
[Review] Qwen2.5-Omni Technical Report
Qwen2.5-VL을 정리한 뒤, 오디오까지 함께 다루는 모델이 어떻게 구성되는지 궁금해서 Qwen2.5-Omni Technical Report를 중심으로 스터디 내용을 정리했다.
논문 리뷰 - Weekly Tech Trend Talk 스터디(26.02.03)
1. Introduction
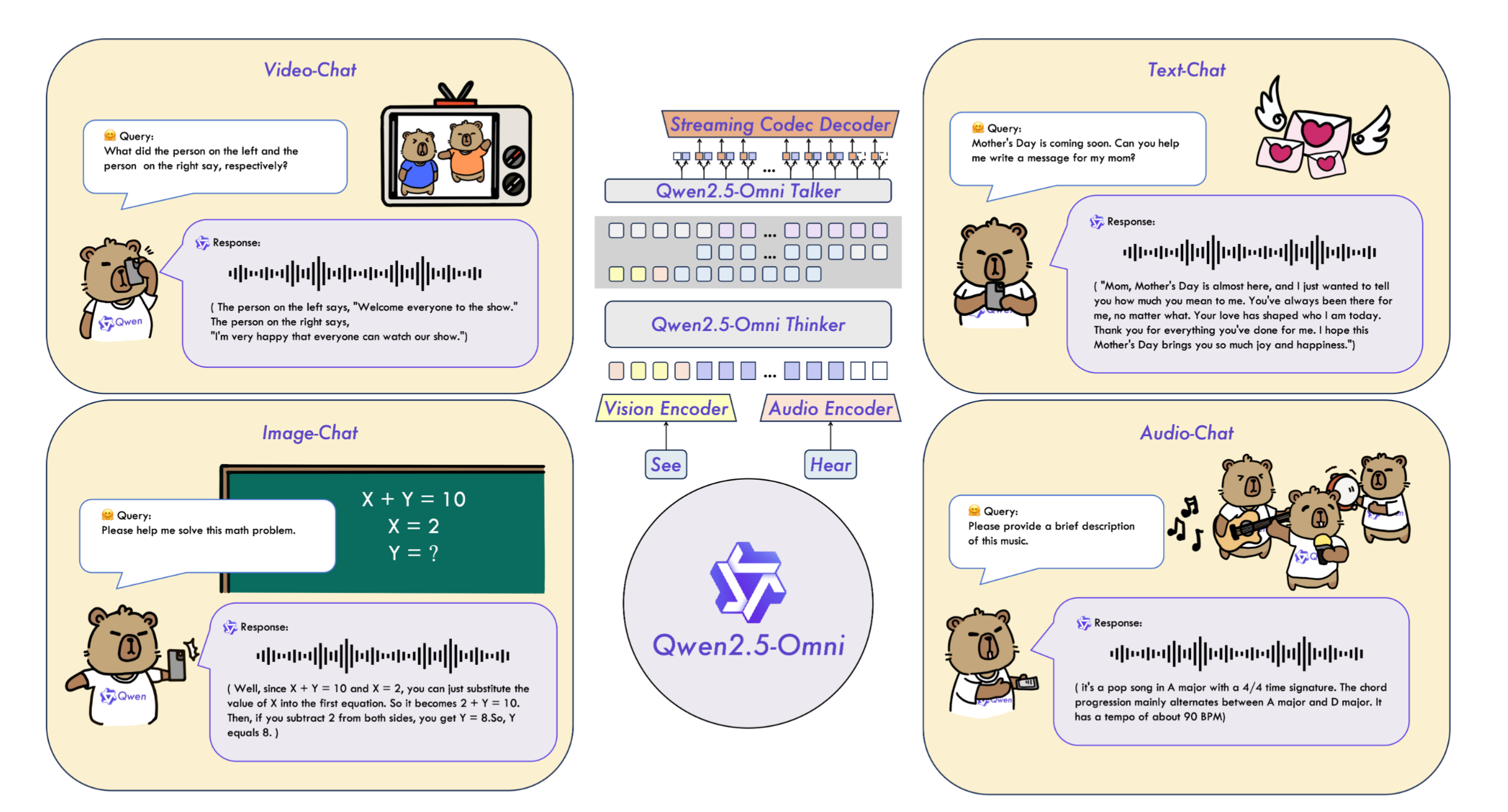
- TMRoPE: 오디오와 비디오 프레임을 interleave(하나씩 교차) 구조로 배치
- Thinker-Talker 구조
- 실시간으로 텍스트와 음성 신호를 생성하며, 음성 신호 토큰을 파형으로 변환하는 DiT 모델 추가 구현
2. Architecture
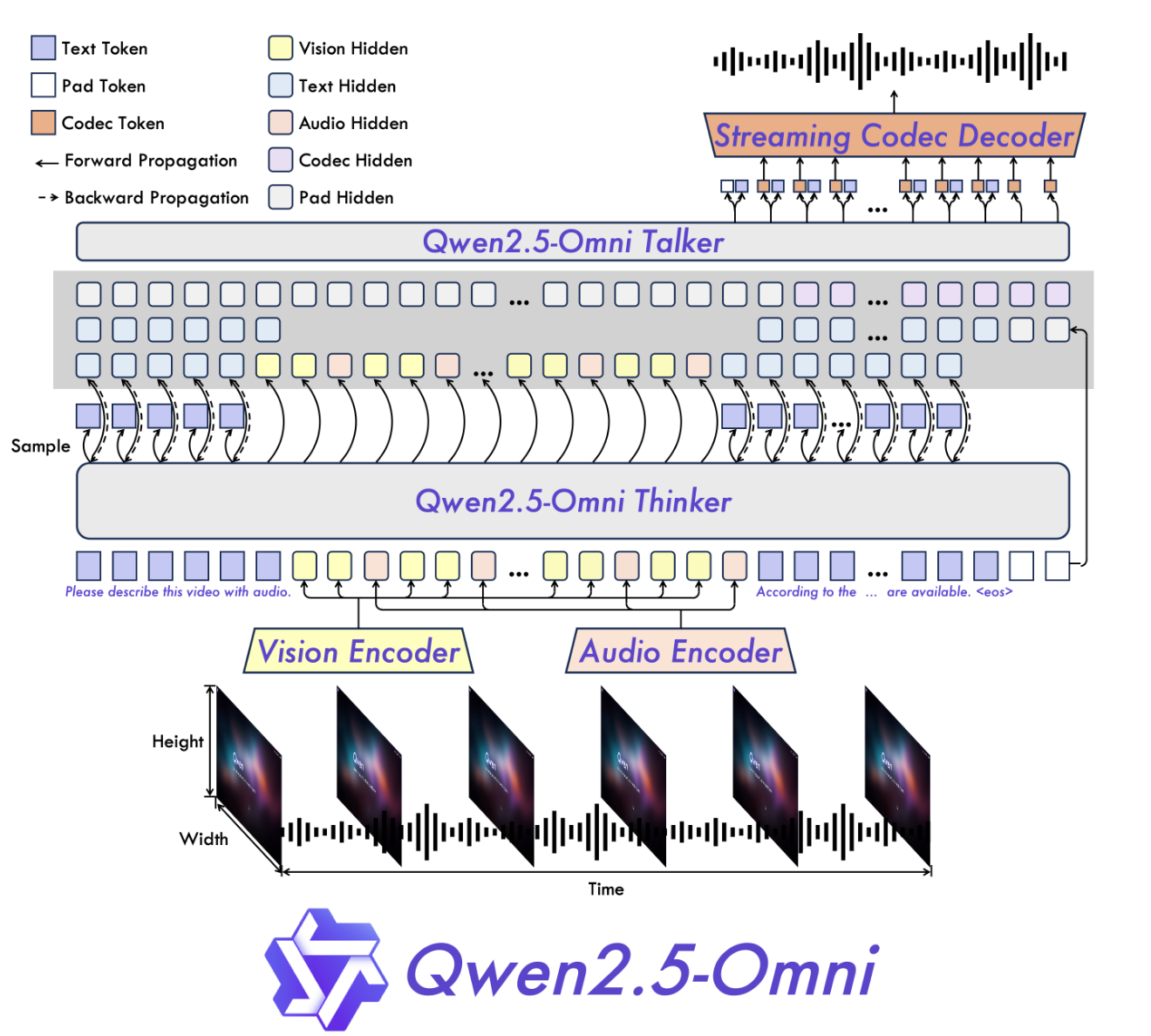
- Thinker의 경우, 일반적인 Transformer Decoder
