
[Review] Don’t Do RAG: When Cache-Augmented Generation is All You Need for Knowledge Tasks
이 논문은 “RAG 대신 CAG를 쓰자”는 주장이다. (Retrieval → Cache)
핵심은 KV Cache 재활용이다.
RAG가 검색된 chunk만 프롬프트에 넣는 반면, CAG는 대상 문서 전체를 프롬프트에 넣는다. 그리고 문서 전체가 들어간 프롬프트의 KV Cache를 미리 만들어 두고 재사용해 응답 시간을 크게 줄인다.
단, 모든 문서를 프롬프트에 넣기에는 컨텍스트 길이 한계가 있어 RAG를 완전히 대체하긴 어렵다.
Don't Do RAG: When Cache-Augmented Generation is All You Need for Knowledge Tasks
논문 리뷰 - Weekly Tech Trend Talk 스터디(25.12.08)
논문 리뷰
핵심 아이디어
요약하면 다음과 같다.
- 검색 대신 캐시: Retrieval 비용 대신 KV Cache를 활용한다.
- 문서 전체를 프롬프트에: 검색된 chunk가 아니라 대상 문서 전체를 입력으로 사용한다.
- 재사용 가능한 프리픽스: 동일한 문서 프리픽스를 가진 요청은 빠르게 처리한다.
RAG vs CAG 개념도
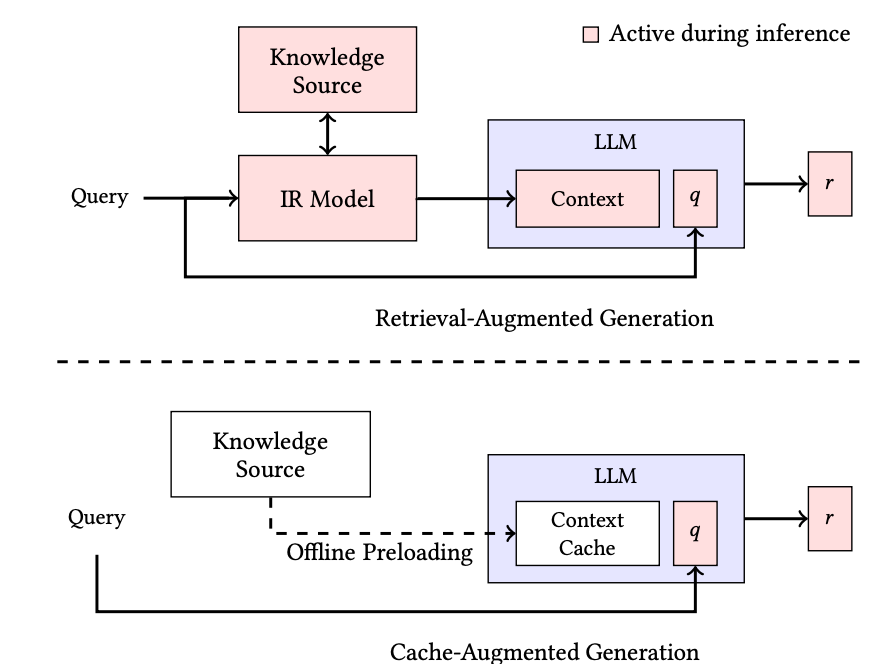
RAG는 검색한 뒤, 검색한 내용만 보고 생성이라면, CAG는 검색 없이 항상 검색 대상 전체를 보고 생성한다.
검색 대상 전체를 프롬프트에 넣기 때문에 추론 속도를 보장하기 위해 사전에 KV Cache를 만들어 둔다.
실험 세팅 - 데이터셋
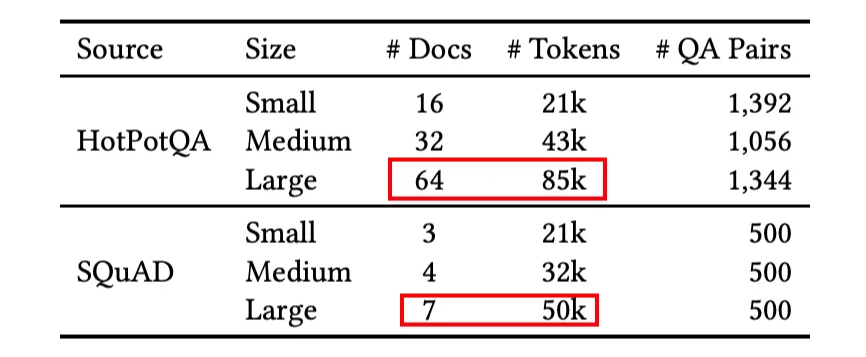
논문에서 사용한 데이터셋 목록이다.
