
[Review] BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
Bidrectional Encoder Representations from Transformers(BERT)는 unlabeled text로부터 좌우 문맥을 포함한 양방향 표현을 사전학습하게 설계된 모델이다. 또한, Question Answering, 언어 추론 같은 광범위한 작업에 대해 별도의 새로운 모델링 없이 단 하나의 출력 계층을 추가하고 finetuning하여 SOTA 모델을 만들 수 있다.
- 11개의 NLP task에서 SOTA 달성
- GLUE: 80.5%(7.7% 상승)
- MultiNLI 86.7%(4.6% 상승)
- SQuAD v1.1 93.2%(1.5% 상승)
- SQuAD v2.0 83.1%(5.1% 상승)
당시 최신 언어 표현 모델(ELMo, GPT)은 제대로된 양방향 표현을 학습하지 않음
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
들어가기에 앞서
Attention is All You Need(2017)에 이은 2018년도 말에 구글에서 나온 논문
GPT는 2018년 초에 발표
언어 표현은 참 깊은 역사가 존재하는 분야이다.
- 유사한 의미로 단어를 클러스터링하는 비신경망
word2vec,glove등 신경망 기반 접근법- 단어 단위가 아닌 문장 단위의 Sentence Embedding
- 개별 단어 임베딩이 아닌 문맥을 고려한 Context-sensitive Embedding
- ELMo, GPT 등
Context2vec - Melamud et al., 2016
bi-LSTM single layer로 단어를 예측하여 모델을 학습하였다.
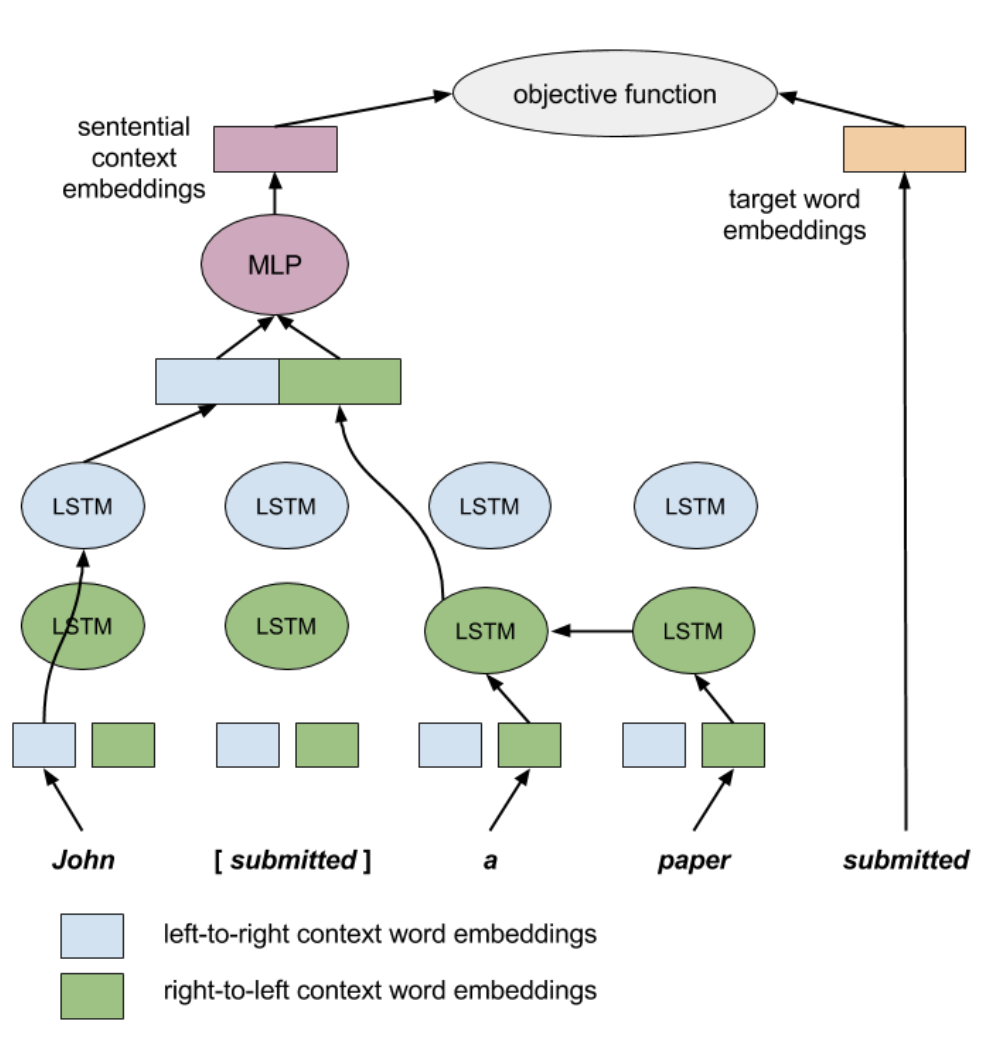
ELMo - Peters et al., 2018
forward, backward의 독립된 LSTM을 사용하여 다음 단어를 각각 예측하여 학습한다.
