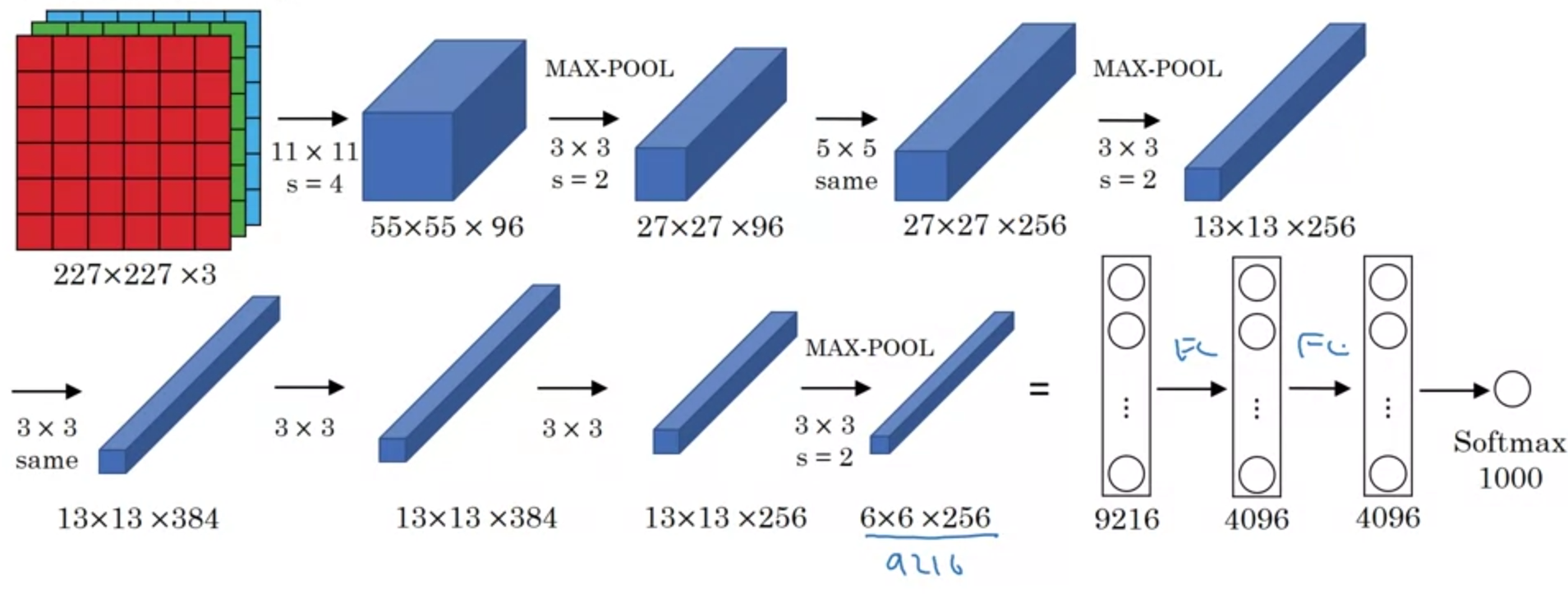
- LeNet과 비슷하지만 훨씬 크다.
- 60M 개 정도의 parameters
ReLU사용- Local Response Normalization(LRN)이 이라는 걸 추가로 사용했었다.
- layer의 출력 block에서 각 픽셀의 채널들에 대해서 정규화를 수행하는 것이다.
- 추후 연구 결과
LRN이 영향이 거의 없다는 게 밝혀져 현재는 사용되지 않는다.