Large 기준으로도 각 문서의 전체 토큰이 85K 수준이다.
결과 요약
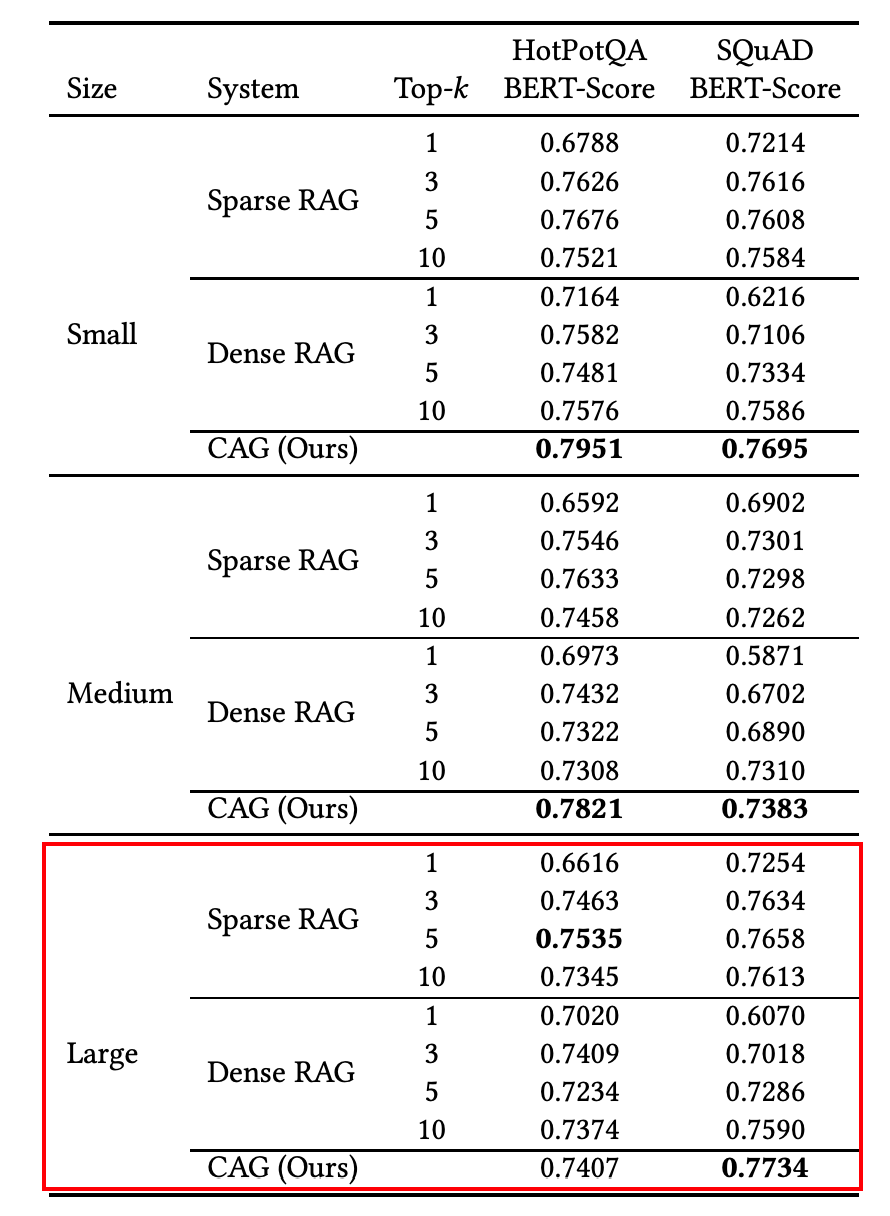
85K token을 넣은 HotpotQA에서는 CAG의 성능이 부족하기 시작한다.
컨텍스트 길이 한계에 가까워질수록 LLM 성능은 떨어질 수밖에 없다.