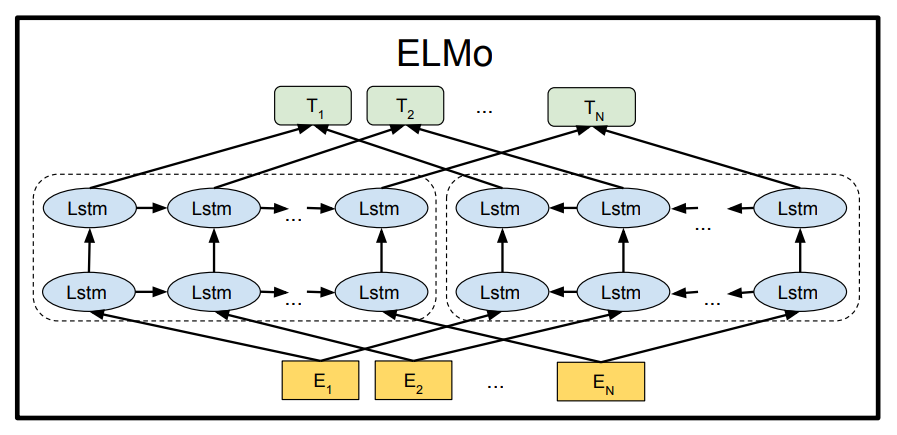
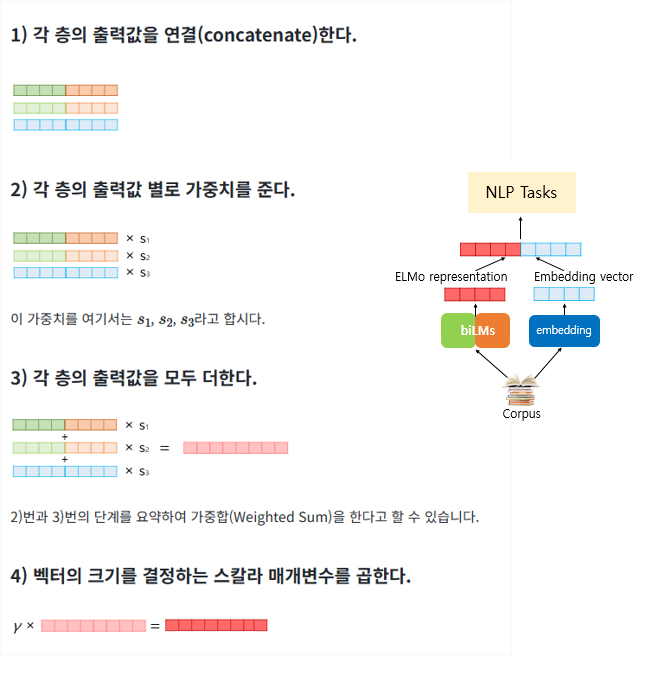
ELMo 모델의 파라미터는 freezing 하고 각 레이어의 반영 비율, 최종 벡터의 스케일링 변수 등 만이 downstream task에서 학습된다.
그 후 일반적인 word embedding과 concat되어져 downstream task에 사용된다.
Open AI GPT - Radford et al., 2018
Transformer의 Decoder를 사용한 모델로 left-to-right 언어 모델이다.
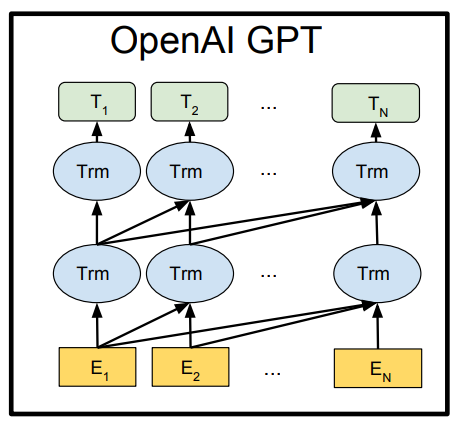
ELMo vs GPT vs BERT
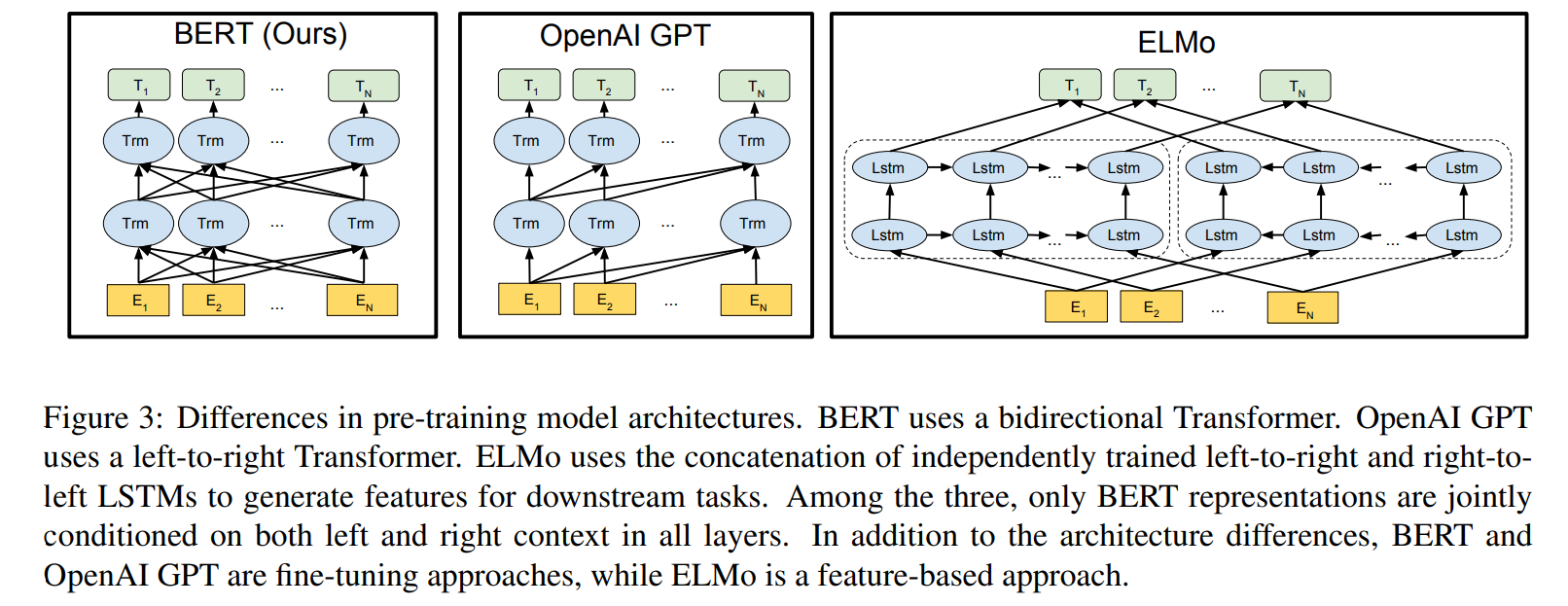
- ELMo
- 일견 양방향의 문맥을 고려한것 같지만
LTR,RTL에 대한 표현을 concat한 것이다. - Bi-LSTM을 다층으로 쌓아버리면 결국 해당 단어를 간접적으로 확인하게 되어버린다.
- 따라서 독립된 두개의 LSTM을 활용하였다.
- feature-based 접근으로 전이학습에서 ELMo 모델은 fine tuning 되지 않는다.
- 대신 임베딩 벡터를 입력으로 feature로 활용하여 task별 새로운 복잡한 모델을 학습한다.
- 일견 양방향의 문맥을 고려한것 같지만
- GPT
- Decoder 구조로 인한 masked attention으로 LTR 모델이다.
- finetuning 접근으로 전이학습에서 GPT 모델을 기반으로 전체 파라미터를 fine-tuning한다.
- 사전학습된 모델 위에서 학습하기 때문에 scratch부터 학습해야하는 파라미터가 적다.
- BERT
- Masked LM으로 진정으로 양방향의 문맥을 고려한다.
