
[Review] I-JEPA:Self-Supervised Learning from Images with a Joint-Embedding Predictive Architecture
Meta의 얀 르쿤은 LLM(생성형 모델)만으로는 AGI에 도달하기 어렵다고 보고, 생성 중심 패러다임을 넘어 월드 모델을 연구하고 있다. 그 흐름 속에서 VL-JEPA, V-JEPA 등이 등장했고, I-JEPA는 JEPA 시리즈의 시작점이 되는 이미지 자기지도 학습 논문이다.
Self-Supervised Learning from Images with a Joint-Embedding Predictive Architecture
논문 리뷰 - Weekly Tech Trend Talk 스터디(25.12.30)
기존 패러다임: 불변성 기반 vs 생성 기반
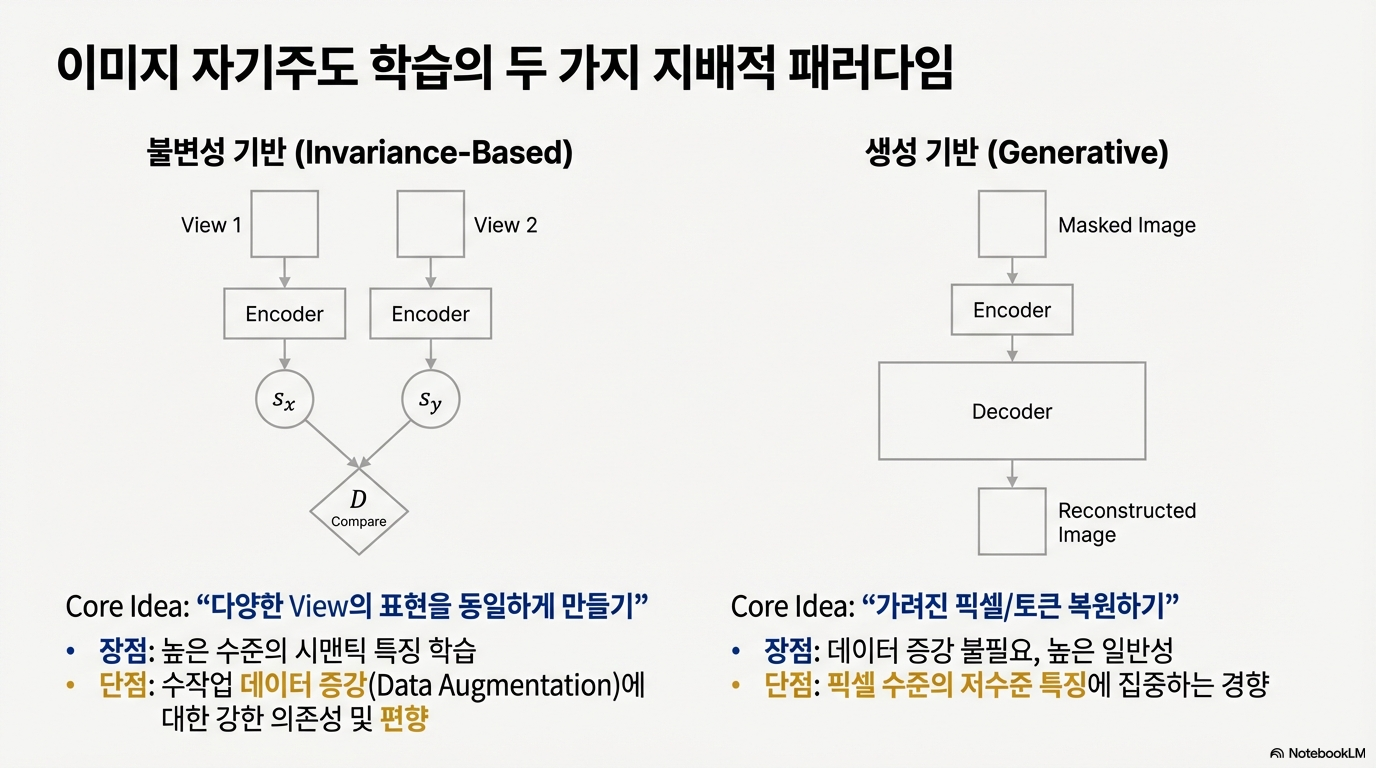
이미지 자기지도 학습은 크게 두 흐름으로 나뉜다.
