
[Review] VL-JEPA: Joint Embedding Predictive Architecture for Vision-language
저번에 소개한 JEPA 계열의 최신 논문, Vision-Language JEPA다. 월드 모델(world model) 관점에서 보았을 때 충분히 경쟁력 있는 비전‑언어 아키텍처로 보인다.
핵심 포인트는 “토큰을 생성하지 않고 임베딩을 예측한다”는 점이다. 자연어 토큰을 직접 생성하지 않고 자유로운 latent space에서 학습하기 때문에 의미 중심의 표현 학습이 가능하며, 그 결과 적은 데이터로도 높은 성능을 내는 것이 가능했다. 반면 최종 출력이 자연어가 아닌 임베딩이므로, 이를 자연어로 변환하려면 별도의 디코더가 필요하다는 단점이 존재한다.
VL-JEPA: Joint Embedding Predictive Architecture for Vision-language
논문 리뷰 - Weekly Tech Trend Talk 스터디(25.01.08)
1. 개요
1.1. 모델 구조

VL-JEPA는 비주얼 입력(X_v)과 텍스트 질의(X_q)를 받아, 텍스트 정답(Y)을 직접 생성하지 않고 정답 임베딩(S_y)을 예측한다.
- X_v: X-Encoder의 입력(이미지/비디오)
- X_q: 질의 텍스트(프롬프트)
- Y: Y-Encoder의 입력(정답 텍스트)
1.2. 주요 특징
- Non‑generative: 토큰을 생성하지 않아 의미 중심의 표현 학습에 집중할 수 있다.
- Non‑autoregressive: 연속적인 임베딩을 즉시 뽑을 수 있어 실시간 처리에 유리하다.
- Selective Decoding: 임베딩 스트림 내 변화가 임계값 이상일 때만 디코딩한다.
- 결과적으로 디코딩 작업이 크게 줄어듦(그림 기준 2.85배 감소).
- Selective Decoding: 임베딩 스트림 내 변화가 임계값 이상일 때만 디코딩한다.
1.3. 토큰 레벨 생성과 비교하면 장점
- 토큰 레벨 생성
- 질문: “전등 스위치를 내리면 어떻게 될까요?”
- 가능한 답: “램프가 꺼집니다.”, “방이 어두워집니다”
- 의미는 같지만 토큰이 다르게 나와 학습이 어려울 수 있다.
- JEPA
- “램프가 꺼집니다.”, “방이 어두워집니다” 등의 스위치를 내렸을 때 일어날 현상 예측이 같은 공간으로 임베딩 가능
2. 모델 핵심 설명
2.1. 모델 상세 구조
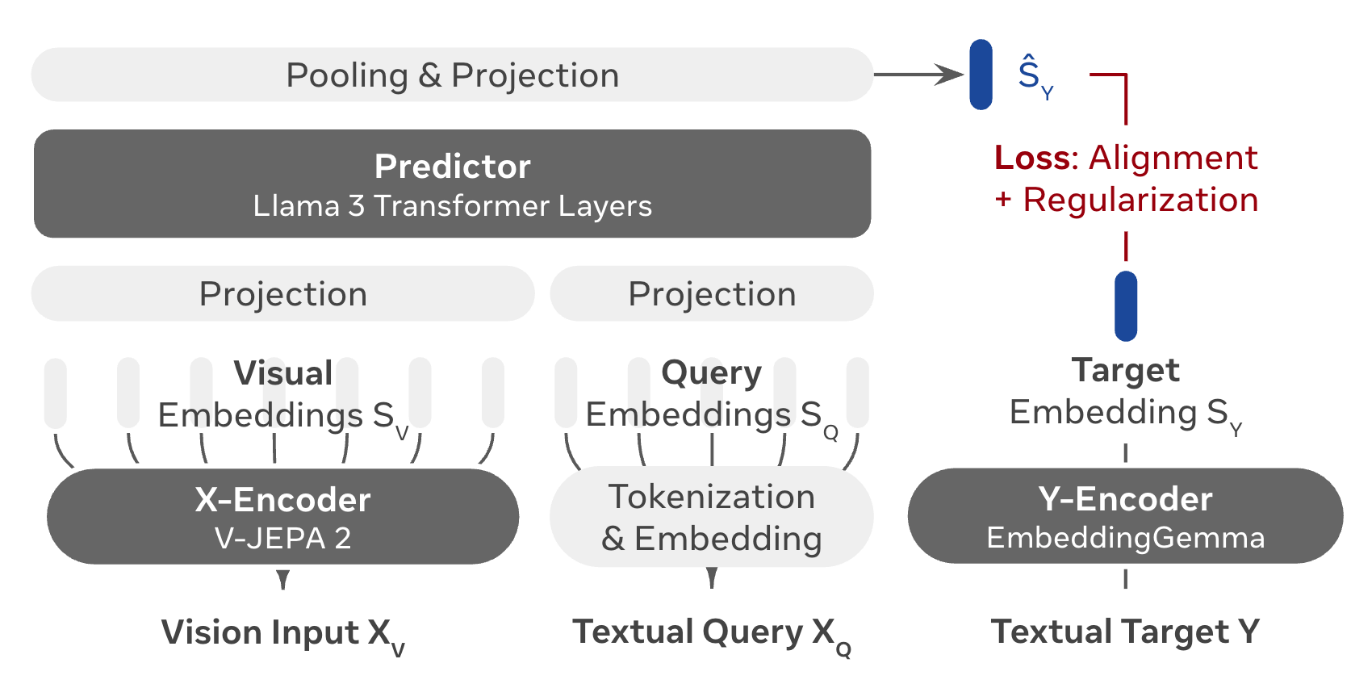
그림은 VL-JEPA의 구성을 요약한다. 비주얼/텍스트 입력을 각각 임베딩으로 변환한 뒤, Predictor가 정답 임베딩(S_y)을 맞추는 구조다. 학습에 사용되는 손실함수는 alignment + regularization 이다.