- finetuning 접근이다.
Introduction
언어 모델 사전학습은 많은 NLP task에서 효과적으로 알려져 있다.
- sentence level
- Natural Language Inference
- 한문장이 다른 문장을 support/contradict/neutral 한지 분류
- parapharasing
- 두 문장이 동일한 의미를 가지는지 판단
- Natural Language Inference
- token level
- Named Entity Recognition
- 특정 단어가 인물, 장소, 기관 등 개체인지 판별
- Question Answering
- 질문을 보고 지문에서 정확한 답 구절을 추출
- Named Entity Recognition
기존 방식
사전학습된 언어 표현을 down stream task로 사용하는 접근법은 두가지로 feature-based(ELMo), fine-tuning(GPT)가 존재한다. 하지만 두 접근법 모두 사전학습 시 단방향 언어 모델을 사용하여 언어 표현을 학습한다.
이러한 기존 언어 모델들은 단방향이여서 표현력을 제한하게 된다!
- (e.g.) GPT는 left-to-right 구조인데 self-attention에서 이전 토큰에만 attend 할 수 있다
특히, Question Answering 같은 세밀한 토큰 단위 작업에서는 양방향의 맥락을 활용하지 않으면 최적의 성능을 내기 어렵다.
우리의 방식
Masked Language Model(MLM)로 사전학습하여 양방향으로 문맥을 학습하게 하였다.
- 입력에서 랜덤하게 masking
- masked 단어를 좌우 맥락을 살펴 예측
이외에도 두 문장이 이어지는 문장인지 확인하는 next sentence prediction을 수행한다.
