
[Review] Reflexion: Language Agents with Verbal Reinforcement Learning
Reflexion은 2023년 10월에 나온 논문으로, LLM이 시행착오로부터 스스로 피드백을 생성하고 개선할 수 있는 프레임워크이다.
전통적인 강화학습을 통한 weight 조정은 비용이 비싸고, 많은 데이터가 필요한 반면, Reflexion은 언어적 피드백을 통해 간단하게 성능을 개선할 수 있다.
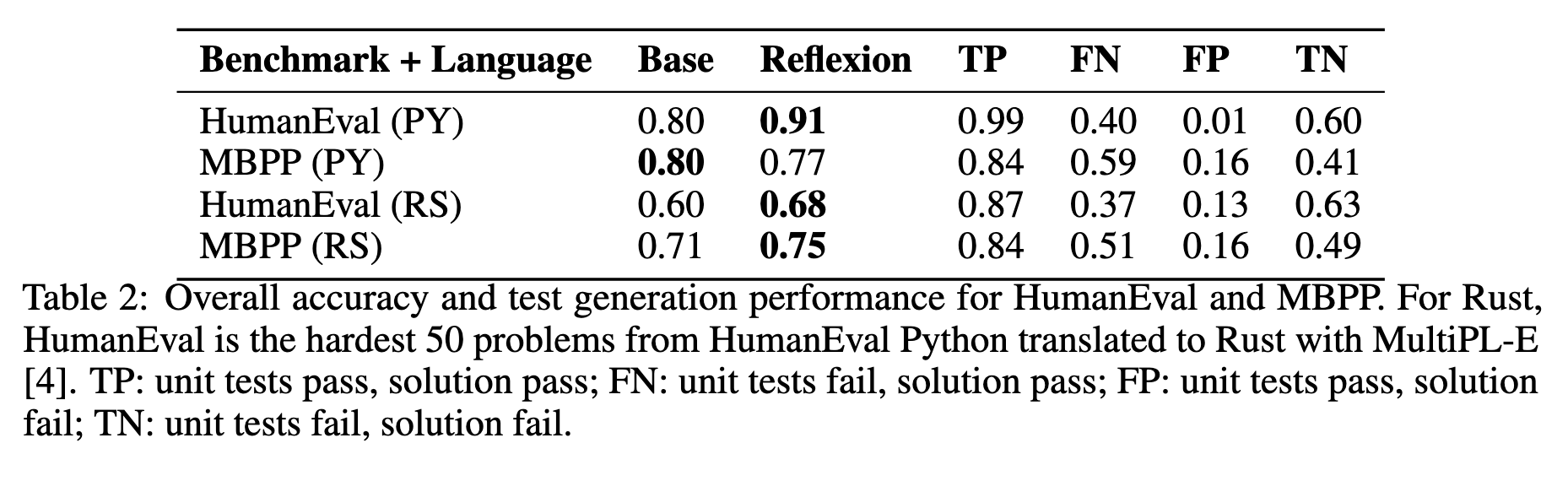
이 방법을 통해 HumanEval coding benchmark에서 기존 GPT-4는 80%인데 reflexion을 적용해서 91% pass@1 을 달성하였다.
Reflexion: Language Agents with Verbal Reinforcement Learning
Introduction
요즘 에이전트는 텍스트로 사고(Thought)와 행동(Action)을 생성하고, 필요하면 도구/API를 호출한다. 하지만 대규모 파라미터를 가진 LLM을 직접 강화학습으로 최적화하는 것은 데이터와 비용 부담이 크다.
Reflexion은 직전 시도들의 실패/성공에서 언어적 피드백을 스스로 만들어 메모리에 저장하고, 다음 시도에 이를 활용해 성과를 끌어올리는 방식이다. 별도의 파라미터 업데이트 없이도 시행착오에서 학습한다는 점이 핵심이다.
Reflexion: reinforcement via verbal reflection
Reflexion이 3가지의 다른 모델(Actor, Evaluator, Self-Reflection)와 함께 그동안의 생각 및 행동을 저장하는 memory 컴포넌트로 구현된다.