- Talker
- Mini-Omni라는 모델의 구조를 참고
- 이중 트랙 autoregressive Transformer Decoder
2.1. 입력
- 텍스트: 151,643개의 토큰 vocab의 Byte Pair Encoding
- 오디오
- 16kHz 주파수로 재샘플링 및 원시 파형을 25ms의 윈도우 크기와 10ms의 홉 크기를 가진 128 채널 mel-spectrogram으로 변환
- 오디오 인코더의 각 표현 프레임이 원래 오디오 신호의 약 40ms 세그먼트와 일치하게 맞춤
- 이미지/비디오
- Qwen2.5-VL에서 사용한 675M 파라미터의 비전 인코더
- 오디오와 샘플링 속도를 맞추기 위해 동적 프레임 비율을 적용
- 이미지의 경우 일관성을 위해 동일한 2개 프레임으로 취급
2.2. TMRoPE
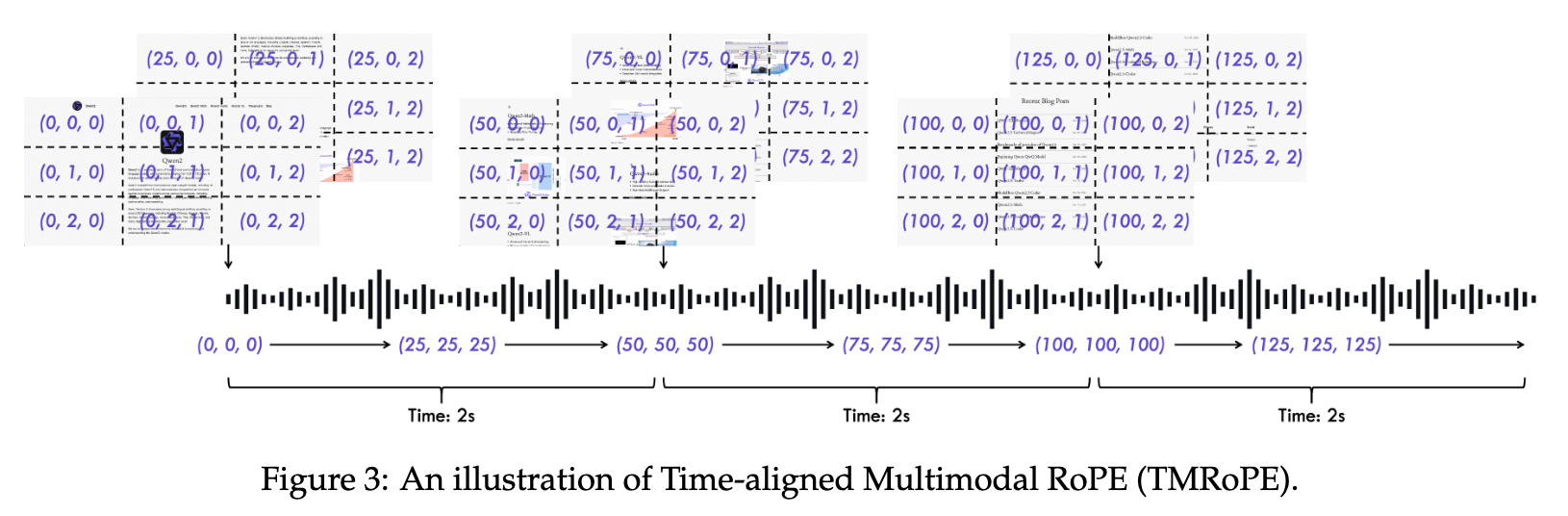
- 시간, 높이, 너비 세가지 구성 요소