기여
- 양방향성이 언어 표현에 중요하다는걸 입증
- GPT와 달리 양방향의 토큰들을 보고 예측을 수행
- ELMo 또한 단순히 각각 학습한 left-to-right, right-to-left 언어 모델을 concat한 것
- 잘 학습된 언어 표현으로 인해 복잡한 task-specific architecture이 불필요
- 앞서 말했듯이 BERT는 11개의 task에서 SOTA 달성함
BERT
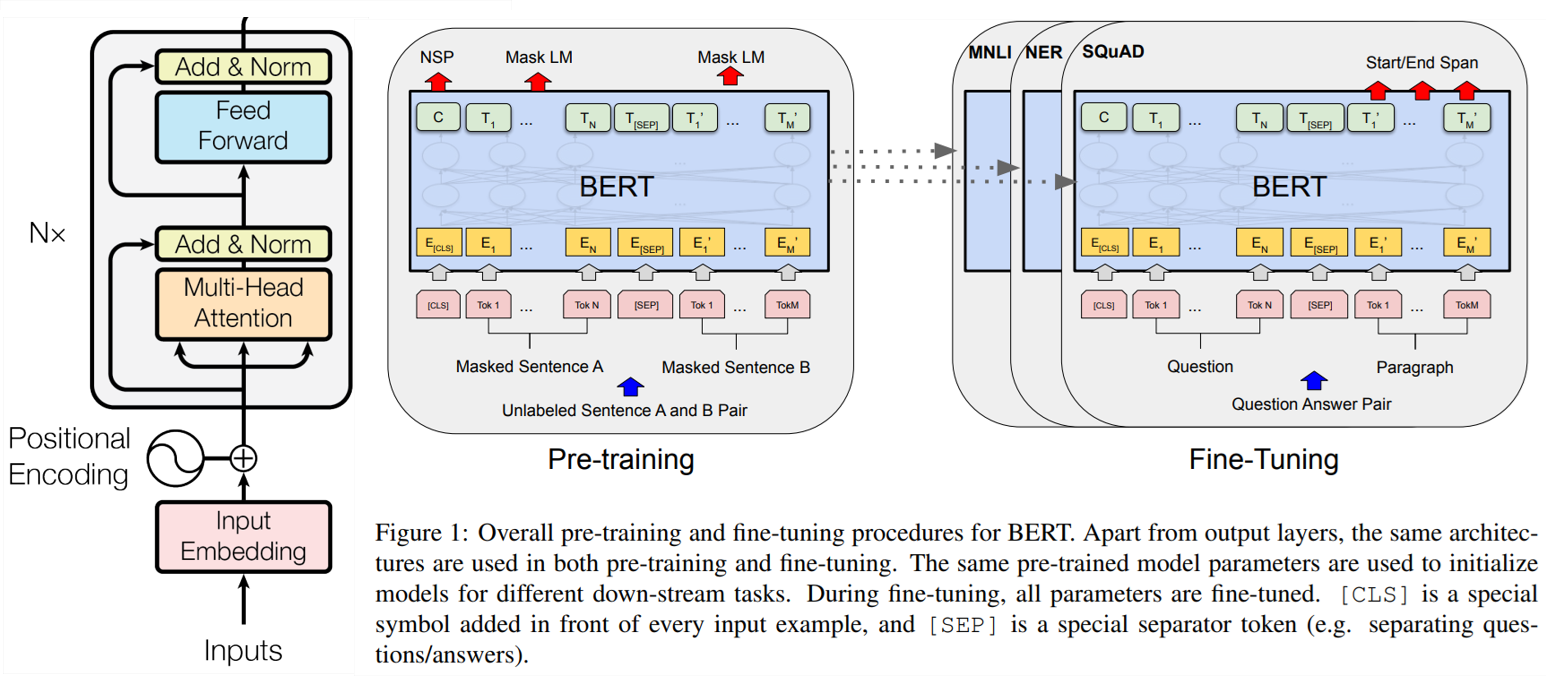
기본적으로 Transformer의 Encoder 구조를 동일하게 사용하는 모델이다.