- 불변성 기반(Invariance-Based): 서로 다른 뷰(View)의 표현이 같아지도록 학습한다. 높은 수준의 시맨틱 특징을 잘 잡지만, 강한 데이터 증강에 의존하고 편향이 생길 수 있다.
- 생성 기반(Generative): 가려진 픽셀/토큰을 복원한다. 데이터 증강이 크게 필요 없고 일반화가 좋지만, 픽셀 수준의 저수준 디테일에 과도하게 집중하는 경향이 있다.
사람은 전체적인 구조와 의미를 중요하게 보는데, 생성 기반 방식은 머리카락 한 올 같은 픽셀 복원에 계산을 쓰기 쉽다. I-JEPA는 이 지점을 문제로 보고 다른 방향을 제시한다.
I-JEPA의 접근법: 추상 표현 공간에서 예측
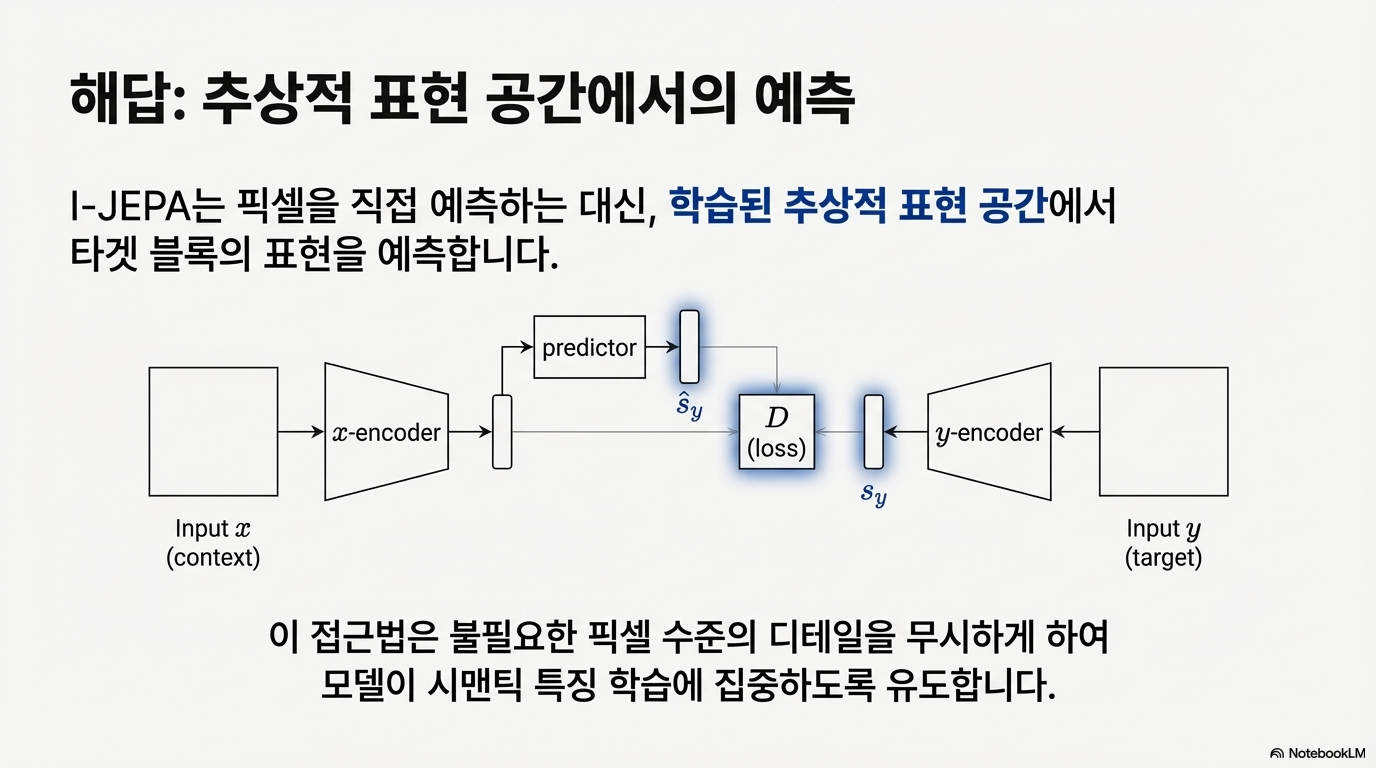