- 하나의 시간 ID는 40ms
- 오디오와 비디오 정보를 동시에 받을 수 있기 위해 time-interleaving method를 사용
- 2초 단위의 청크로 쪼개서 앞에 시각 표현, 뒤에 오디오 표현을 배치하였음
2.3. 생성
- 텍스트
- Thinker 모델의 출력
- 일반적인 LLM 구조와 같음
- 음성
- Talker는 Thinker의 text token과 고차원 표현 값 모두 전달 받음
qwen-tts-tokenizer라는 음성 코덱으로 casual audio decoder로 음성 스트리밍 디코딩 가능- 음성 생성은 텍스트와 일치하지 않아도 되고, 타임스탬프 수준 정렬도 필요 없음
2.4. 음성 스트리밍
- Flow Matching DiT 모델을 활용
- 입력 코드는 Flow-Matching을 통해 mel-spectrogram으로 변환
- 이후, BigVGAN을 통해 파형으로 복원
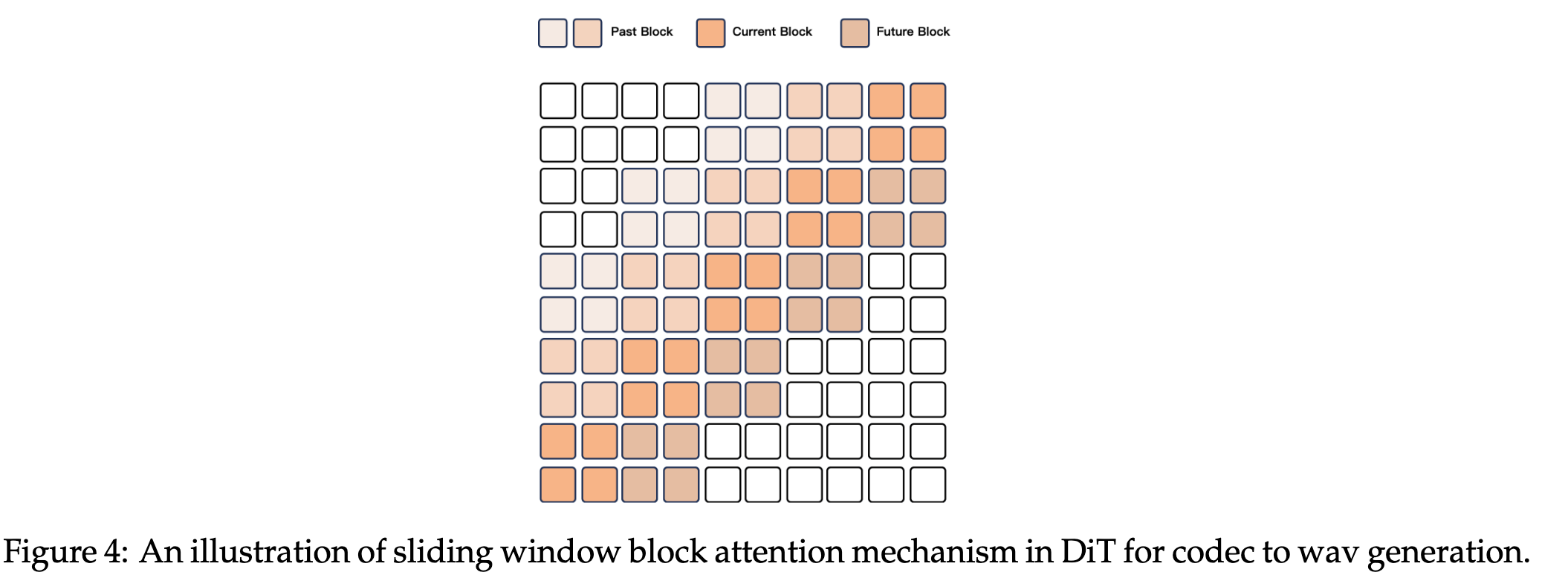
- DiT 수용 영역을 4개로 제한(2개의 과거 블록(lookback)과 1개의 미래 블록(lookahead) 포함)
3. 훈련
3.1. Pre training
- 모델 초기화
- LLM: Qwen 2.5
- Vision Encoder: Qwen 2.5 VL
- Audio Encoder: Whisper-large-v3
- 훈련 단계
- 1단계: 인코더들만 학습
- 2단계: 전체 학습(8k 토큰 까지만)
- 3단계: 32k 까지 context window 늘려서 학습
3.2. Post training
3.3.1. ChatML Format

Post Training에서부터는 ChatML 형태로 학습이 이루어진다.
3.3.2. Talker
- context continuation 학습: 모델의 음성이 말하다가 바뀌지 않도록 학습