- BERT_base
- L=12, H=768, Attention_head=12, Total Parameters=110M
- GPT와 비교 목적을 위해 같은 모델 크기로 선정
- BERT_large
- L=24, H=1024, A=16, Total Parameters=340M
- 30,000 vocab의 WordPiece를 사용함
[CLS]토큰으로 전체 시퀀스에 대한 표현
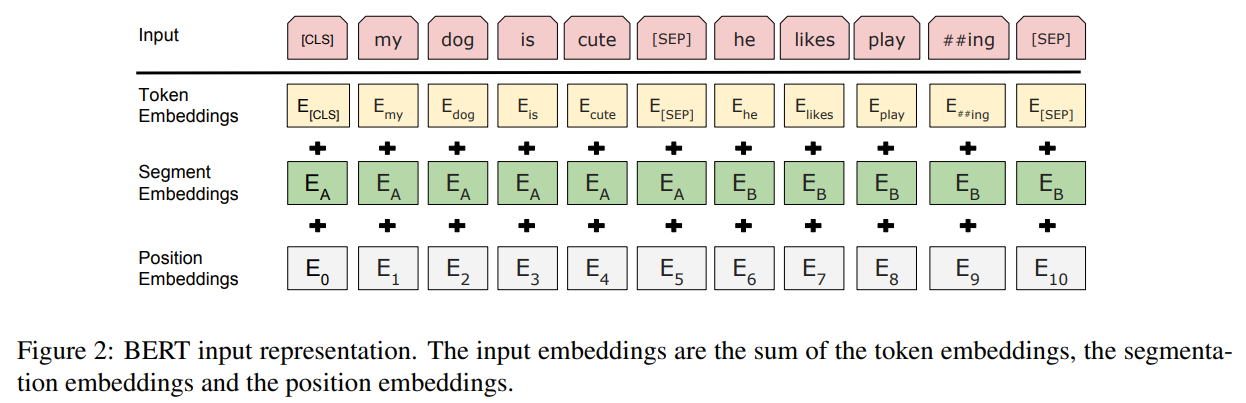
[SEP]토큰 + 세그먼트 임베딩으로 두 문장을 구별
Pre Training
사전학습은 BooksCorpus (800M words), English Wikipedia (2,500M words) 를 사용하여 이루어졌다. 여기서 list, tables, headers 는 제외하였으며, 긴 연속 문장을 위해 문서 수준의 corpus를 선택하였다. 학습방법은 아래와 같다:
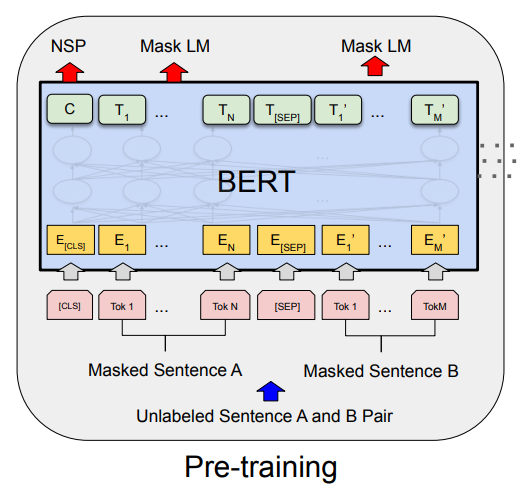
- Masked LM
- 15%만 mask 처리
- masked token들의 원본 token을 해당하는 final hidden vector를 사용하여 예측
- 실제 task에는 [Mask]가 없기 때문에 마스킹에 대한 처리를 아래와 같이 진행:
- 15% 를 무작위로 선택
- 선택된 것들 중 80%는 [Mask]로 변환
- 10%는 랜덤 토큰으로 변환
- 10% 그대로 둠
- Next Sentence Prediction
- QA, NLI 등 두 문장의 관계 이해가 중요한 task들이 존재
- 데이터의 50%는 A 문장과 B 문장이 연속되게 설정
- [CLS] 토큰의 최종 vector를 사용해 예측
Fine Tuning
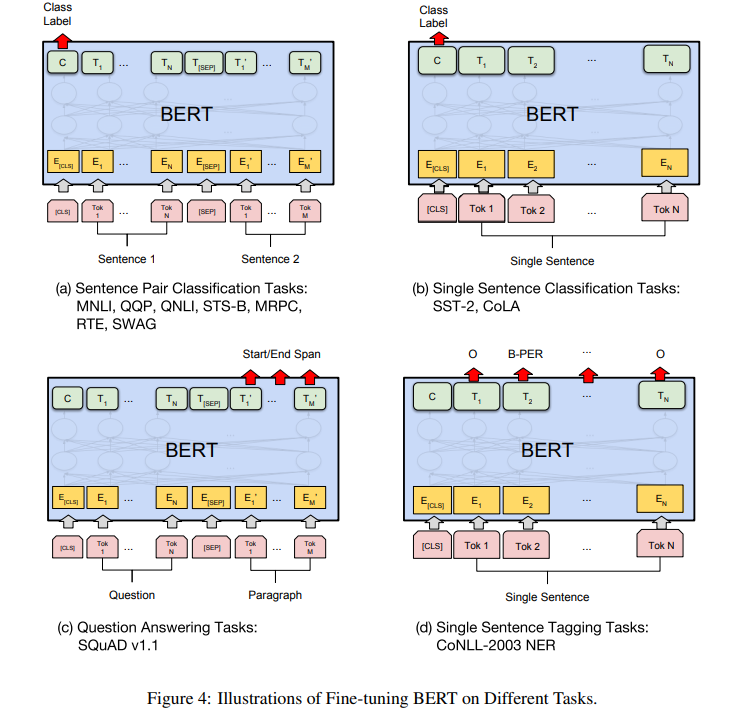
여러 down stream task는 각 task 별 입력과 출력을 BERT에 연결하고 모든 parameter를 finetuning 하기만 하면 된다.