Krizhevsky et al., 2012. ImageNet classification with deep convolutional neural networks
VGG-16
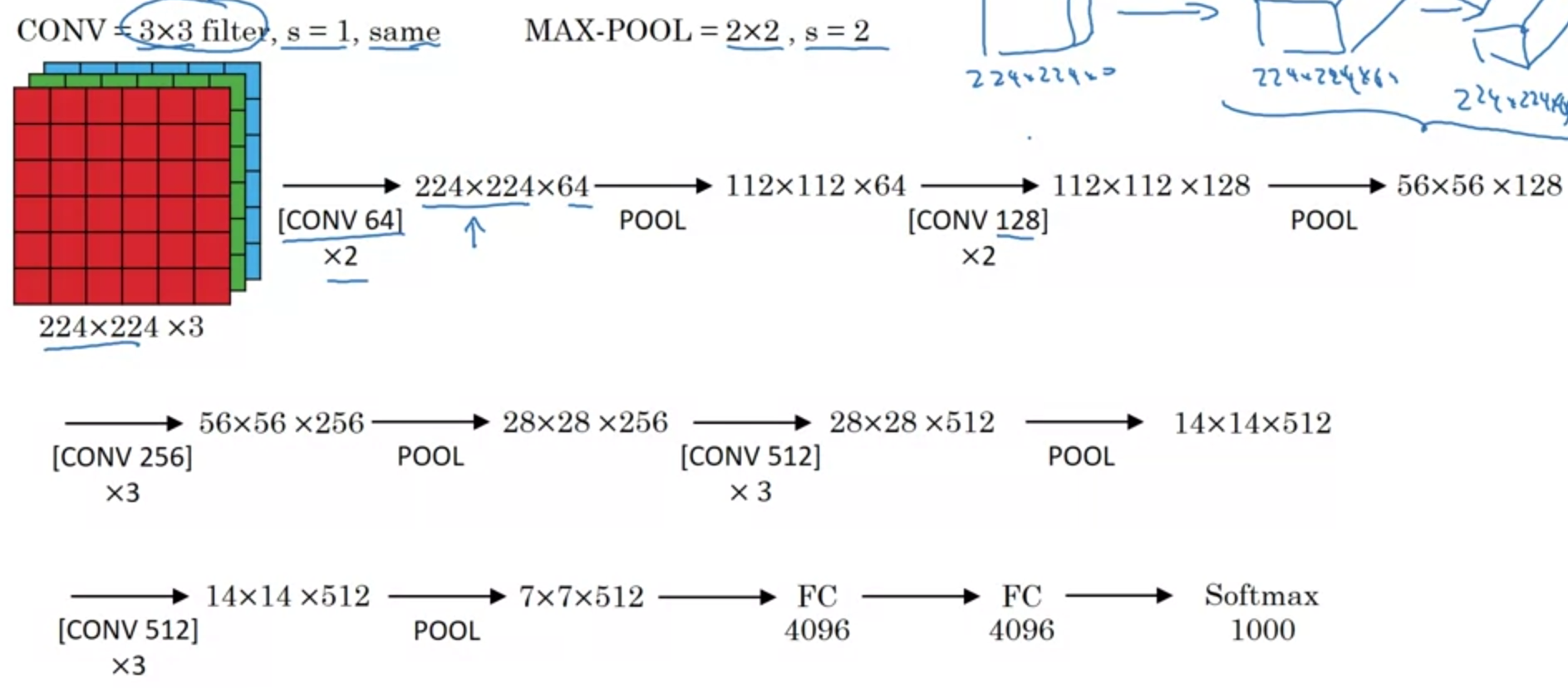
- parameter를 가지는 layer가 총 16개이다.
- Conv는 항상 3x3, stride = 1, same으로 적용한다.
- Max-pooling으로는 2x2, stride=2을 적용한다.
- 138M 개의 비교적 많은 parameter
- conv로 channel을 두배로 늘리며 pool로 W, H를 2배로 감소한다.
- 이런 규칙성은 사람들에게 Network 구성에대해 지침이 되었다.
Simonyan & Zisserman 2015. Very deep convolutional networks for large-scale image recognition
ResNet
Residual block을 도입하여 skip connection을 만들었다.