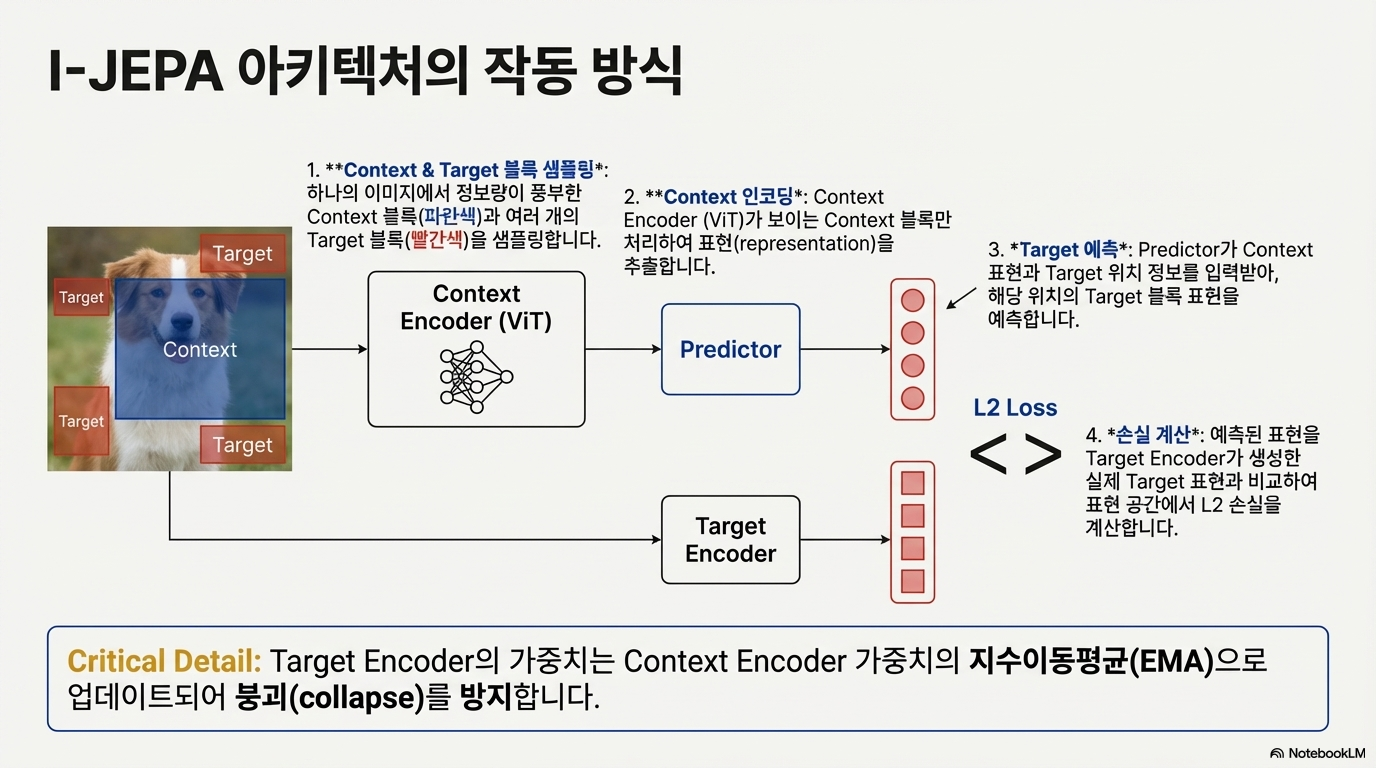
I-JEPA는 픽셀을 복원하는 대신, 가려진 영역의 추상적 표현(embedding)을 예측한다. 핵심은 “픽셀 공간이 아니라 표현 공간에서 맞추기”다.
- Target encoder: target 영역을 보고 의미(표현)를 만든다.
- Context encoder: context 영역만 입력받아 표현을 만든다.
- Predictor: context 표현과 target 위치 정보를 이용해 target 표현을 예측한다.
이때 Target encoder는 Context encoder의 EMA(지수이동평균) 가중치로 업데이트되어 표현 붕괴(collapse)를 막는다.
