
[Review] Qwen2.5-VL Technical Report
요즘 AI 서비스들은 대부분 이미지 인식 기능을 탑재하고 있다. 과연 이런 멀티모달 VLM은 실제로 어떤 모델 구조를 가지고 있을까?
이에 대한 개념을 잡기 위해 Qwen2.5‑VL Technical Report를 살펴봤다.
Qwen 3도 나왔지만, Qwen 3는 MoE 구조 등 복잡한 부분이 많아 우선 초보자가 이해하기 쉬우면서 최신 SOTA 구조를 취하고 있는 Qwen2.5‑VL을 선택했다.
Qwen2.5-VL Technical Report
논문 리뷰 - Weekly Tech Trend Talk 스터디(25.01.22)
1. Introduction
- 여러 연구로 Visual Encoder, Cross‑Modal Projector, LLM으로 VLM을 구성하는 패러다임이 자리잡았다.
- Omni 및 MoE 구조도 VLM 발전에 많은 영향을 끼치고 있음
- 해상도 스케일링(고해상도) 등 실용적인 측면도 연구되고 있음
- 당시 시점의 병목
- 계산 복잡성
- 상황 맥락 이해의 한계
- 세밀한 비전 이해 부족
- sequence(비디오 등) 길이에 따라 일관되지 않은 성능
1.1. Qwen2.5‑VL의 기술적 기여
- visual encoder의 window attention → 추론 효율성
- 동적 FPS 샘플링 → 동적 해상도를 시간 차원으로 확장, 다양한 샘플링 속도에도 비디오 이해 가능
- 절대 시간에 맞춘 MRoPE
- 고품질 데이터 → 학습 데이터 엄선 및 학습 토큰량을 1.2조에서 4.1조 토큰으로 확장