- X-Encoder
- V-JEPA 2 ViT-L 사용(자기지도 학습)
- Predictor
- Llama-3.2-1B의 마지막 8개 layer(490M)
- Causal attention mask 비활성화
- 512 context length
- Y-Encoder
- EmbeddingGemma-300M으로 초기화 되어 있음
- 512 context length
2.2. Multitasking 능력(다양한 작업에 활용 가능)
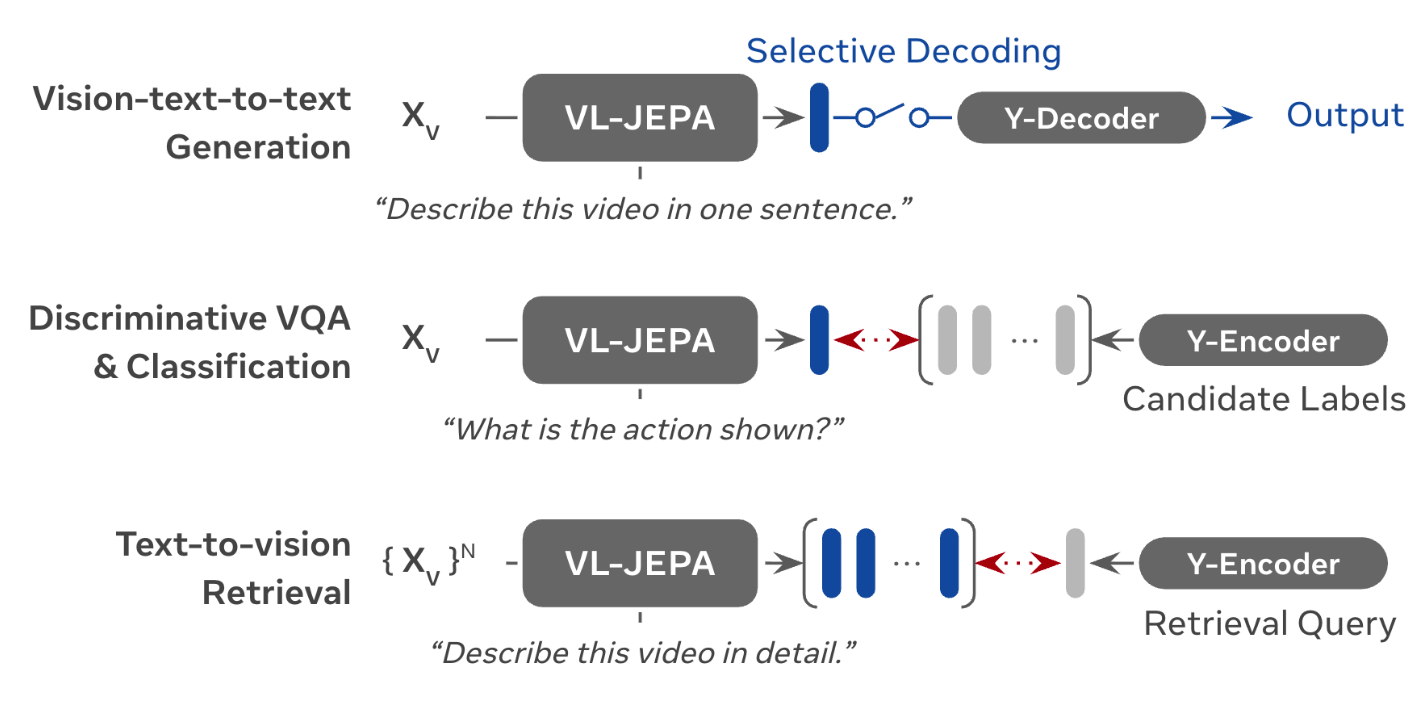
동일한 임베딩 공간을 활용해 생성, 분류, 검색을 모두 처리할 수 있다. 특히 분류/검색은 텍스트 디코더 없이도 수행 가능해 효율적이다.