He et al., 2015. Deep residual networks for image recognition
Residual block
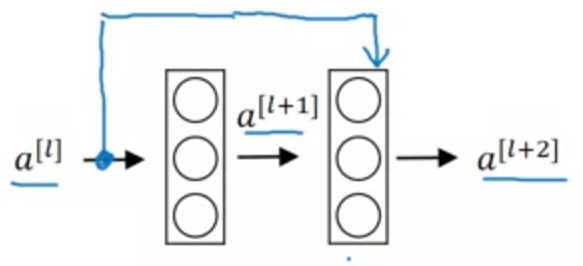
- 2개 레이어를 skip하여 값을 더하여 전달한다.
- 비선형
ReLU를 적용하기 전에 값을 더해야한다. - 이미지 상의
l + 1,l +2의 layer 블럭이 Residual block이다.
Residual Networks
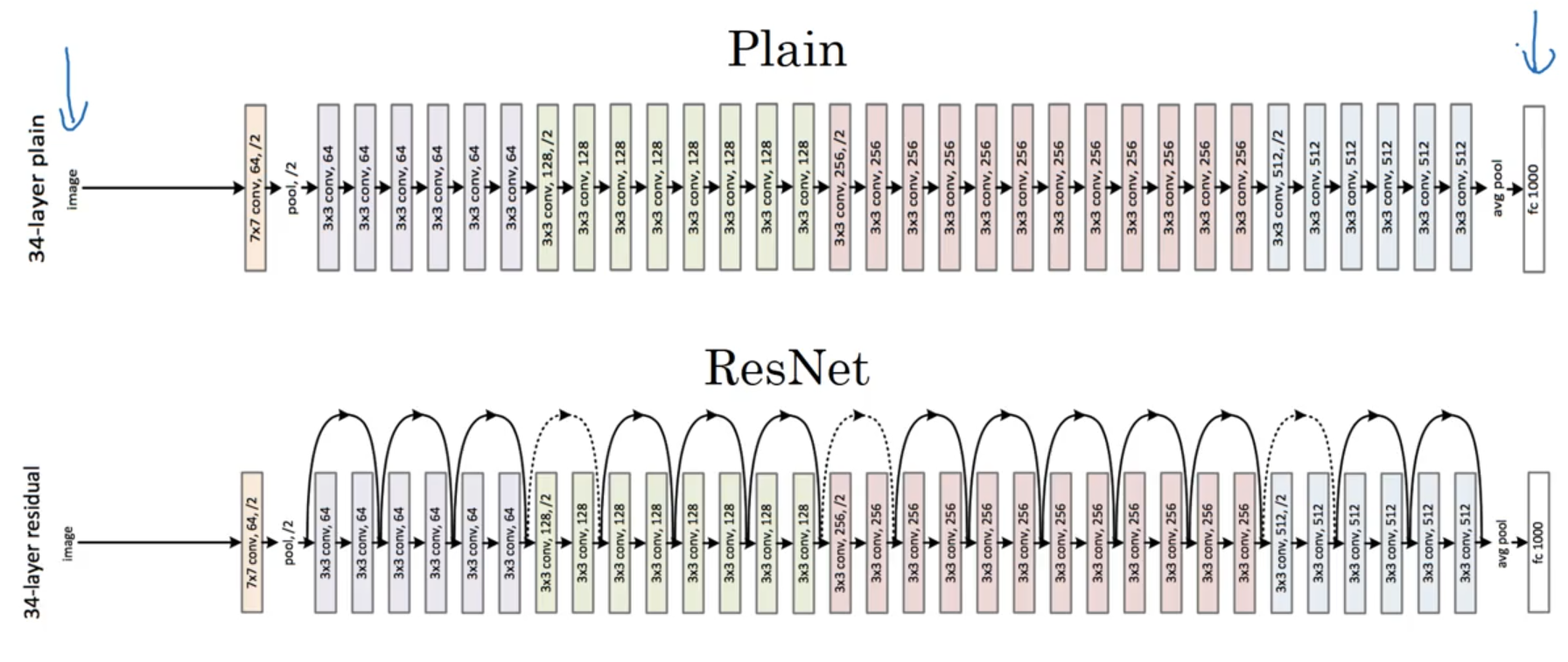
Residual block에 대한 skip connection이 이루어진다.
