
[카테캠 BE] week9 - SNS 서버 만들기(MySQL)(2)
이제 sns-server를 완성했어요! Spring에서 JDBCTemplate을 사용해 layered Architecture로 만들었는데 구조도 깔끔하고 객체지향으로 기능 분리가 되어 있어 코드 짜는 내내 재밌었어요.
완성한 프로그램 github link
이번주도 이론 내용을 적어볼게요.
페이지네이션
- 페이지 넘버(e.g. 쇼핑몰)
- 오프셋 기반 페이징 (페이지 + 사이즈)
- 무한 스크롤
- 커서 기반 페이징(커서 + 사이즈)
오프셋 기반 페이지네이션의 문제
- 마지막 페이지를 구하기 위해 전체 갯수를 알아야 한다.
- 성능에 문제가 생긴다.
- 불필요한 데이터 조회가 발생한다.
- Offset부터 시작하기 위해 Offset 이전 데이터도 읽고 버린다.
커서 기반 페이징
- 페이지 대신 key를 준다.
- 마지막으로 읽었던 키 + 사이즈
- 전체 데이터를 조회하지 않아서 마지막 페이지를 얻을 수 없다.
오프셋 기반은 페이지 이동 시 이전 페이지 내용을 볼 수도 있다.(새로운 데이터 추가로 인해)
커서는 key(id) 기준으로 반환하기 때문에 다음 내용을 봤을 때 겹치는 일이 거의 없다.
커버링 인덱스
원본 테이블에 접근하지 않고 인덱스로만 데이터 응답을 내려줄 수 있다면 인덱스로만 응답을 주자!
SELECT 나이, id
FROM 회원
WHERE 나이 < 30
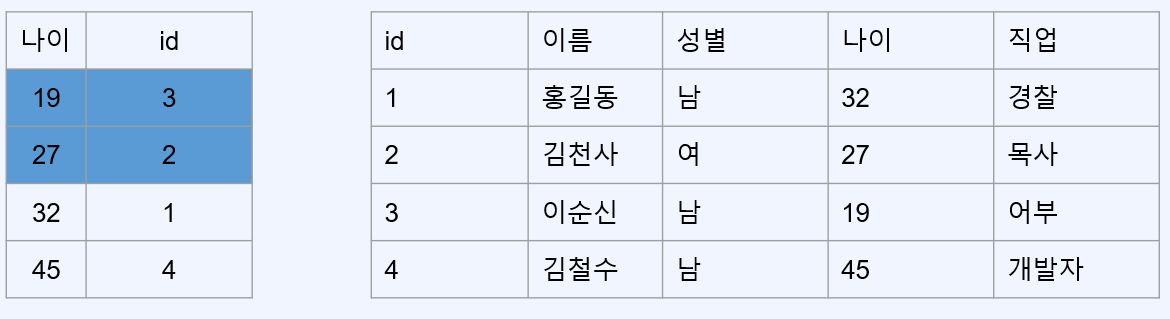
- 이처럼 인덱스만 보고 응답을 충분히 줄 수 있어 원본 테이블에 접근하지 않는다.
커버링 인덱스로 페이지네이션 최적화
order by, offset, limit, group by 절 등으로 인한 불필요한 데이터블록 접근을 커버링 인덱스를 통해 최소화 가능
- 먼저 id만 찾아 커버링 인덱스로 인덱스 조건에 맞는 데이터 블록을 찾는다.
- 그 후, 조건에 맞는 데이터만 테이블에 접근함으로써 성능을 올릴 수 있다.
with 커버링 as (
SELECT id
FROM 회원
WHERE 나이 < 30
LIMIT 2
)
MySQL의 with 문으로 임시 테이블 생성
SELECT 이름
FROM 회원 INNER JOIN 커버링 on 회원.id = 커버링.id
타임라인(게시물 피드)
SNS에서 팔로우 된 회원들의 게시물을 보여주는 피드
Fan Out On Read (Pull Model)
회원의 팔로우 목록 조회 → 1번의 팔로우 회원 id로 게시물 조회
- 팔로우 목록을 바탕으로 or 연산을 하기 때문에 시간복잡도가 높다.
- log(Follow 전체 레코드) + 해당회원의 Following * log(Post 전체 레코드)
- 팔로우를 많이 할수록 점점 느려진다!
Fan Out On Write (Push Model)
게시물을 작성할 때 Timeline 테이블에 팔로워들과 게시물 번호를 연결하여 데이터를 추가한다.
- Pull 모델에서의 조회시점의 부하를 쓰기 시점의 부하로 치환
- 피드를 확인할 때, Timeline 테이블에서 본인의 인덱스만으로 바로 찾을 수 있다.
- 따라서 빨라진다.