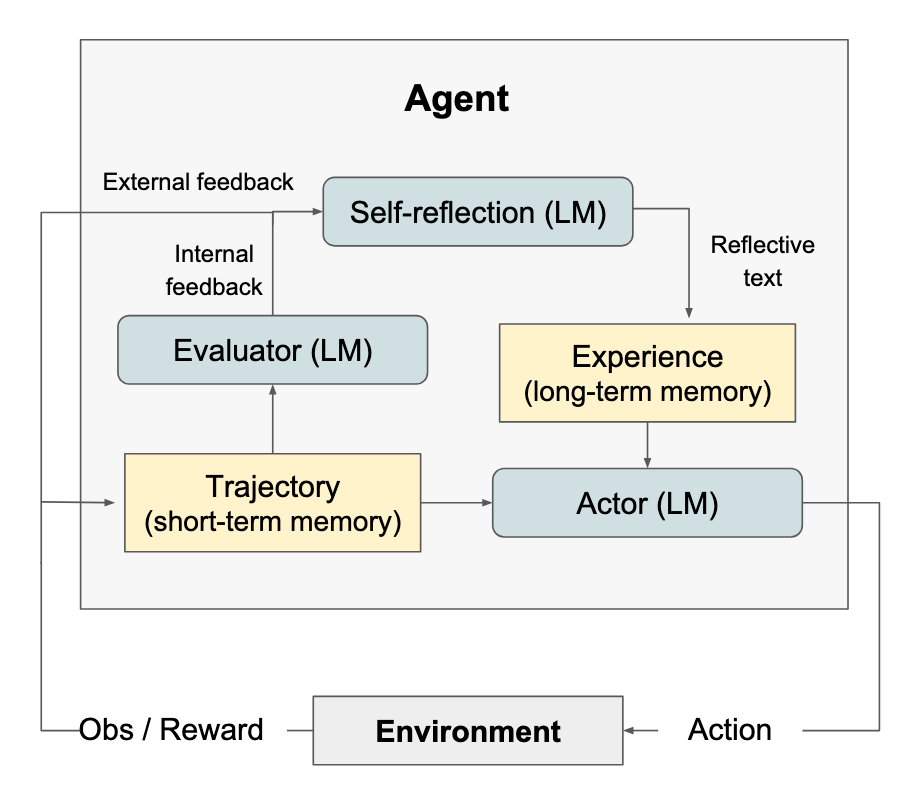
Actor
주어진 관측에서 필요한 텍스트/행동을 생성하는 LLM이다. 이 에이전트는 메모리(이전 시도의 요약·피드백)를 불러와 현재 컨텍스트로 활용한 뒤 다음 행동을 출력한다.
Evaluator
생성된 trajectory(Thought → Action → Observation으로 이어지는 궤적)를 입력으로 받아 품질을 평가하고 점수를 매긴다. 이 평가는 Self-Reflection 단계로 전달된다.
Self-Reflection
성공/실패 여부, evaluator의 평가, trajectory, 메모리 등을 종합해 자연어 피드백을 생성한다. 이 피드백은 다음 시도에서 Actor가 참고할 수 있도록 경험 메모리에 저장된다.
Memory
메모리는 두 가지로 나뉜다.
- Short‑term (Trajectory): 현재 에피소드에서의 사고·행동 히스토리
- Long‑term (Experience): Self‑Reflection이 만든 피드백들의 축적
LLM의 컨텍스트 길이를 고려해 최근 항목 위주로 최대 3개까지만 포함한다.
Experiments
요약: ALFWorld +22%p, HotpotQA +20%p, HumanEval +11%p 향상.
Sequential decision making: ALFWorld
ALFWorld는 가상 가정 환경에서 텍스트 명령으로 객체를 탐색·이동·조작하는 시뮬레이션 벤치마크다.
텍스트 시뮬레이션 세계에서 LLM의 순차적 결정으로 미션을 수행하게 하였고 기존 ReAct보다 22% 많이 성공하였다.
ReAct 108/134 → **Reflexion **130/134.