1.2. 주요 특징
- 문서 이해 능력이 뛰어남
- 재무재표, 과학 그래프, 손글씨 등
- 초 장편 비디오 이해능력(몇 시간 단위)
- 72B는 GPT‑4o, Claude 3.5 Sonnet 등을 상대로 강한 성능을 보임
- 7b, 3b도 존재함
2. 모델 아키텍처
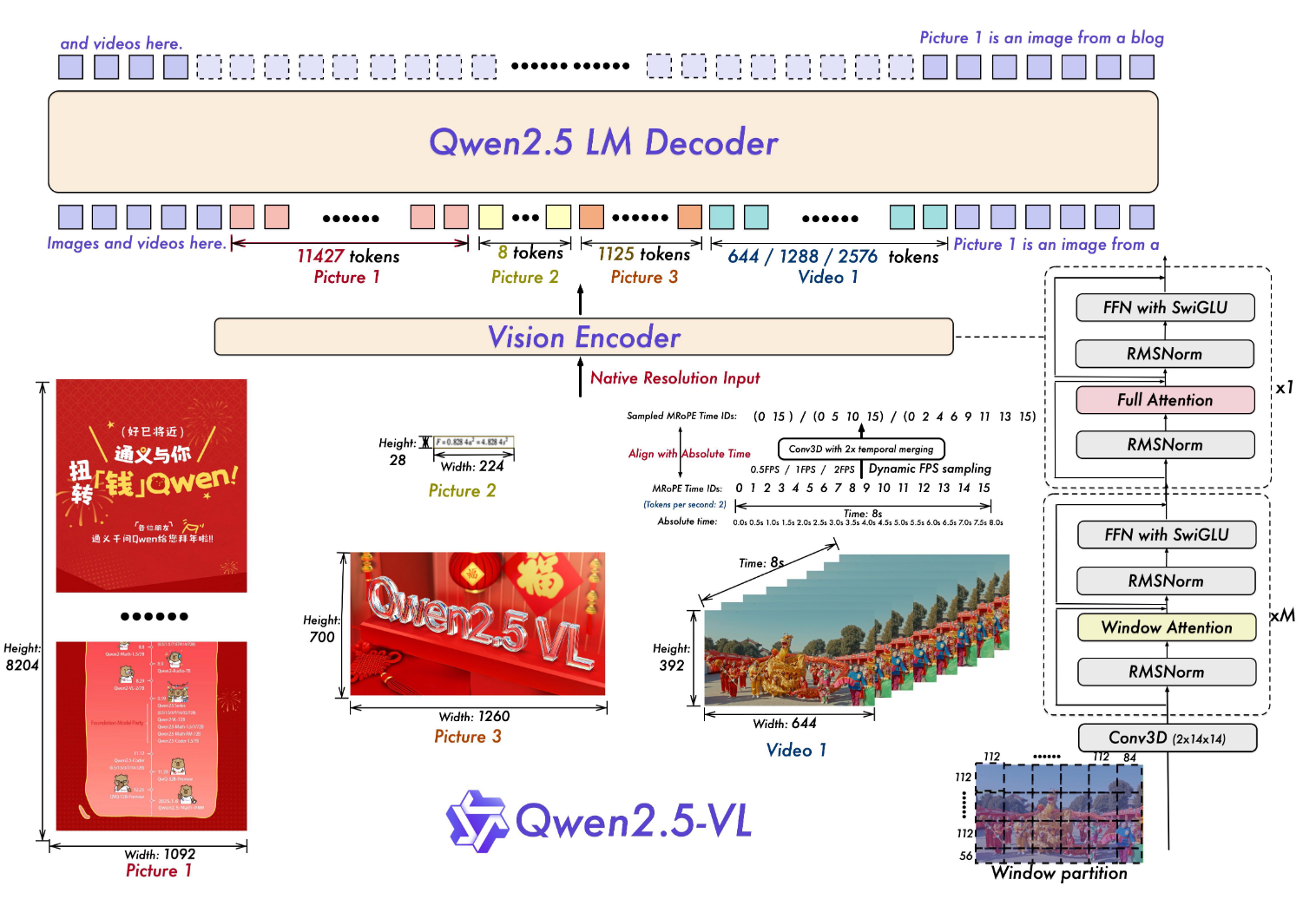
그림은 비전 입력(이미지/비디오)을 Vision Encoder로 처리한 뒤, Merger를 통해 LLM 토큰 공간으로 맞추고, Qwen2.5 LLM Decoder가 텍스트 출력을 생성하는 전체 파이프라인을 보여준다.
2.1. LLM
- Qwen 2.5 LLM의 가중치 활용
- 1D RoPE → 절대시간에 맞춘 MRoPE(Multimodal Rotary Position Embedding) 변경
2.2. Vision Encoder(ViT)
- 2D-RoPE와 window attention으로 어떤 해상도가 들어와도 그대로 지원가능하며 계산도 빠름
- width, height을 28의 배수로 조정 및 stride 14의 패치로 분할하여 처리
2.3. MLP 기반 Vision‑Language Merger
- 공간적으로 인접한(상하좌우) 4개 이미지 패치를 그룹화
- 2계층 MLP를 통과하여 LLM 텍스트 임베딩과 차원을 일치시킴
2.4. 모델 layer 구성

3. Vision Encoder

3.1. 주요 특징
- 오직 4개 layer만 전체 self-attention 수행