- DPO를 통한 음성 생성 안정성 훈련: 노이즈/발음 오류를 줄이기 위한 강화학습 추가
- multi-speaker instruction fine-tuning으로 자연스러움 훈련
4. 평가
Omni 모델 평가는 크게 2가지 분류로 나뉘며, 그 안에서도 세부 분야가 다양하다.
- Understanding( X → Text)
- Text → Text
- Audio → Text
- Image → Text
- Video(w/o Audio) → text
- Multimodality → Text
- Speech Generation(X → Speech)
- Zero Shot Generation
- Single-Speaker Speech Generation
4.1. Text → Text
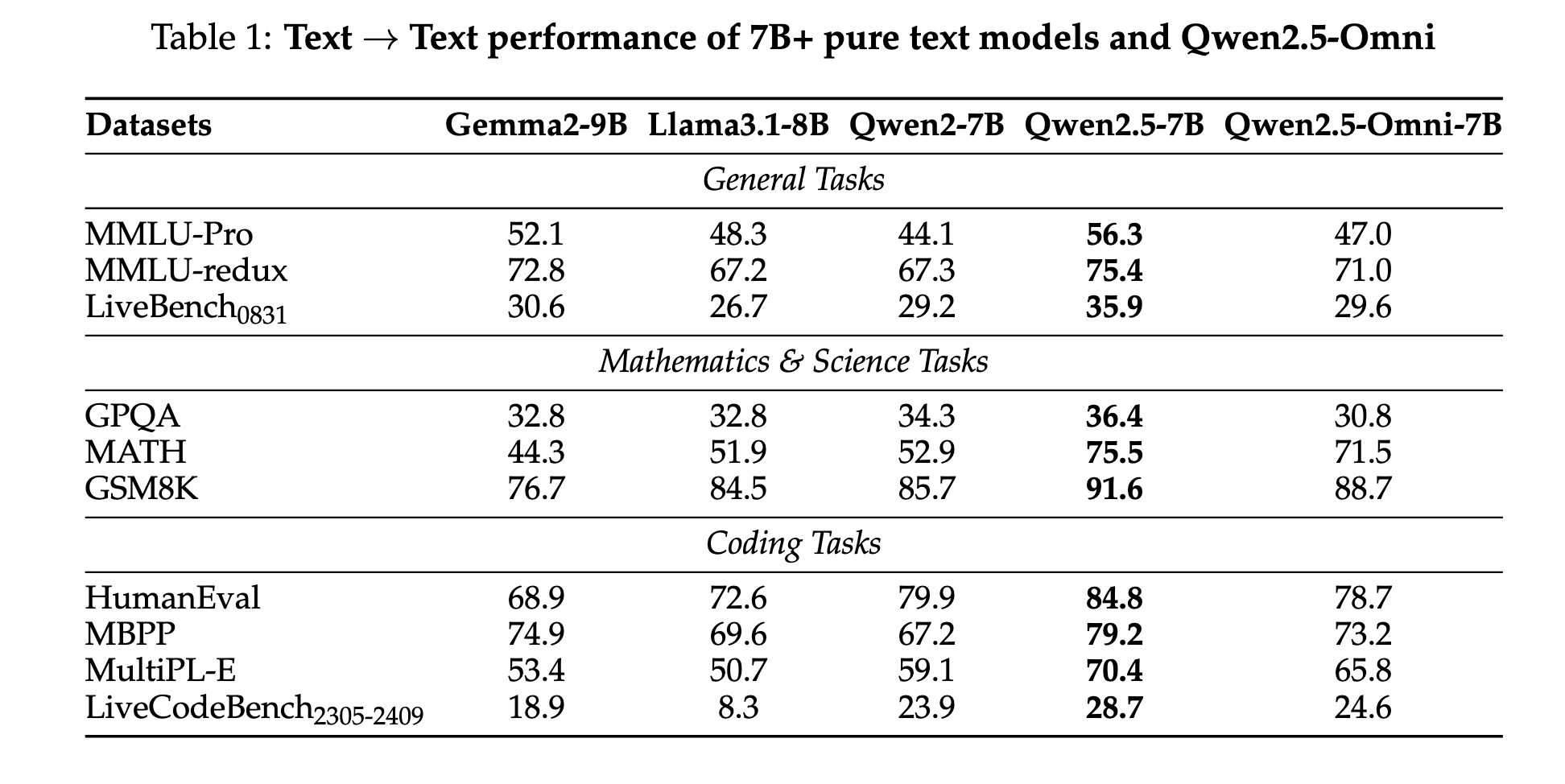
- Qwen 2와 Qwen 2.5의 사이
- Omni가 텍스트 only보단 성능이 떨어지지만 그래도 준수하다.