성능

첫 번째 그래프는 ImageNet-1K linear probing 결과다. 데이터 증강 없이도 기존 방법(MAE 등)을 능가하며, 스케일업 시에는 증강 기반 방법들과 동급 이상 성능을 보인다.
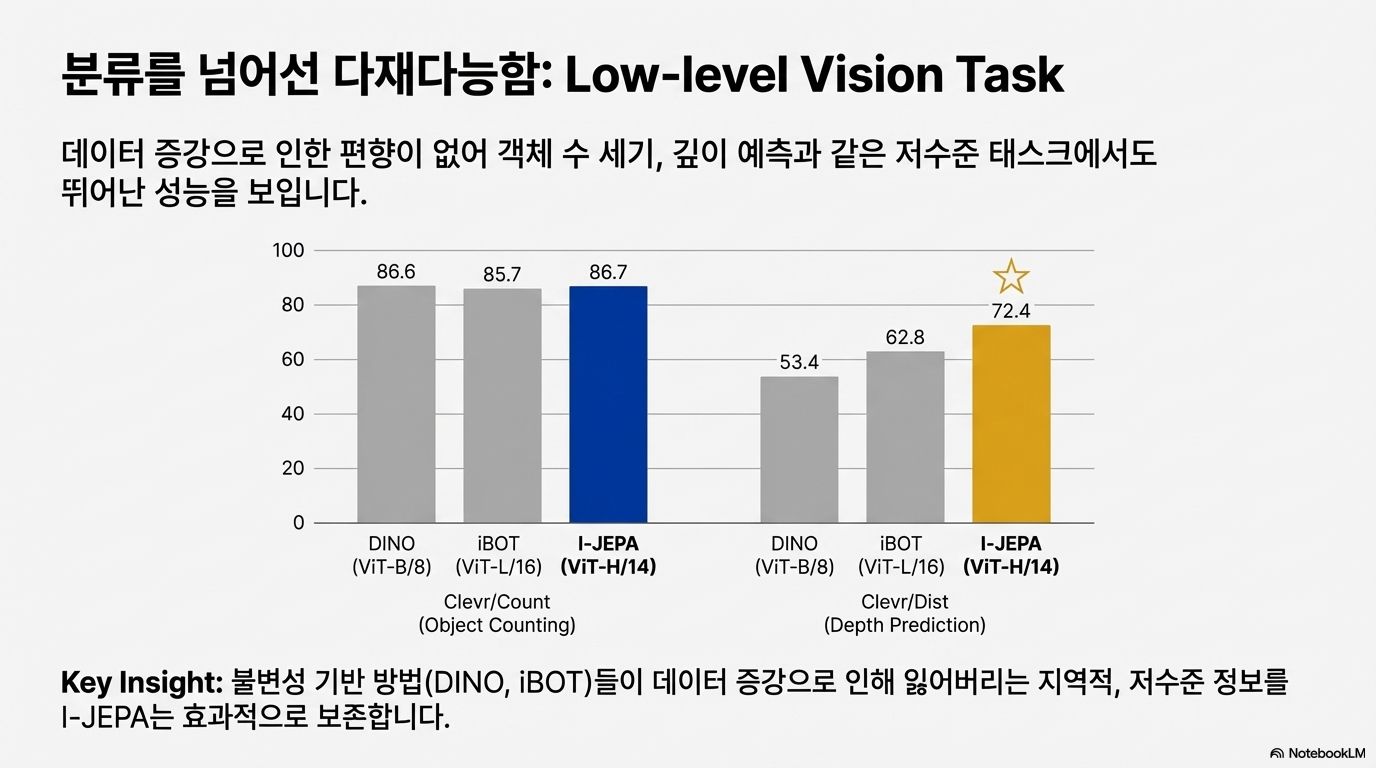
두 번째 그래프는 저수준 비전 태스크(객체 수 세기, 깊이 예측)로 확장한 결과다. 데이터 증강에 의해 손실되기 쉬운 지역적/저수준 정보를 I-JEPA가 더 잘 보존하는 경향을 보여준다.