- 나머지 layer는 최대 112x112 사이즈(8x8 패치)만 attention 수행(window attention)
- 위치 인코딩 2D RoPE
- 픽셀의 좌표계를 통해 공간적 관계 이해
- 비디오 처리를 위한 3D 패치화
- 기본 단위는 14x14 이미지 패치로 동일
- 연속된 두 프레임을 하나로 묶어서 처리
- LLM 스타일로 ViT 재설계
- 정규화: LayerNorm → RMSNorm
- 활성화 함수: GELU → SwiGLU
3.2. 동적 해상도와 Frame Rate
- 이미지의 좌표를 정규화 하지 않음
- 기존: “이 박스는 이미지의 0.2 ~ 0.3 영역”
- Qwen: “이 박스는 4000×3000 이미지에서 (1200, 500) ~ (1800, 900)”
- 프레임 순서가 아니라 실제 타임스탬프로 RoPE 수행
- 기존: 프레임 번호 1, 2, 3, 4
- Qwen: 0s, 0.1s, 0.4s, 1.2s
4. MRoPE Aligned to Absolute Time
시간(순서)축, 가로축, 세로축
- 텍스트
- 3개에 동일 값 할당
- 이미지
- 시간축 고정
- 각 패치에 맞게 가로, 세로 값 할당
- 동영상
- 절대 시간에 맞춰 시간 축 값 조정
- 각 패치에 맞게 가로, 세로 값 할당
5. 학습
5.1. Pre-Training
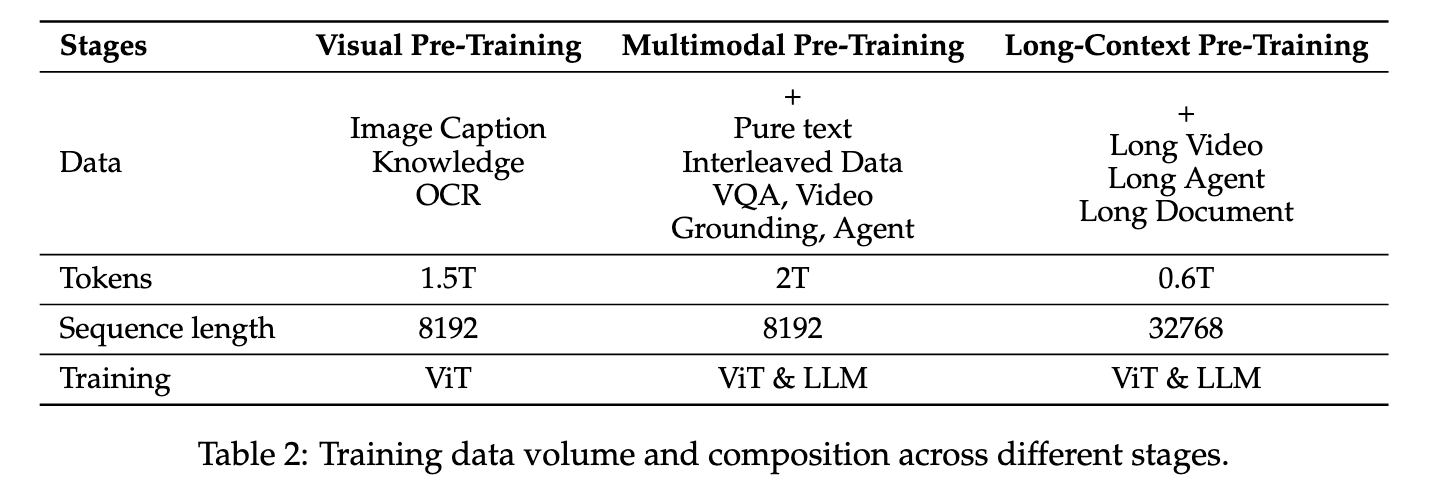
3단계로 나눠 비전 사전학습 → 멀티모달 사전학습 → 장문 컨텍스트 사전학습을 진행한다. 롱비디오/롱문서 이해를 위해 32K 컨텍스트까지 확장한다는 점이 핵심이다.