4.2. Audio → Text
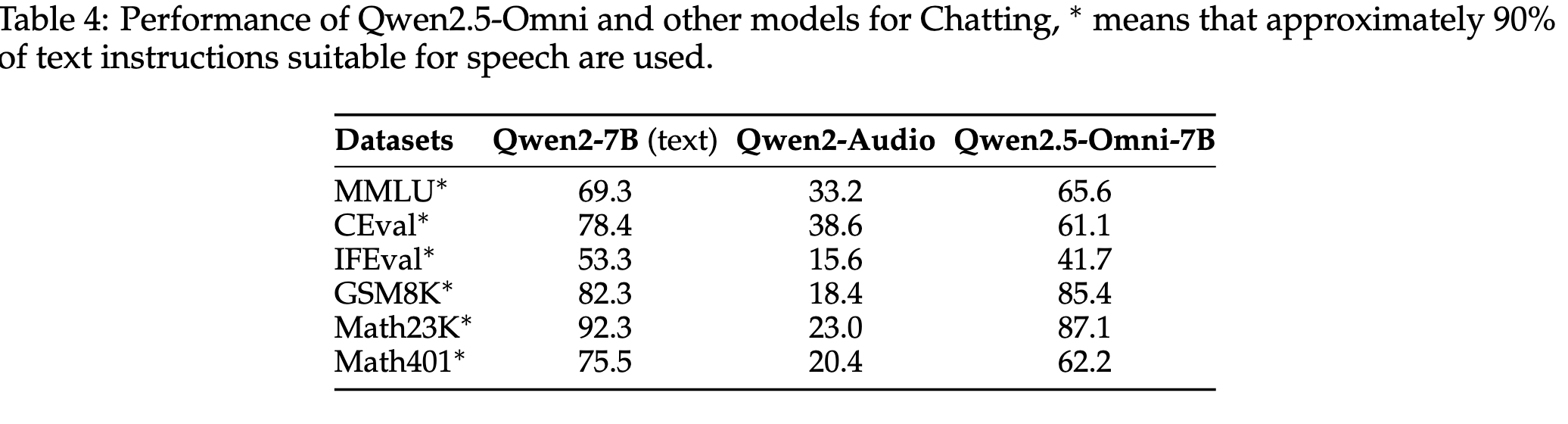
- Qwen Audio보다 성능 많이 좋아짐
- Qwen2-7B는 음성 대신 text script로 평가한 점수
4.3. Multimodality → Text
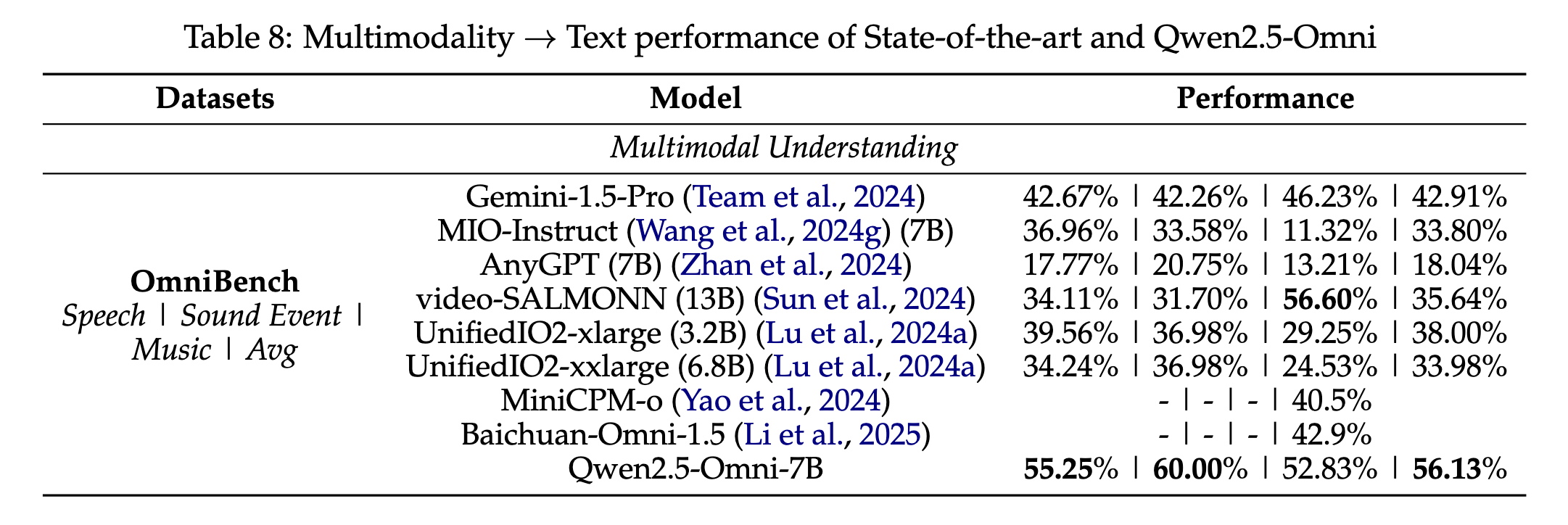
- 비슷한 파라미터 크기의 모델들과 비교했을 때 최고 성능에 가깝다
4.4. Single Speaker Speech Generation
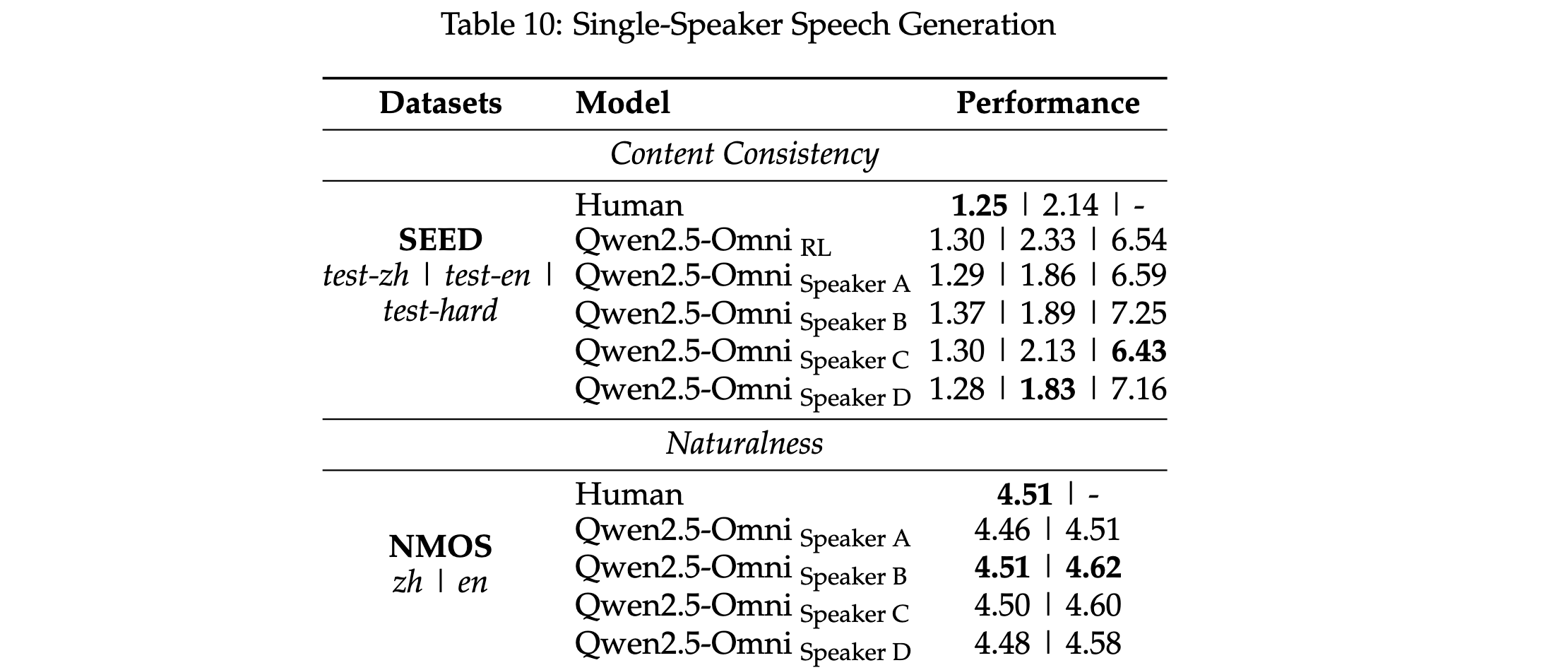
- 단일 speaker에 대한 파인튜닝한 결과
- NMOS를 보면 사람보다도 이긴 경우가 존재
- 인간 수준의 품질에 근접했다고 볼 수 있음
궁금했던 포인트
1. 비디오와 오디오를 2초 단위 interleave로 배치할 때, 정확히 어떤 Position Encoding이 들어가는가?