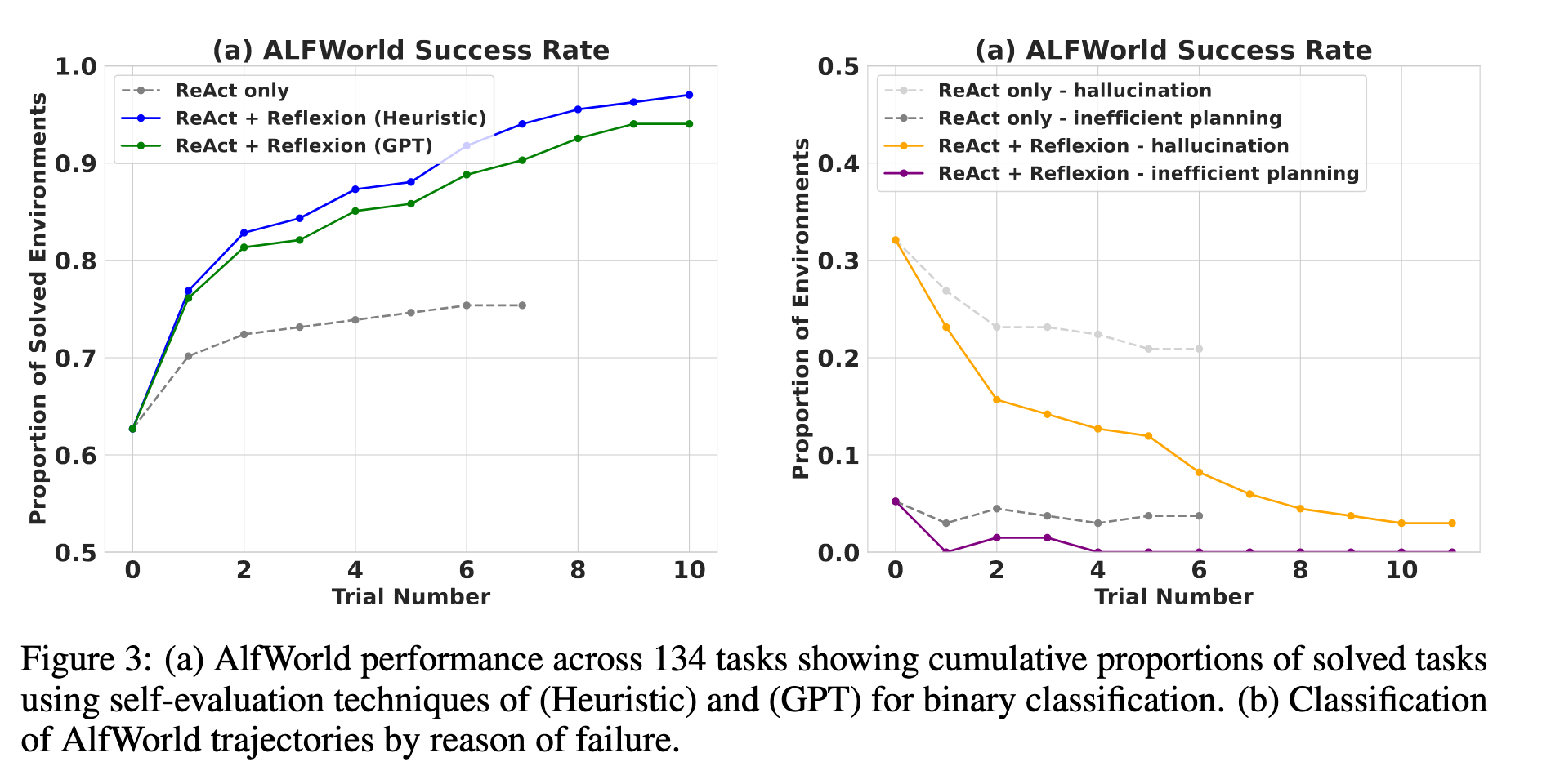
ReAct만 사용할 때 생기는 정체 구간을 Reflexion이 다음과 같이 돌파한다:
- 초반 오류 교정: 긴 궤적 초반의 실수를 빠르게 식별하고, 새로운 행동 선택이나 장기 계획을 제안한다.
- 체계적 탐색: 표면/컨테이너 등이 많은 환경에서는 경험 메모리를 활용해 방 단위로 철저히 탐색한다.
Reasoning: HotpotQA
문서 Context Retrieval이 필요한 질의응답에서도 잘 동작하며, GT(정답 문장)가 주어진 환경에서도 추가 향상을 보였다. 단순히 이전 실패 기록만 제공하는 것보다, reflection 문장을 함께 제공할 때 성능이 더 오른다.
정답 여부는 Exact Match(EM) 기준으로 판정하고, 실패 시 self‑reflection이 오류 유형과 교정 방향을 자연어로 확장한다.