5.1.1. 데이터
- 4.1조 토큰의 데이터로 학습(이전보다 3배 증가)
- 양보다 질
- 인터넷 수집 데이터를 자체 제작 모델로 4단계로 검증해서 필터링함
- 문서 전체 파싱 데이터
- 문서를 위치 정보와 함께 하나의 통일된 html로 변환하여 파싱해서 데이터를 만들었음

- 다양한 형태의 비정형 데이터
- 지저분한 문서를 학습해서 변칙적인 구조에 대해서도 보완
- 이미지 Grounding data
- 이미지의 실제 픽셀 좌표를 통해 정밀도를 학습
- 문서를 위치 정보와 함께 하나의 통일된 html로 변환하여 파싱해서 데이터를 만들었음
5.2. Post-Training
- 2단계 학습
- SFT → DPO
- ViT는 파라미터 고정
- ChatML 포맷 적용한 데이터 쌍 200만개
- 텍스트 only 50%
- 멀티모달 50%
6. 성능 실험
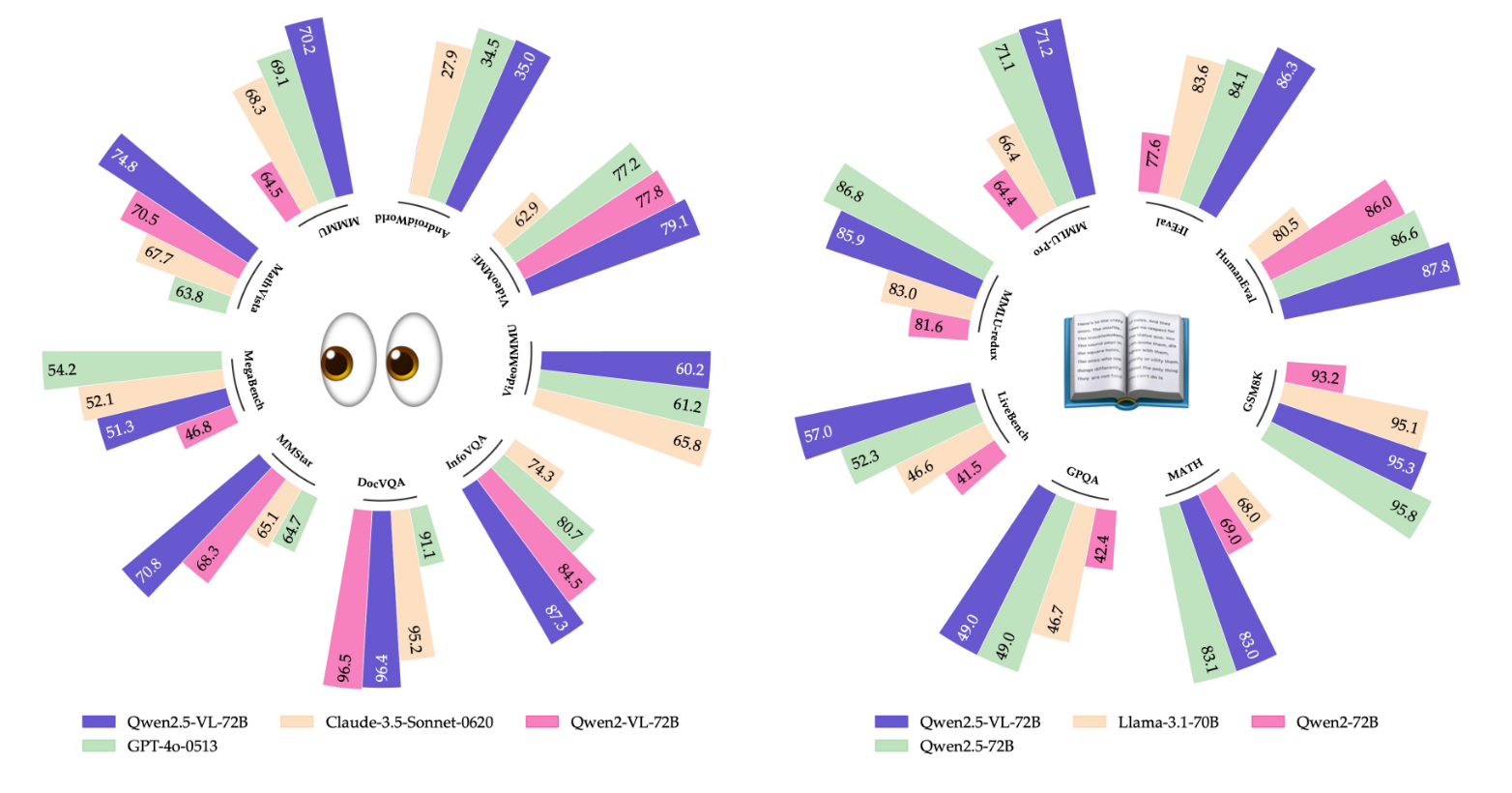
원형 차트는 다양한 벤치마크에서 Qwen2.5‑VL‑72B가 기존 모델 대비 높은 성능을 보임을 시각화한다.