Residual block 내부의 W가 weight decay로 인해 0이 된다면 block의 출력은 0이 되고 skip connection으로 인해 이전 값이 그대로 오는 항등 함수가 될 수 있다.
ResNet의 장점
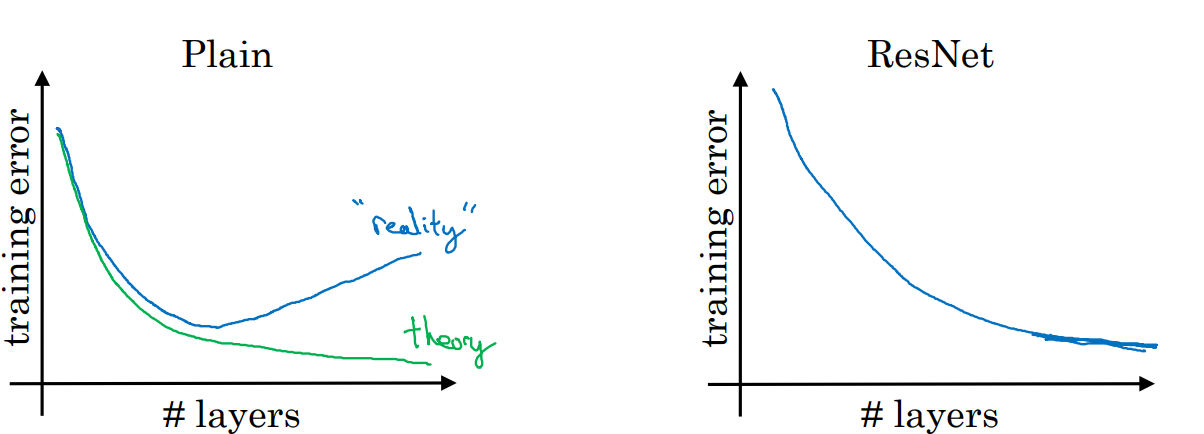
일반적인 네트워크(plain network)는 레이어를 무한정 늘리면 오히려 성능이 내려가는 현상이 존재한다. 하지만 ResNet의 경우 skip connection으로 인해 layer의 개수가 늘어남에 따라 성능이 증가하게 된다.
이는 앞서 말했듯이 항등함수로 모델이 손쉽게 학습을 할 수 있는 등의 장점이 있기 때문이다.