결론: I-JEPA가 강조한 두 가지 설계
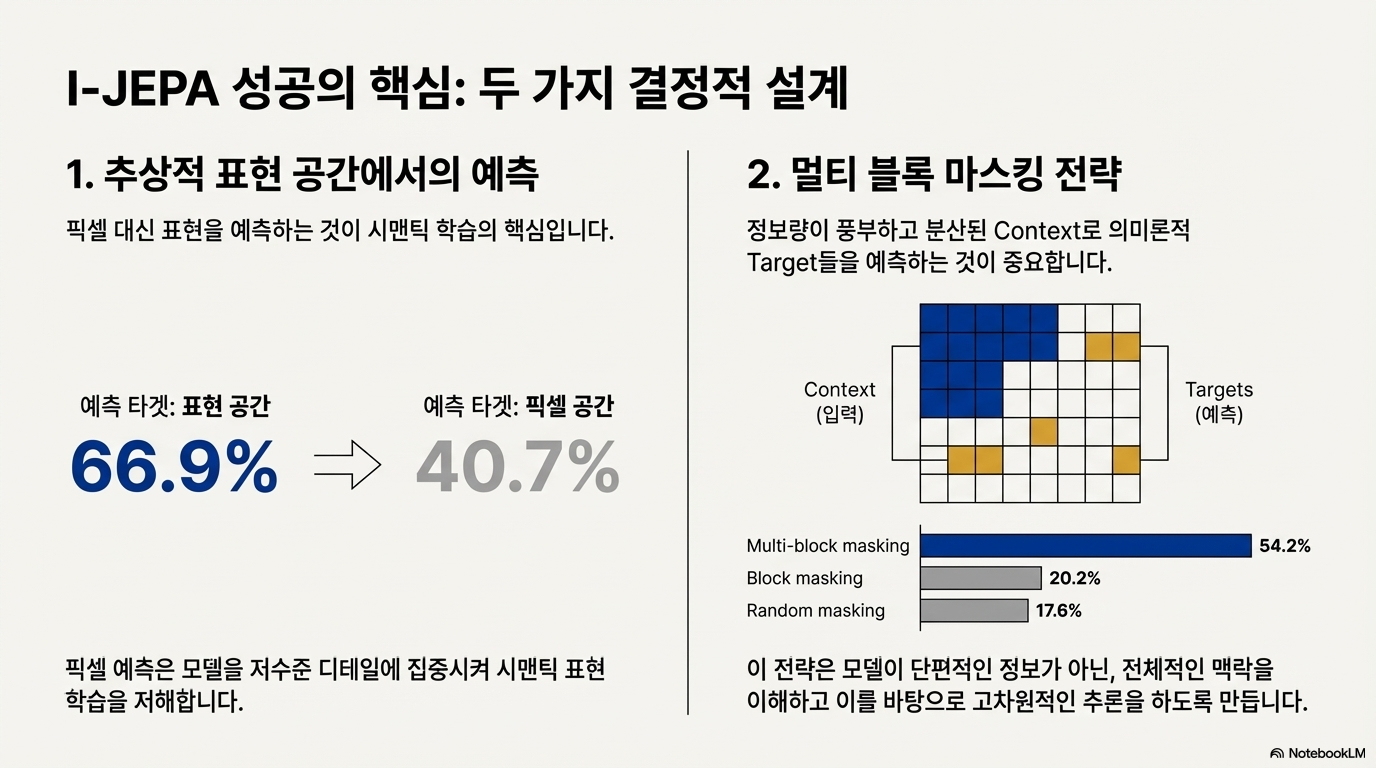
논문이 강조한 성공 요인은 두 가지다.
- 표현 공간에서의 예측: 픽셀 복원 대신 의미적 표현을 맞추게 해, 시맨틱 학습에 집중하도록 만든다.
- 멀티 블록 마스킹 전략: 여러 위치의 target을 동시에 예측해 전역 문맥 이해를 유도한다.
이 조합으로 데이터 증강에 대한 의존을 줄이면서도, 분류/저수준 태스크 모두에서 강한 성능을 보인다.
후기: 추가 의견
픽셀 수준이 정말 불필요할까?
JEPA는 결국 Auto Encoder처럼 입력을 더 작은 임베딩으로 압축한다. 이 과정에서 정보 손실은 불가피하다.
입력이 커질수록 손실되는 정보량도 커지고, 스케일링 법칙을 온전히 적용하기 어려울 수 있다.
그래서 현재의 생성형 모델들과 비교해 경쟁력이 떨어질 수 있다는 의문도 남는다.
댓글남기기