6.1. SOTA와 비교
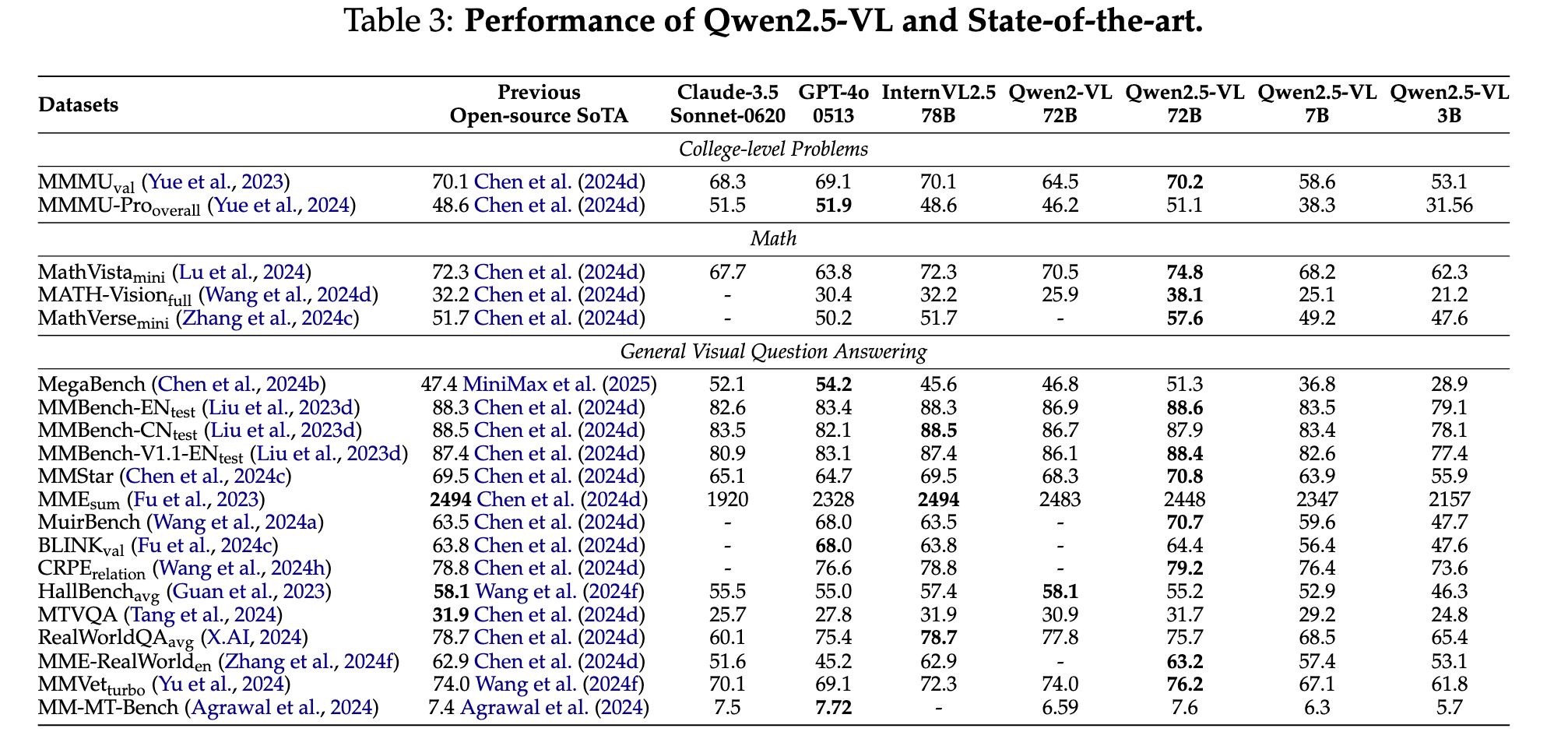
표 기준으로 Qwen2.5‑VL은 여러 시각‑언어 벤치마크에서 오픈소스 SOTA를 갱신하거나 경쟁력 있는 수치를 보인다.