실행 시간(속도)
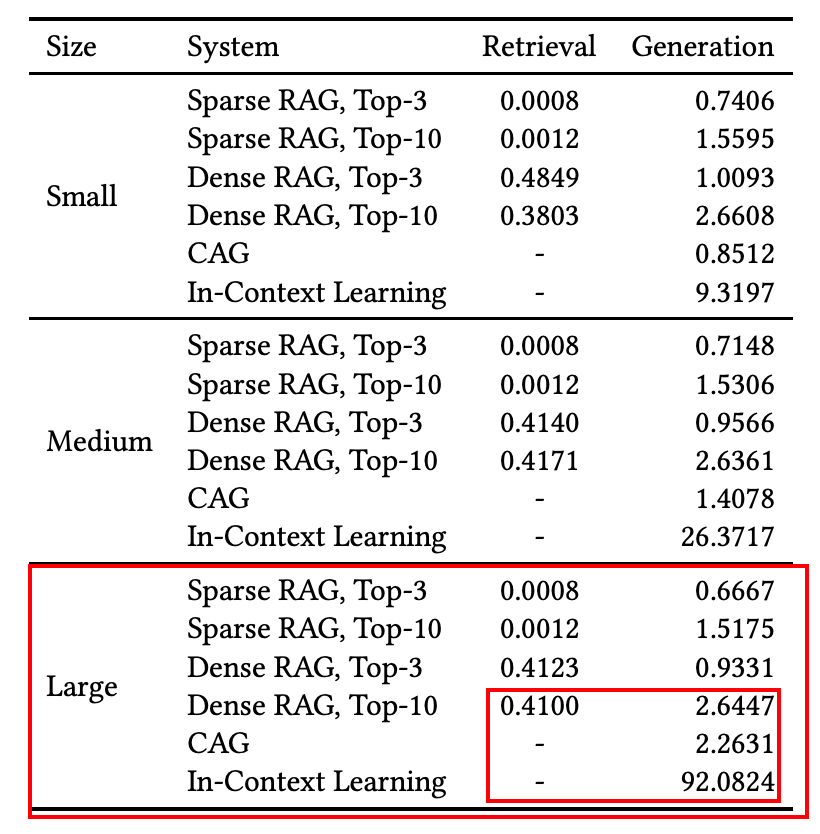
Dense top 10과 비교했을 때 속도가 더 빠르다.
In Context Learning은 Cache를 적용하지 않은 설정을 의미한다.
한계와 해석
- CAG가 성능적으로 강점을 보이는 구간은 문서 길이가 컨텍스트 길이의 50~70% 수준일 때다.
- 컨텍스트 길이 한계에 가까워질수록 성능이 하락한다.
- 모든 문서를 넣는 접근이라, 문서 크기/길이에 따라 적용 범위가 제한된다.
- 그럼에도 불구하고, 적절한 문서 길이의 경우 CAG를 사용하는 것에 장점이 있다.
- 자주 묻는 질문(FAQ), 핵심 매뉴얼 등 자주 참조되는 문서에 대해서는 CAG가 유리하다.
실전 활용
그렇다면 CAG를 실제로 활용하려면 어떻게 해야 할까?
로컬모델 - 직접 구현
모델 객체를 직접 다룰 수 있다면, KV Cache를 직접 재활용하는 방법이 있다. 이에 대한 방법은 라이브러리도 존재하고, 직접 구현도 가능하다.
로컬모델 - vLLM
하지만, 실무에서는 직접 llm 파라미티를 띄우고 추론하기보다는 vLLM 같은 llm 추론 엔진을 많이 활용한다.
이런 상황에서도 CAG를 활용할 수 있는 방법이 존재한다.
Automatic Prefix Caching - vLLM
python -m vllm.entrypoints.openai.api_server \
--model mistralai/Mistral-7B-Instruct-v0.3 \
--enable-prefix-caching \
--gpu-memory-utilization 0.9
- enable-prefix-caching 옵션으로 APC(Automatic Prefix Caching)를 사용한다.
- 동일한 prefix prompt에 대해 재활용이 가능해 CAG처럼 활용할 수 있다.
- 주의: KV Cache는 기본적으로 LRU(Least Recently Used)이므로 다른 요청이 많으면 캐시가 날아갈 수 있다.