2.3. Selective Decoding
네비게이션, 로봇, 실시간 영상 상호작용 등 world states 모니터링이 필요한 경우 실시간 스트리밍 추론이 필요
→ 매 프레임마다 현재 상태 추론을 해야함(latency와 계산 효율성이 중요)
- 기존 VLM
- 명시적 메모리 메커니즘(explicit memory mechanism)에 의존하여 디코딩 시기를 결정
- 효율성을 위해 복잡한 KV 캐시 최적화 적용
- VL-JEPA
- non‑autoregressive하게 실시간으로 연속된 임베딩을 만든다.
- 임베딩의 변화가 큰 구간에서만 선택적으로 디코딩한다.
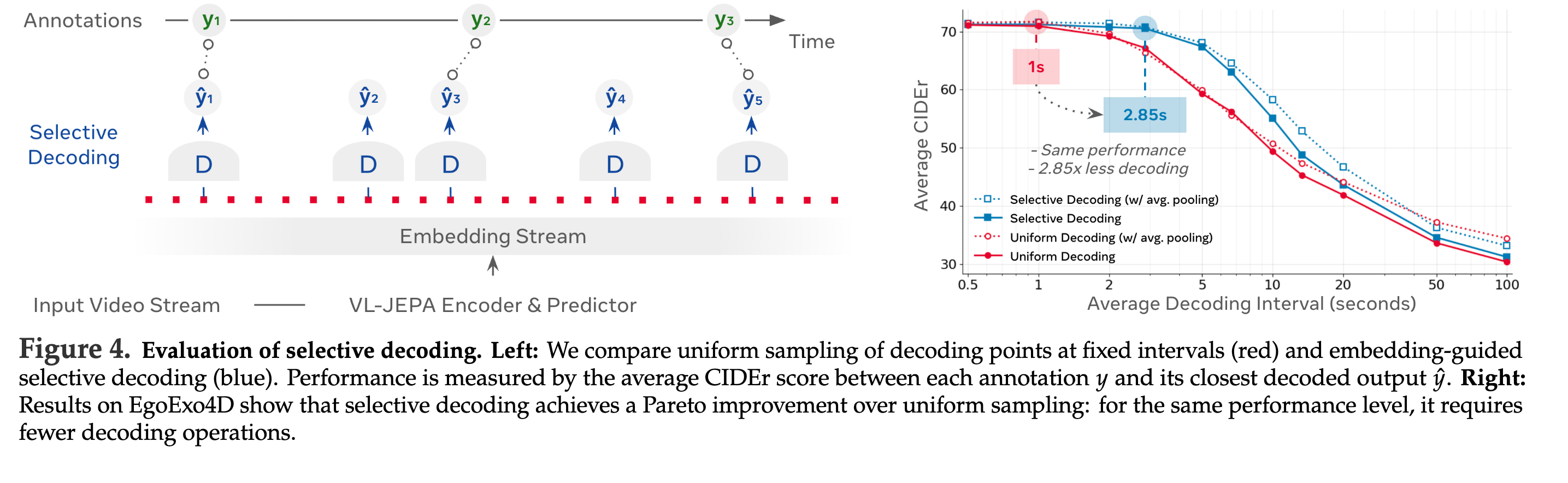
왼쪽은 선택적 디코딩 개념도, 오른쪽은 동일 성능 기준에서 더 적은 디코딩으로도 가능함을 보여준다.