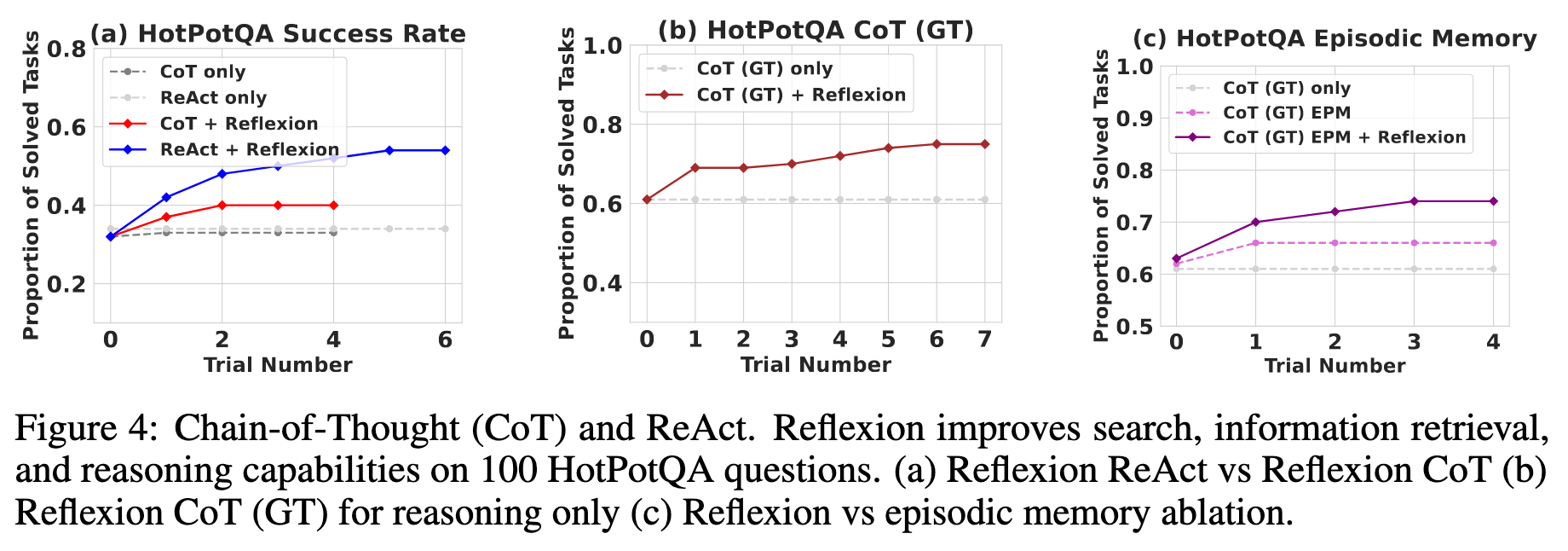
에피소드 메모리만 쓸 때 대비, self‑reflection 포함 시 절대 8%p 추가 향상을 보였다.
Programming
각 문제에 대해 CoT로 생성한 unit test(예: 6개)로 정답 여부를 검증한다. 후보 파이썬 코드는 AST 파싱을 통과한 것만 채택해 문법 오류를 걸러낸다. 실패하면 evaluator가 실패 유형을 요약하고, self‑reflection이 수정 전략(로직 보정, 경계 조건 강화, 라이브러리 호출 교체 등)을 제안한다. 그 피드백을 받아 Actor가 패치된 코드를 생성·재시도한다. 난도가 높을수록 평가 + 반성의 조합이 더 큰 이득을 준다.

Limitations
policy optimization없이 자연어로 최적화를 할 수 있는 기법이지만, 여전히 최적이 아닌 local minima solution에 빠질 수 있다.
또한, 비결정 문제, 외부 상호작용 등 TDD로 접근할 수 없는 함수에 대해서는 한계가 있다.
Broader Impact
기존 강화학습과 달리 자연어 기반 강화학습으로 최적화된 스텝으로 얼라인해가는 과정을 해석가능하게 만들었다. 이를 통해 어떤 의아한 행동도 자기반성 내용을 모니터링 함으로써 의도를 확인할 수 있다.
Conclusion
Reflexion 기법은 현재 널리 쓰이는 의사결정 접근법(COT, ReACT 등)보다 더 좋은 성능을 낸다.
Appendix
이러한 자기반성 능력은 흔히 emergent quality로 불린다. (논문 시점인 2023년 기준) 15.5B급 모델에서는 체감 이득이 작다고 보고된다.
2023년 결과 기준임을 감안하자. 최근 10–20B급 모델의 성능은 더 좋아졌다.
WebShop Limitation
Webshop(web에서 사용자가 원하는 물건을 찾아서 주문해주는 task)에서는 성능 향상이 거의 안 나타났다. 이는 다양성/탐색성 요구가 매우 큰 과제에는 이 접근만으로는 이득이 제한적일 수 있음을 시사한다.
후기
네이버 부스트캠프 7기 AI Tech NLP 최종 프로젝트 매일메일에 Reflexion을 실전 적용했었다. 우리는 많은 메일 목록들을 최대한 고품질로 요약, 정리하여 생성하기를 원했다. 또한, 이 시스템은 실시간 채팅과 달리 속도에 대한 제약이 적었고, 많은 시간을 들여 피드백 루프를 돌아 성능을 끌어올릴 수 있어 적합했다. 효과는 기대한 만큼 좋아 형식 오류와 불필요한 환각이 줄었고, 필수 정보 누락도 크게 감소했다. 내부 평가지표(G‑eval)는 3.75 → 4.19로 개선됨을 확인하였다.
단일 추론에 비해 비용은 비싸지만, 루프를 돌면 돌수록 성능이 높아지기에 고성능이 필요하다면 좋은 선택이 될 수 있는 구조라고 생각한다!
댓글남기기