6.2. 순수 텍스트 성능
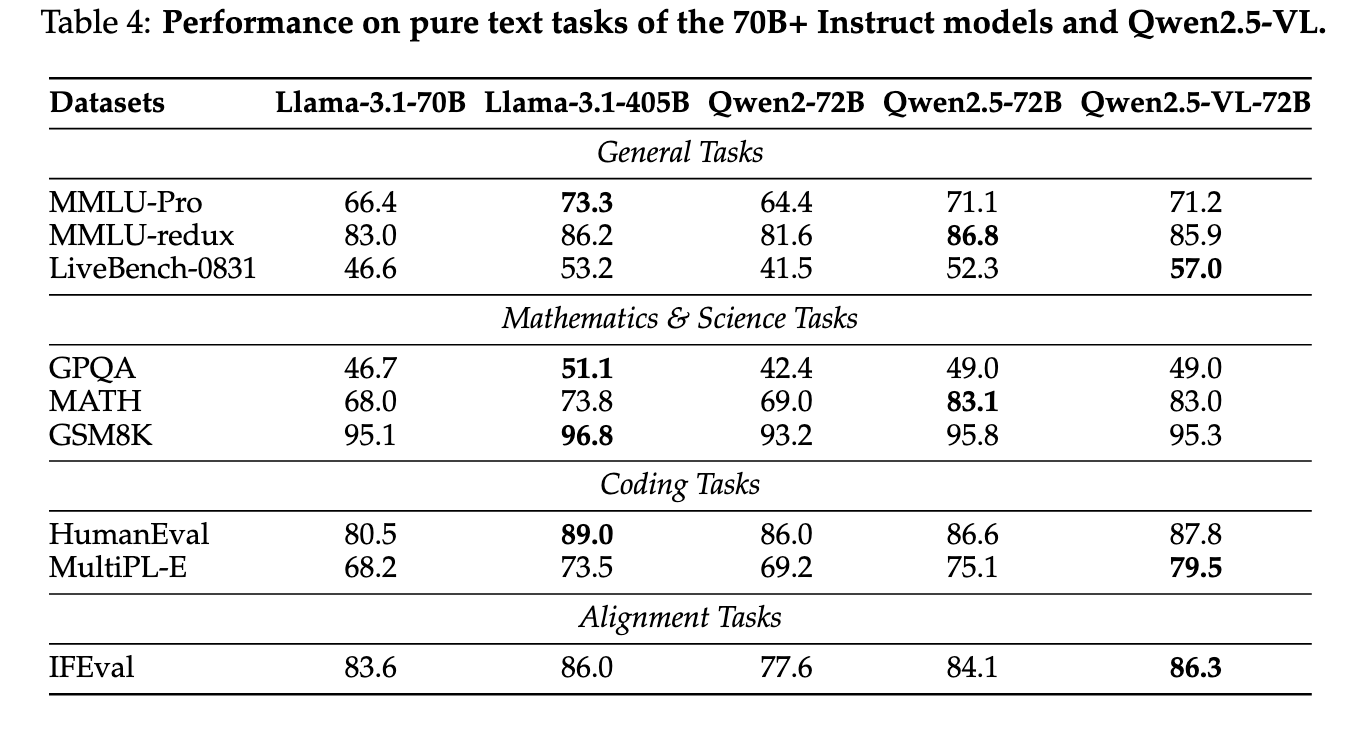
멀티모달 모델임에도 순수 텍스트 과제에서도 큰 손해 없이 경쟁력을 유지한다.