2.4. 토큰 예측(VLM)과 임베딩 예측(VL-JEPA) 비교
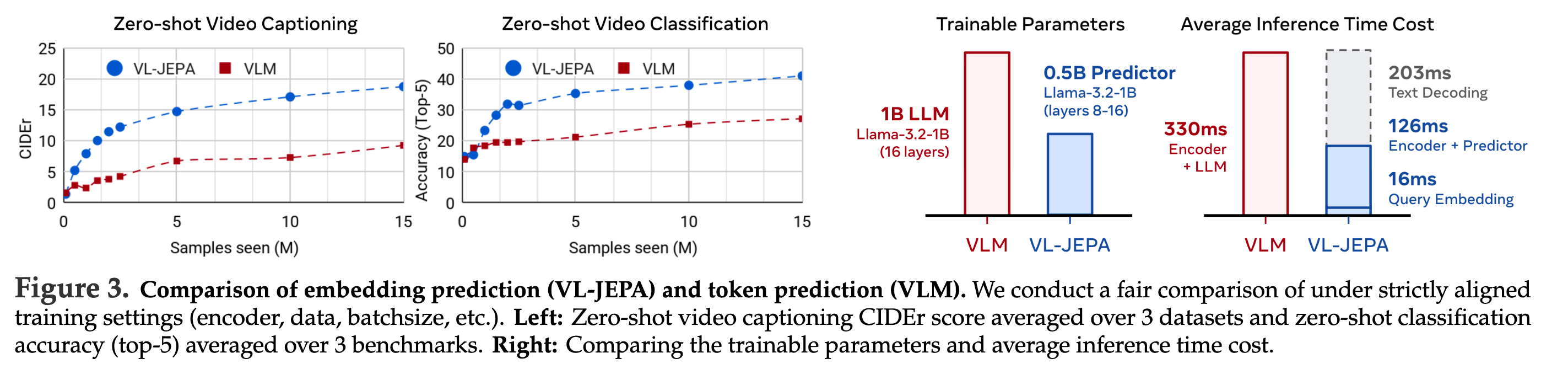
왼쪽 그래프는 zero-shot 캡셔닝/분류 성능을, 오른쪽은 파라미터 규모와 추론 시간을 비교한다. 임베딩 예측 방식이 성능과 효율 측면에서 유리한 추세를 보인다.
3. 학습
3.1. First step. query-free pretraining → VL-JEPA_base
대규모 캡션 데이터 활용
웹 상에서 수집한 이미지 캡션, 혹은 AI로 자동 생성한 캡션 데이터
- Image-text 데이터
- PLM-Image-Auto
- Datacomp
- YFCC-100M
- Video-Text 데이터
- PLM-Video-Auto
- Ego4D atomic action descriptions
- Action100M(HowTo100M 비디오에 캡션 붙인 내부 데이터)
3.2. Second Step. Supervised Finetuning → VL-JEPA_sft