- Token level tasks는 각 token 표현들을 출력 layer로 전달한다.
- sequence tagging, question answering
- 문장 단위의 분류 문제에 대해서는 [CLS] 표현을 출력 layer로 전달한다.
- NLI, parapharasing, sentiment analysis
Experiments 결과
General Language Understanding Evaluation(GLUE)
[CLS] 토큰의 출력만을 사용한다. label 개수 x hidden size의 weight을 가지는 분류 layer만이 새롭게 추가되고 이 값을 softmax하여 계산한다.
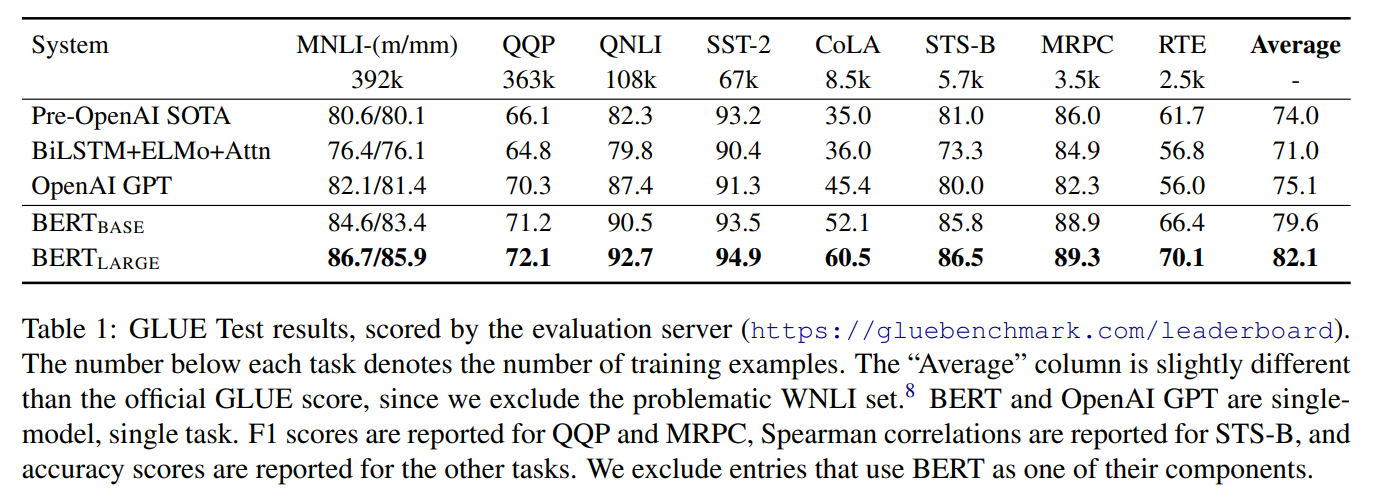
BERT-base는 GPT와 attention mask외에 사실상 동일한 모델이지만 성능이 훨씬 뛰어나다.

gluebenchmark 현재는 49위
SQuAD
Question Answering을 위해 정답 span의 start, end 위치를 예측한다.
각 토큰이 start/end token인지 판단할 수 있는 학습가능한 벡터 start vector S, end vector E를 추가한다.
\[P_i=\frac{e^{S \cdot T_i}}{\sum_j e^{S \cdot T_j}}\]모든 토큰들에 대해 start vector S를 dot product하고, softmax를 통해 각 토큰이 start token일 확률을 계산할 수 있다. 마찬가지로 end vector E를 사용해서 end 위치를 찾아낼 수 있다.
학습 과정에서는 실제 정답 위치인 (i, j)에 대해 $S \cdot T_i+E \cdot T_j$ 의 값을 최대화 하도록 S와 E 벡터를 학습한다.
답변이 없는 질문은 정답으로 [CLS] token을 가르키도록 처리한다. non-null에 대한 값이 null에 대한 값보다 $\tau$ 이상으로 클 때만 정답이 존재한다고 판단한다.