6.3. GUI Agent 성능
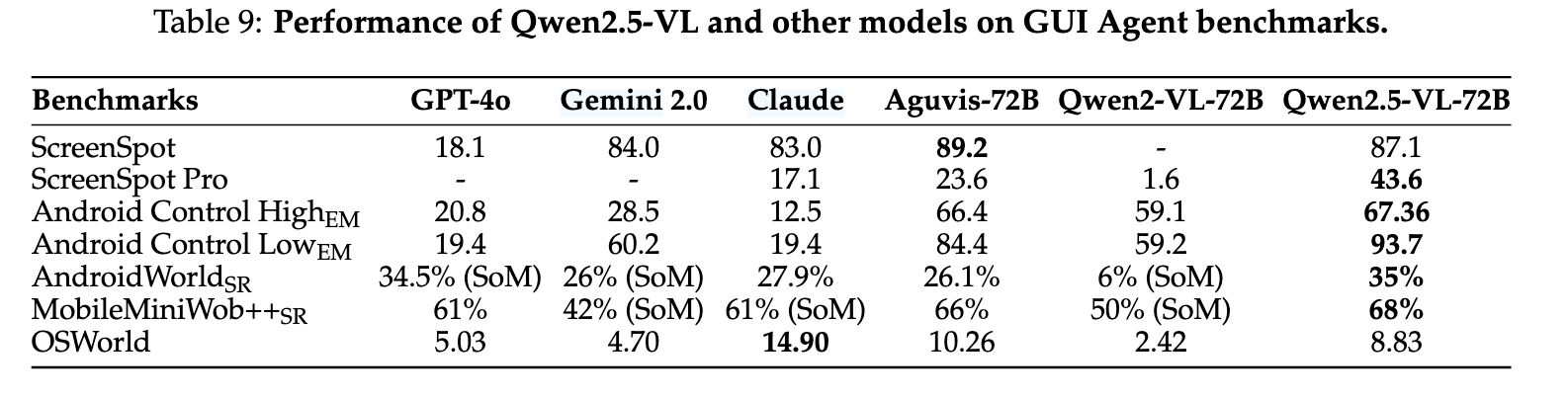
GUI 에이전트 벤치마크에서도 Qwen2.5‑VL‑72B가 상위권 성능을 기록한다.
7. 정리
Qwen2.5‑VL은 고해상도/롱비디오 처리, 절대시간 기반 MRoPE, 대규모 고품질 데이터를 결합해 멀티모달 이해 성능과 실용성을 동시에 끌어올린 모델이다. 특히 문서 이해와 장문 비디오 이해를 강조하는 점이 인상적이다.
A. 질문
- 비디오 처리할때 소리는 어떻게 함?
- Qwen 2.5 VL은 오디오 처리를 못한다 → 즉, 무음 처리
- Qwen 2.5 Omni 모델도 2025년 3월에 나왔는데 사운드 처리는 이쪽을 보자
- 컨텍스트 length 제한은 얼마임?
- 사전 학습시에 했던 것처럼 32768 token → 32K
- 몇시간 짜리 동영상도 볼 수 있다던데 ㄹㅇ?
- 동영상 프레임 제한은 768개
- 적절히 프레임 자르면 가능(2시간 7200초) → 10초
- 멀티모달의 chatml 형태가 궁금함
- Qwen 계열의 채팅 템플릿은 멀티모달 콘텐츠를
<|vision_start|>…<|vision_end|>로 감싸고, 이미지면<|image_pad|>, 비디오면<|video_pad|>같은 placeholder 토큰을 끼운다.
- Qwen 계열의 채팅 템플릿은 멀티모달 콘텐츠를
댓글남기기