사람이 수작업으로 생성한 고품질 데이터
- PLM data 혼합
- 25M의 VQA 샘플
- 2.8M의 캡션 샘플
- 1.8M의 분류 샘플
- 약간의 pretraining에 사용한 데이터(catastrophic forgetting 방지용)
4. 성능
4.1. Video 분류, text-to-video 검색
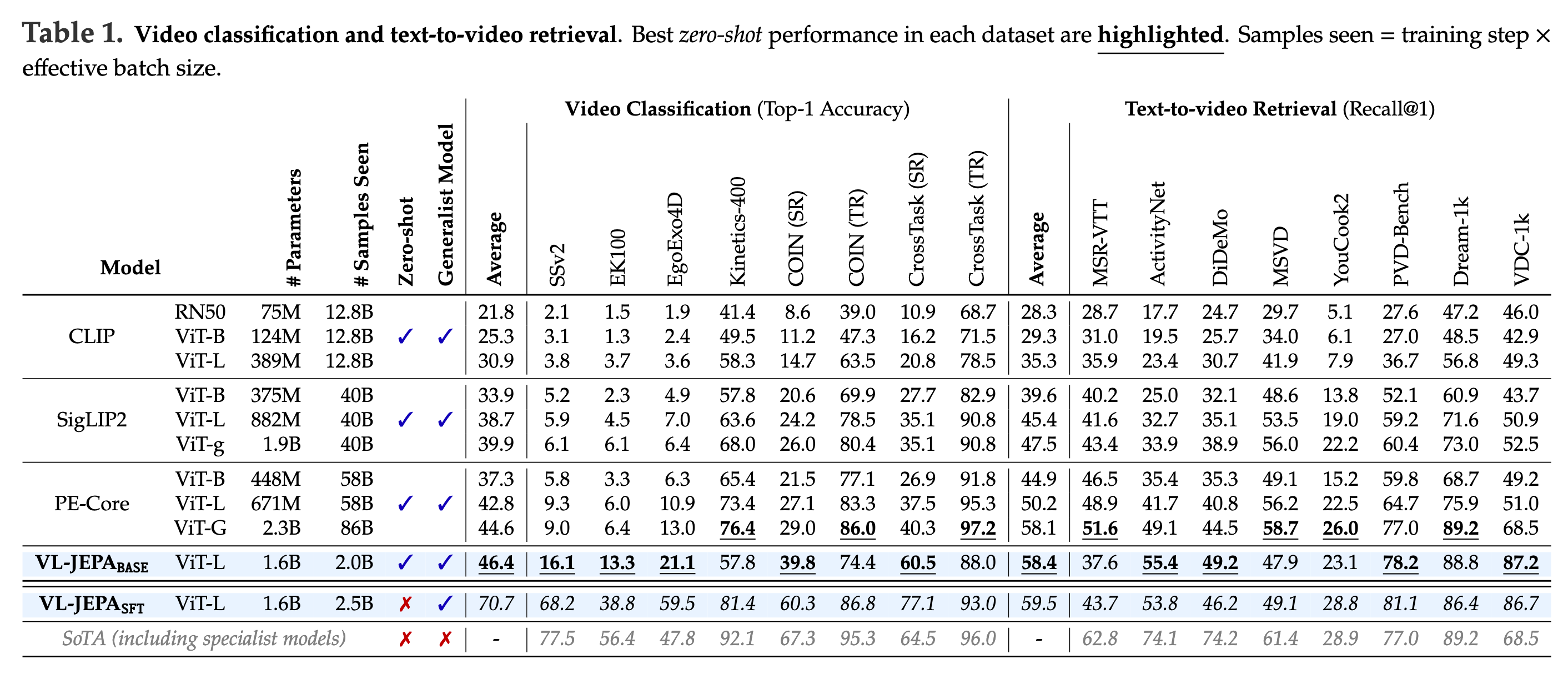
표는 zero-shot 성능 기준에서 VL-JEPA_base / SFT가 강한 결과를 보임을 보여준다.
4.2. VQA(Visual Question Answering)
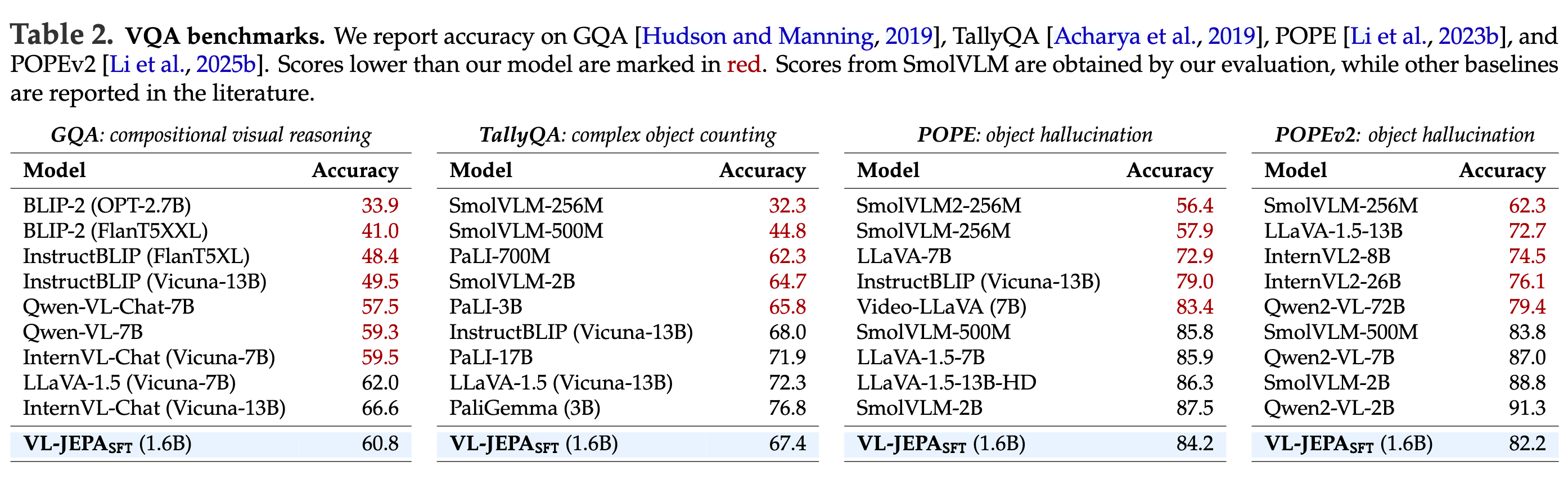
GQA, TallyQA, POPE/POPEv2 등 VQA 계열에서 VL-JEPA_SFT(1.6B)가 경쟁력 있는 성능을 보인다.
4.3. WorldPrediction-WM

WorldPrediction‑WM 벤치마크에서는 VL-JEPA_SFT가 최상 성능(SoTA)을 기록한다.
댓글남기기