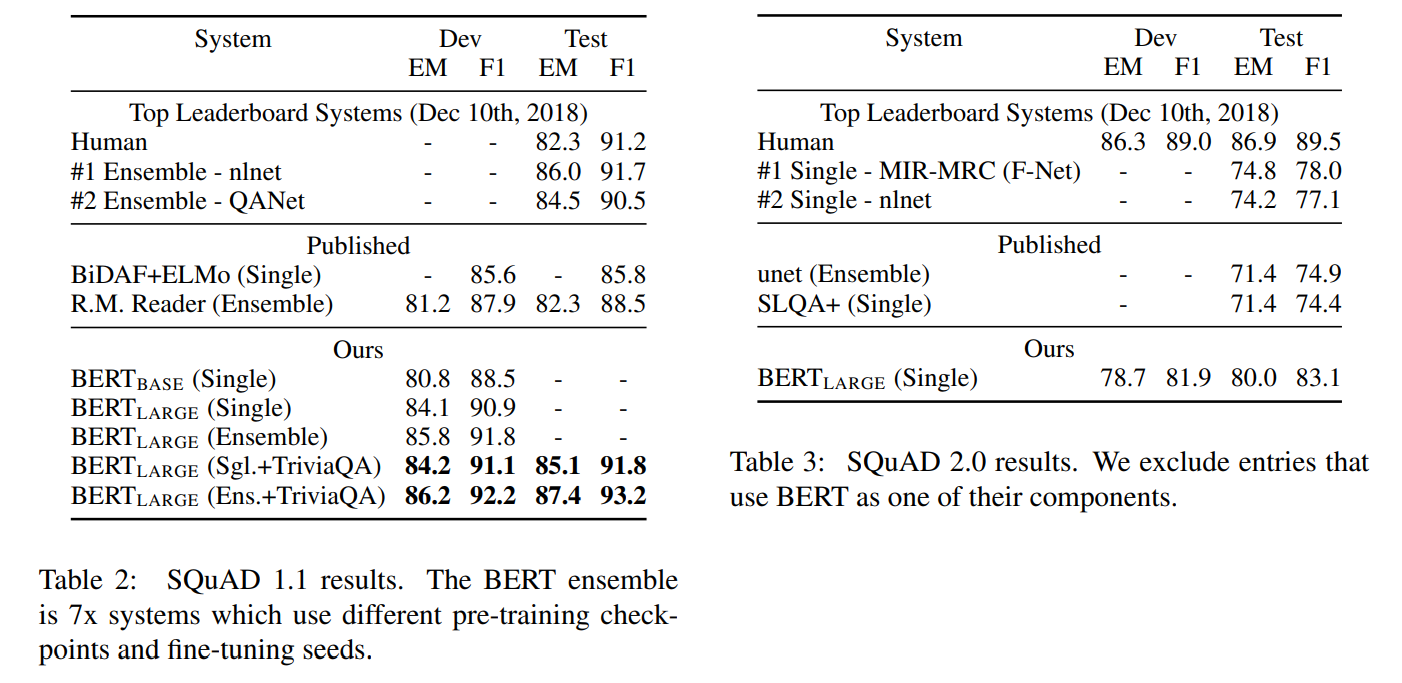
- SQuAD v1.1
- TriviaQA 데이터로 파인튜닝 한 뒤 SQuAD를 파인튜닝함으로 데이터 증강을 꾀함
- 이를 통해 0.1 ~ 0.4 F1 추가 상승
- 최종적으로 기존보다 1.5점 상승
- TriviaQA 데이터로 파인튜닝 한 뒤 SQuAD를 파인튜닝함으로 데이터 증강을 꾀함
- SQuAD 2.0
- TriviaQA 데이터 사용 X, 기존보다 5.1점 상승
Situations With Adversarial Generations(SWAG)
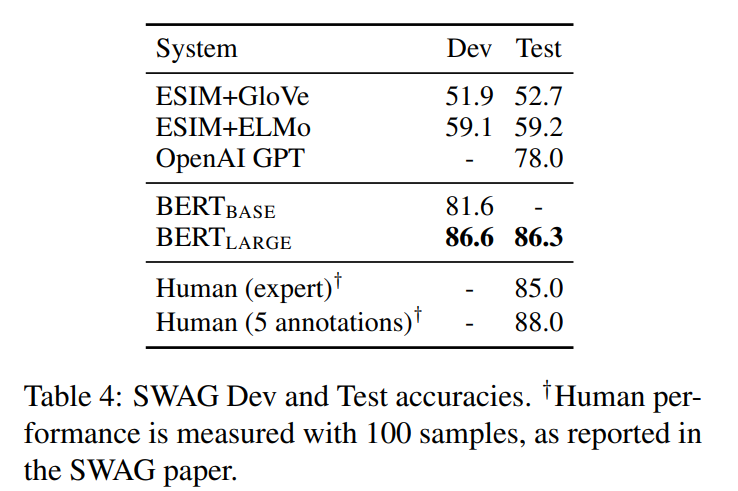
4개의 문장 중 주어진 문장 다음에 오는 게 가장 자연스러운 문장을 고르는 task
주어진 문장과 4개의 문장을 각각 연결하여 병렬적으로 4번 처리한다. 그 후 새롭게 추가된 학습가능한 벡터와 [CLS] 토큰의 출력을 내적하고 정답 문장의 값을 최대화하는 방향으로 학습한다.
결과: GPT보다 8.3% 증가하였다.
Ablation Studies
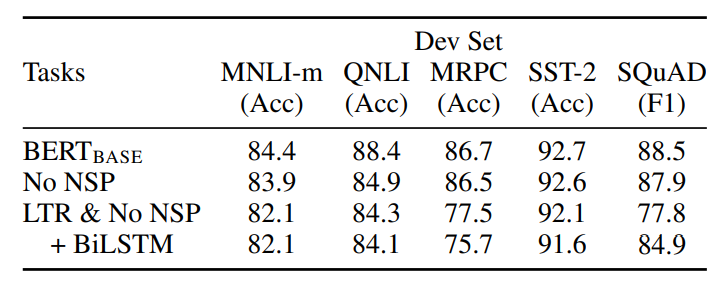
- QNLI, MNLI, SQuAD 등 두 문장의 관계가 필요 task에서 NSP가 중요하다.