로컬 모델이 아닌경우 - OpenAI Prompt Caching
https://platform.openai.com/docs/guides/prompt-caching
https://openai.com/index/api-prompt-caching/
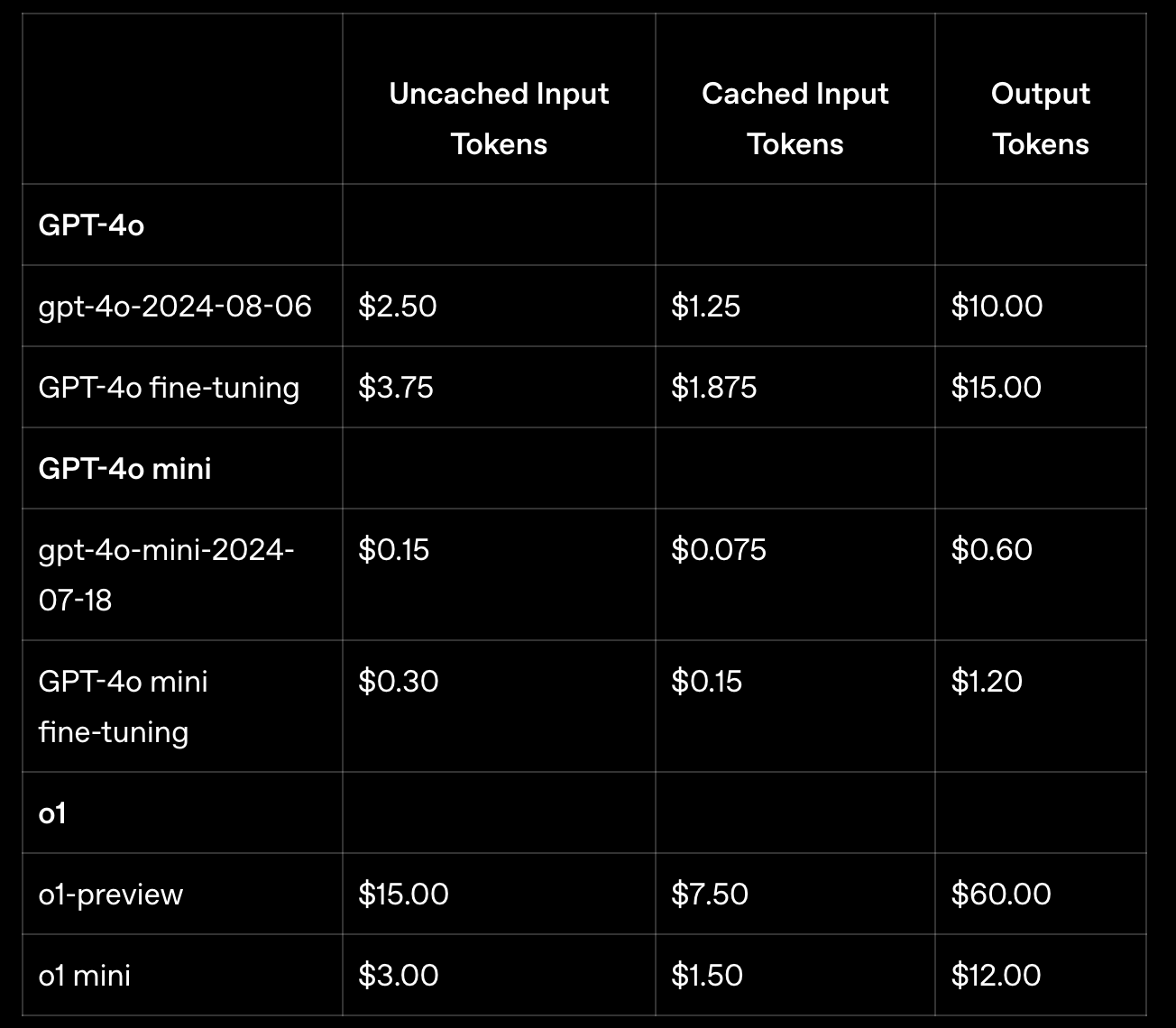
- 사실 개발자가 할 수 있는 건 거의 없다.
- 자동 적용되는 prompt caching이 사용되면 비용이 50% 감소하고 속도도 빠르다.
- 하지만 캐시는 빠르면 5분 후 삭제된다.
총 정리
CAG가 등장했을 때, RAG가 완전히 대체될 것처럼 여러군데서 화제가 되었었다. 하지만 CAG는 결국 모든 검색 대상을 프롬프트에 넣는다는 접근으로 검색 대상이 늘어나면 컨텍스트 길이 한계에 걸릴 수밖에 없다.(실제로 컨텍스트 길이 한계에 도달하면 성능이 급격히 떨어지는 결과가 존재한다.)
그렇다고 하더라도 CAG가 무의미한 것은 아니다. 항상 참조해야하는 문서, 자주 묻는 질문(FAQ) 등은 Prompt의 순서를 잘 설계하여 CAG를 활용할 수 있도록 함으로써, 성능과 응답속도 측면에서 모두 장점을 취할 수 있다.
변화되지 않는 페르소나 정보, 지침, CAG 대상 문서들을 프롬프트의 맨 앞에 두고, RAG 검색 chunk들, 세션 정보와 같은 매번 바뀌는 정보를 뒤에 배치하는 식으로 프롬프트를 설계하는 것이 좋은 예시가 될 수 있다.
댓글남기기