Inception
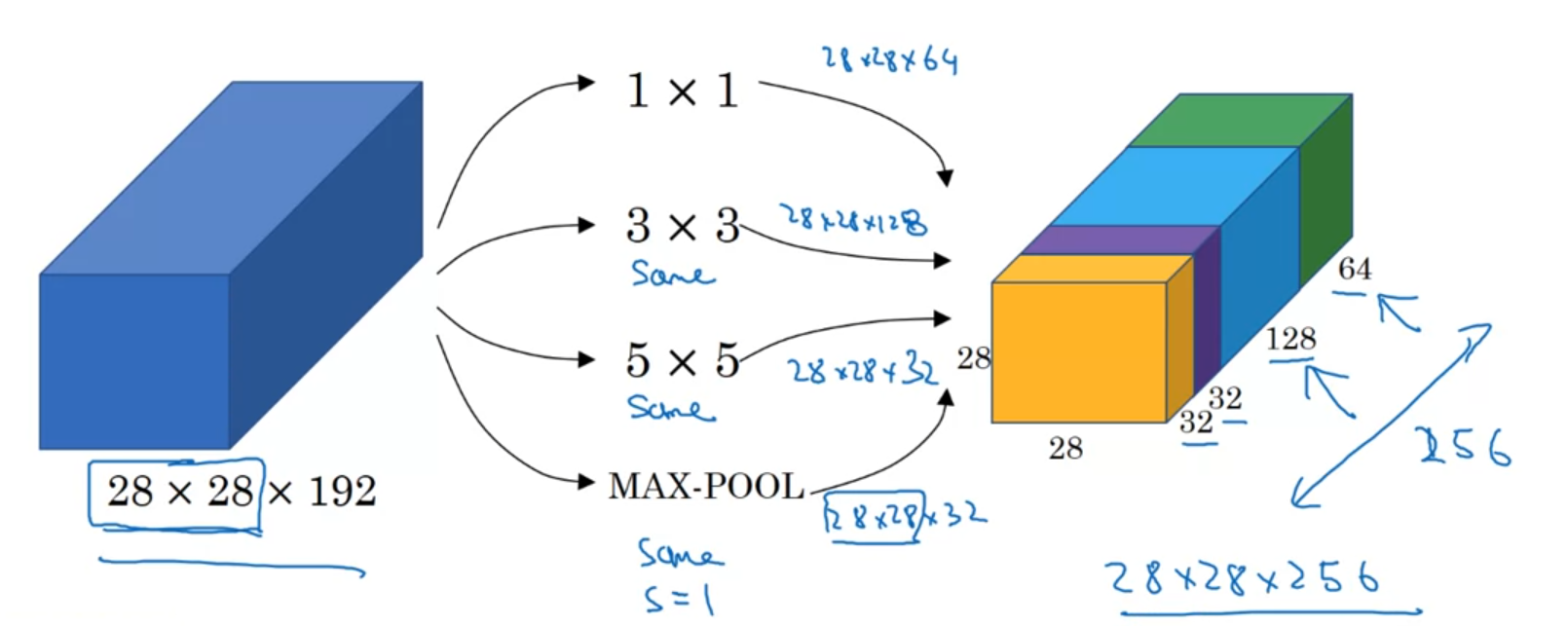
convolution, pooling 등 선택지가 많다. 이걸 전부 한번에 수행하여 concat한다.
Szegedy et al. 2014. Going deeper with convolutions
Inception Module
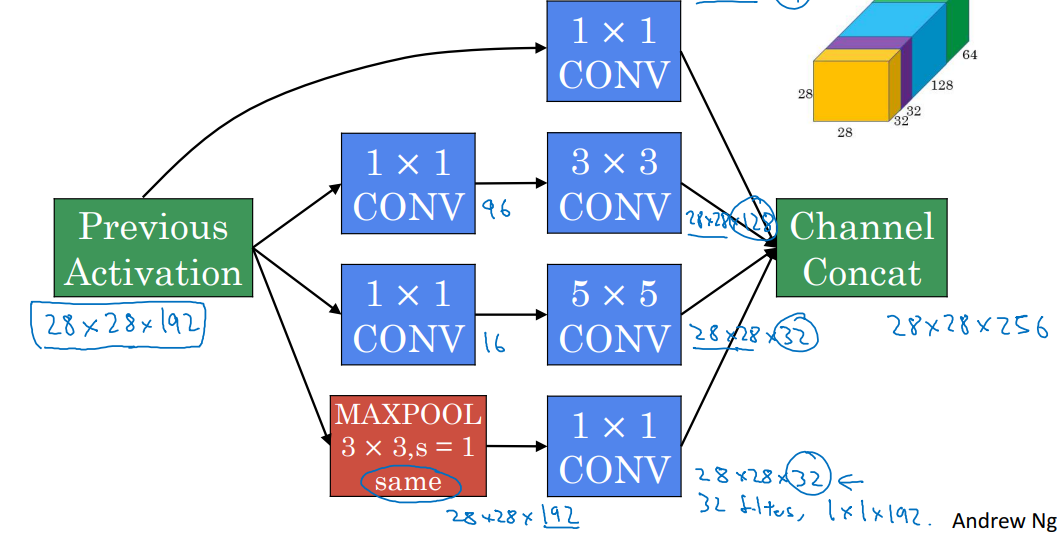
하지만 그대로 적용하면 계산량이 너무 커지는 문제가 있다. 이때 1X1 Conv Layer를 사이에 bottleneck layer로써 끼워넣으면 계산량을 크게 줄일 수 있다.