- MRPC와 SQuAD에서 큰 하락
- SQuAD는 정확한 토큰 위치를 찾아야하니까 양방향 문맥이 중요
- BiLSTM 추가시 어느 정도 회복
- MRPC는 두 문장을 양방향으로 섬세하게 봐야하기 때문에 bert의 양방향성이 성능에 큰 영향
- SQuAD는 정확한 토큰 위치를 찾아야하니까 양방향 문맥이 중요
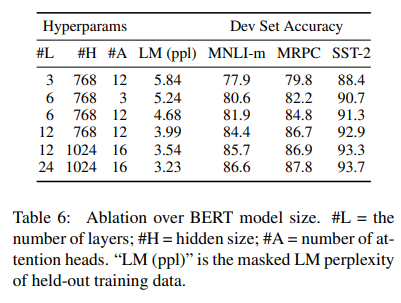
모델이 클수록 성능이 계속 올라간다.
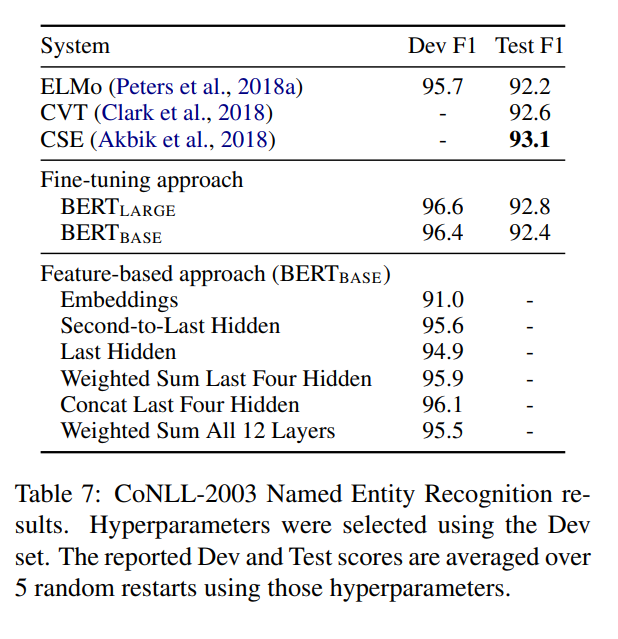
파인튜닝을 하지않고 feature based로 하더라도 어느정 높은 성능을 보인다.
결론
기존의 전이 학습은 단방향 언어 모델에 의존했지만, BERT는 양방향 사전 학습(bidirectional pre-training)을 통해 더 풍부한 문맥 표현을 학습하였다.
이를 통해 다양한 NLP 작업에서 사전 훈련된 모델로 우수한 성능을 얻을 수 있다!
후기
이번 스터디의 발표를 맡아 최대한 자세하게 조사하여 깔끔하게 정리하려고 노력하였다. 발표 시간을 축약하려고 했지만 결국 1시간 가까이 발표하였고 질문시간 30분을 가져 1시간 반 동안 발표 및 질의응답을 가졌다. 단순 스터디이지만 이렇게 논문에 대해 발표를 해보니 본격적으로 학계를 따라가는 느낌이 들어 즐거웠다.
BERT는 네부캠에서의 STS 프로젝트와 ODQA 프로젝트로 나에게 매우 친숙한 모델이였다. 이번에 꼼꼼히 논문을 읽다보니 왜 이제서야 읽었을까 생각이 들었다.
STS 프로젝트 당시(24년 9월)만 해도 잘 아는 게 없이 여기저기서 주워들은 지식만 가득 있었다. 이때 어디서 주워들은 지식으로 전반부 파라미터를 freezing한뒤 위쪽 layer만 집중해서 파인튜닝보았고, 성능이 내려가 결과에 대한 의문에 휩싸여있었다. 하지만, BERT 논문에서 BERT에 대한 사용법으로 전체 파라미터를 전부 fine tuning 진행하라고 나와있었다. 책 한권만 읽은 사람이 무섭다고 어디서 주워들은 걸로 적용하니 제대로된 결과가 나올리가 없었던 것이다.
앞으로도 최대한 많고 다양한 논문을 요약이 아닌 원문으로 읽어야겠다고 느꼈다. 생각보다 꼼꼼히 정리하는 데 시간이 많이 걸려 이후 읽는 논문들은 리뷰 발표가 아닌 이상 좀 더 힘을 빼고 정리할 것 같다.(혹은 정리를 안할 수도 있다!) 대신 최대한 다양한 논문을 읽을 것이고, 꼭 소개하고 싶은 논문들은 계속해서 포스팅해 나갈 예정이다!
댓글남기기