Transformer는 기본적으로 순서불변이지만, Decoder 모델의 Casual Mask 때문에 앞에 위치한 토큰들만 볼 수 있다는 제약이 존재한다. 따라서 Position Encoding 외에도 배치 순서가 영향을 끼칠 수 있다.
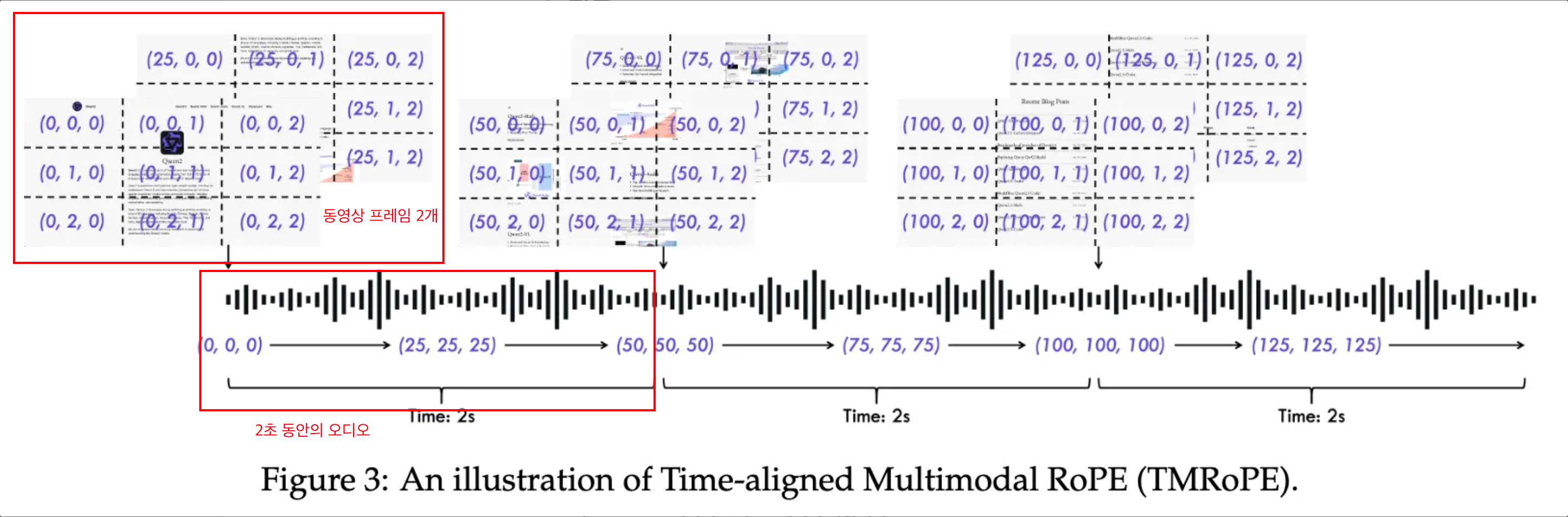
위 Figure의 의미를 제대로 분석해보자.
- 위 figure는 동영상이 초당 1프레임인 상황이다.
- 2초 단위에서 동영상의 이미지 프레임은 2개가 나온다.
- 이 이미지 프레임 2개를 먼저 배치하고, 그 뒤 2초 분량의 오디오들을 배치한다.
- 이때 오디오는 40ms 단위로 총 50개 배치된다.
- Figure 상의 격자로 표기된 좌표들이 비디오 프레임의 Position Encoding이다.
- 오디오의 Position은 텍스트와 동일하게 1D RoPE로 (0,0,0)부터 (50,50,50)까지 높이축, 너비축에 시간축과 동일값이 할당된다.
2. Talker는 왜 이중 트랙으로 텍스트 token까지 예측하나? 이건 음성 출력 토큰의 자막인가?

그렇지 않다. 저 텍스트 토큰들은 실제 추론과 관련 없는 학습 안정성을 위한 구조이다. 의미는 같지만 발음이 다른 단어로 혼동하지 않도록 텍스트 토큰을 이중트랙으로 가져간다. 생성하는 오디오 코덱 토큰은 텍스트 토큰과 1대1 매핑되지 않으며 별개로 Autoregressive하게 예측된다.