따라서 inception module의 구현은 위 사진과 같다.
1 X 1 Conv는 Network in Network라고 불린다.
Lin et al., 2013. Network in network
Inception Network(googLeNet)
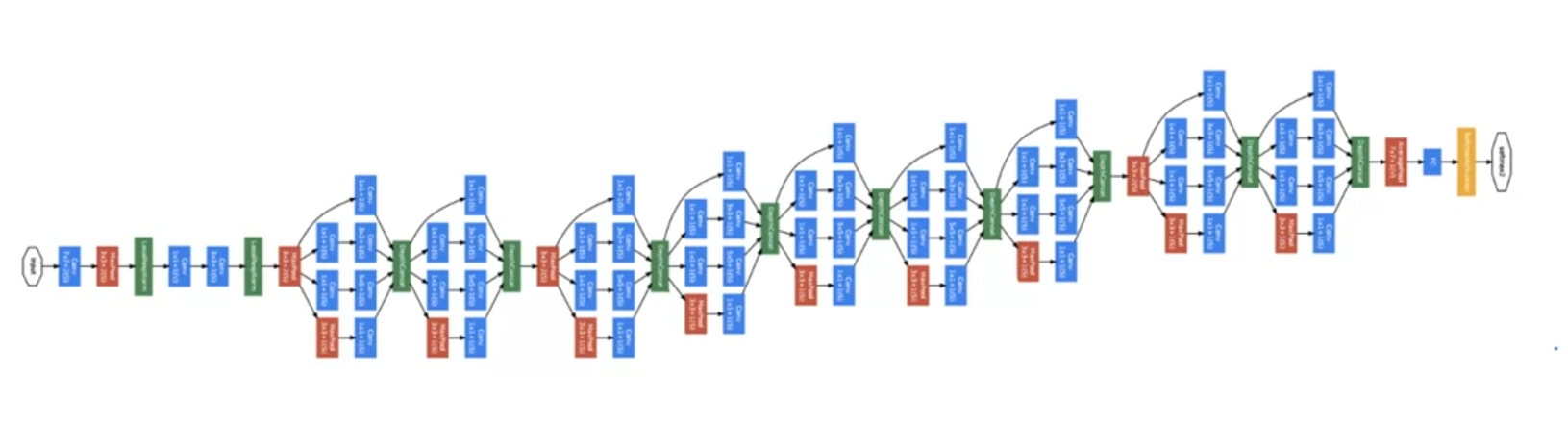
이런 inception moudule들을 연결하여 Network가 구성된다. googLeNet이라 부르는 데 별명이 inception Network이다.
영화 인셉션에서
We Need To Go Deeper라는 밈이 있어 거기서 따온 별칭이다.
MobileNet
모바일 환경 같은 제한된 cpu/gpu 환경에서 실행하기 위한 아키텍쳐이다.
Howard et al. 2017, MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
depthwise separable convolution
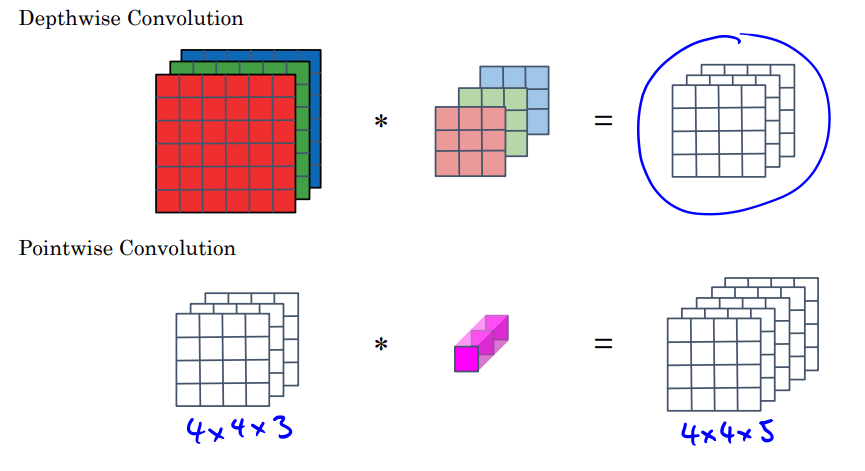
- Depthwise Convolution
- 기존은 채널들을 전부 하나의 필터를 거쳐 합쳤지만, 여기서는 인풋 채널들을 하나로 합치지 않는다.
- Pointwise Convolution
- 위의 결과를 하나로 합치는 1x1xN의 새로운 필터를 적용한다.
- pointwise 필터의 개수가 출력 채널의 개수가 된다.
이렇게 과정을 분리하고 parameter 수를 줄임으로써 아웃풋 형태는 동일하지만 일반적인 convolution보다 연산량을 줄일 수 있다.
MobileNet
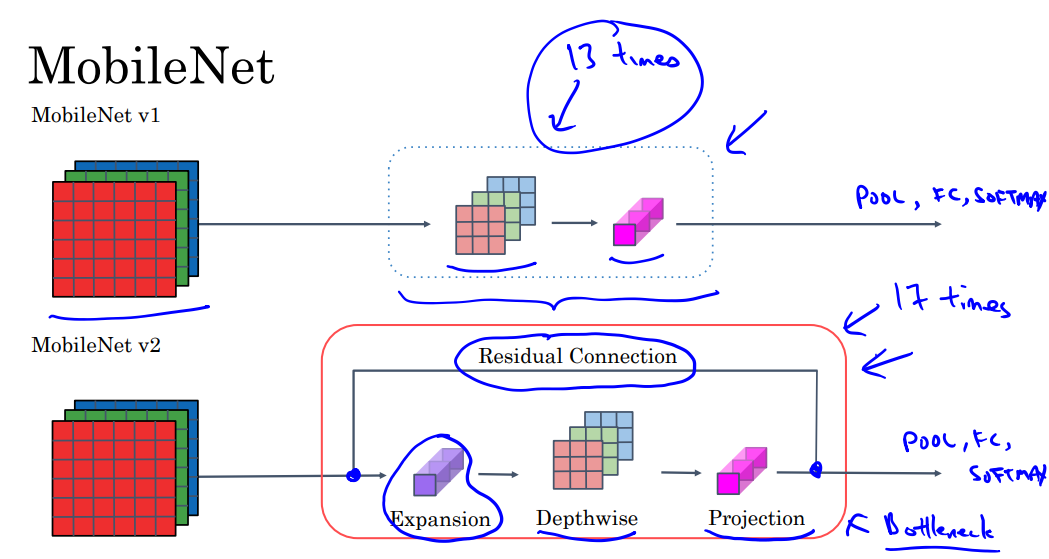
이 depthwise separable convolution을 13번 사용하는 것이 MobileNet이다.
이를 통해 연산량을 줄여 가벼운 모델을 만들 수 있다.
MobileNet v2 Bottleneck

- expansion과 residual connection을 추가하였다.
- depthwise 블럭은 17번 반복된다.
Sandler et al. 2019, MobileNetV2: Inverted Residuals and Linear Bottlenecks
EfficientNet
d, w, r(depth; layer의 수, width; channel의 수, resolution; 해상도 WxH) 중 어느것을 키워야하는 지 혹은 어느 비율로 만들어야하는지 알기 어렵다.
이에 대한 해결책으로 적절한 d, w, r 값들을 제시한 논문이다.
Tan and Le, 2019, EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks
댓글남기기