아마도 학습 시에 저 텍스트 토큰은 Thinker와 같이 정답 텍스트를 예측하도록 학습될 것이다.
3. Talker가 Autoregressive하게 예측할 때 Thinker의 출력은 어떤 식으로 전달되어 입력으로 들어가나?
Hugging Face Transformers 구현에서는 Thinker의 generate()가 끝난 뒤 Talker가 시작된다.
이때 Thinker의 출력(텍스트 토큰의 embedding, hidden state)은 아래 순서로 Talker에 입력된다.
- Thinker 전체 생성 완료: Thinker가 생성한 토큰과 각 토큰의 hidden state를 확보한다.
- 토큰별 임베딩 + hidden state 결합: 각 토큰에 대해 token_embedding + hidden_state를 더한 벡터를 만든다.
- Talker 초기 입력 시드 구성
- 프롬프트 구간(thinker의 첫 덩어리)은 talker의 첫 입력 시드에 직접 붙는다.
- thinker가 생성된 응답 구간은 thinker_reply_part로 분리된다.
- Talker AR 생성
- Talker는 매 스텝마다 현재 codec 토큰 임베딩에 thinker_reply_part의 첫 토큰 벡터를 더해 입력으로 사용한다.
- thinker_reply_part는 한 토큰씩 소비되며 다음 스텝으로 넘어간다.
4. 학습할 때 다음 토큰 예측을 하니까 이미지 토큰도 예측 가능하도록 학습된 것 아닌가? 이러면 이미지 생성도 가능한가?
그렇지 않다. 이미지·비디오·오디오 같은 멀티모달 입력 구간은 LLM(Thinker)의 next-token CE loss 계산 대상에서 제외되도록 label masking(혹은 loss masking) 된다. 따라서 Thinker는 텍스트 토큰에 대해서만 CE loss로 학습되며, 멀티모달 입력은 텍스트 예측을 위한 조건(컨텍스트) 로만 사용된다.
5. Omni 모델 파라미터 크기는?
7B이다.
6. DiT(Diffusion Transformer)가 뭘까?
DiT(Diffusion Transformer)는 확산(여기서는 Flow Matching) 방식의 denoising 생성 모델을 Transformer로 구현한 것이다. Qwen2.5-Omni에서는 스트리밍을 위해 Talker가 생성한 speech/codec 토큰(code)을 입력으로 받아 Flow-Matching DiT가 mel-spectrogram을 chunk 단위로 생성하고, 최종 파형(waveform) 복원은 BigVGAN이 담당한다.
- mel-spectrogram: 파형을 시간-주파수로 요약한 “소리 설계도”
- BigVGAN: mel-spectrogram → waveform을 만들어주는 보코더(vocoder)
7. 오디오 입력이 어떤 식으로 변환되는지 정확한 과정 이해 안됨
원문: 16kHz 주파수로 재샘플링 및 원시 파형을 25ms의 윈도우 크기와 10ms의 홉 크기를 가진 128 채널 mel-spectrogram으로 변환
- 16kHz 주파수로 재샘플링
- 16kHz는 1초당 16,000 샘플
- 오디오가 44.1kHz든 48kHz든 제각각일 수 있는 걸 통일시켜준다는 뜻
- 25ms 윈도우 크기
- 즉, 하나의 윈도우에 400 샘플이 나오게 됨
- 10ms 홉
- 0ms ~ 25ms를 본 뒤, 10ms ~ 35ms를 본다는 뜻
- 즉, overlap을 의미
- 128 채널의 mel-spectrogram
- 주파수를 128구간으로 나눔
- 각 구간 별로 주파수별 에너지를 계산
이렇게 만든 mel-spectrogram(10ms hop으로 생성된 시간 프레임들) 이 오디오 인코더에 입력되고, 오디오 인코더 내부의 다운샘플링(stride/pooling) 을 거치며 출력 시퀀스의 시간 해상도가 줄어든다. 그 결과 인코더 출력의 각 프레임(연속 표현 벡터) 이 원본 오디오의 약 40ms 세그먼트 에 대응하도록 맞춰진다.
후기
처음에는 VLM이 비디오를 이해한다고 하면 소리까지 함께 처리한다고 생각했다. 하지만 Qwen2.5-VL이 시각 정보 중심 모델이라는 점을 확인하면서, 오디오까지 다루는 Omni 모델에 더 관심이 생겼다.
이미지 데이터가 어떤 형태로 모델에 전달되는지는 어느 정도 알고 있었지만, 소리가 어떤 자료형으로 변환되어 입력되고 모델이 이를 어떻게 인식하는지는 특히 궁금했다. 이번 스터디를 통해 그 흐름을 조금 더 구체적으로 이해할 수 있었다.
다만 mel-spectrogram처럼 처음 접한 용어가 많아서 쉽지는 않았다. 그래도 전체적인 큰 개념을 잡을 수 있었던 점은 분명 의미 있었다.
댓글남기기