- 하지만 쓰는 시점에서 부하가 발생하는 트레이드오프가 발생한다.
페이스북과 트위터의 모델
- 페이스북의 경우 Pull model
- 친구를 최대 5000명까지만 가능하게 제한
- 시간 복잡도를 희생
- 원본 데이터를 직접 참조하므로, 정합성 보장에 유리
- 트위터의 경우 Push Model
- 팔로우를 최대 5000명까지 가능하지만 팔로워가 증가하면 팔로우를 더 할 수 있게 허용해 줌
- 공간복잡도를 희생
- Pull Model에 비해 시스템 복잡도가 높다.
- 하지만 그만큼 비즈니스, 기술 측면에서 유연성을 확보 가능하다.
- 정합성 보장에 대한 고민이 필요하다
트랜잭션
여러 SQL 문을 하나의 오퍼레이션으로 묶는 것
ACID
데이터 베이스 트랜젝션이 안전하게 수행되는 것을 보장하기 위한 성질 4가지
- Atomicity(원자성)
- 한 트랜잭션이 전체 성공하거나 전체 실패해야 한다.
ALL or Nothing - MySQL에서 MVCC를 통해 지원된다.
- Undo Log에 보관 → 트랜잭션 실패 시 Undo Log로 복
- 한 트랜잭션이 전체 성공하거나 전체 실패해야 한다.
- Consistency(정합성)
- 트랜잭션이 종료되었을 때, 데이터의 무결성이 보장되어야 한다.
- 제약조건을 통해(unique 제약, foreign key 제약)
- Isolation(독립성)
- 트랜잭션 수행 시, 다른 트랜잭션 연산에 끼어들지 못하도록 보장해야 한다.
- 성능에 악영향이 오기 때문에 개발자가 제어가 가능하다.
- 트랜잭션 격리레벨 사용(undo log, mvcc로 지원)
- Durability(지속성)
- 성공적으로 수행된 트랜잭션은 영원히 반영되어야 한다.
- WAL(Write-ahead logging)을 사용
- db의 성능은 random disk-IO가 적을 수록 빨라진다.
- 따라서 디스크가 아닌 메모리에 적어 속도를 향상 시키는데,
- 서버가 죽어버리면 데이터가 유실될 가능성이 있다.
- WAL은 순차적으로 로그를 쌓기만 한다. 이를 통해 랜덤 io를 줄인다.
@Transactional
transaction으로 동작했으면 하는 메서드에 붙인다.
@Transactional
public Member register(RegisterMemberCommand command) {
var member = Member.builder()
.nickname(command.nickname())
.email(command.email())
.birthday(command.birthday())
.build();
var savedMember = memberRepository.save(member);
saveMemberNicknameHistory(savedMember);
return savedMember;
}
-
주의할 점 - 같은 클래스 내의 transaction 메서드를 호출하면 그 메서드는 transaction으로 동작하지 않는다.
public Member register(RegisterMemberCommand command) { return getMember(command); } @Transactional private Member getMember(RegisterMemberCommand command) { var member = Member.builder() .nickname(command.nickname()) .email(command.email()) .birthday(command.birthday()) .build(); var savedMember = memberRepository.save(member); saveMemberNicknameHistory(savedMember); return savedMember; }@transactional은 프록시 방식으로 동작- service 클래스를 상속받는 어떤 특정 객체를 만들어준다.
- transactional을 보고 메서드를 시작과 끝에 begin과 commit를 만든다.
- 하지만 클래스의 내부 메서드를 사용하면 새로 만든 proxy 객체가 아닌 원래 클래스의 메서드를 호출해버리게 된다.
- 따라서
@Transactional을 붙였음에도 불구하고 Transaction이 수행되지 않는다.
트랜잭션 격리레벨(MySQL InnoDB)
- 격리 레벨로 방지하는 이상현상들
- Dirty Read
- commit 되지 않은 데이터를 읽음
- Non Repeatable Read
- 같은 데이터를 조회했는데 결과가 달라지는 것
- 다른 트랜잭션이 값을 바꿔버려 다시 읽었을 때, 처음에 읽은 값과 달라져 있음
- Dirty Read가 없어도 다른 트랜잭션이 커밋되며 읽은 값이 바뀔 수 있다.
- Phantom Read
- 같은 조건으로 데이터를 조회했을 때, 없던 데이터가 생겨버리는 것
- Non Repeatable Read와 유사
- WHERE문으로 조회 시 없었던 데이터가 다른 트랜잭션의 영향으로 새롭게 생겼다.
- Dirty Read
- 격리 레벨 4가지
- READ UNCOMMITTED
- Dirty Read, Non Repeatable Read, Pantom Read 발생 가능
- 커밋 안된 정보도 읽음
- READ COMMITED
- Non Repeatable Read, Pantom Read 발생 가능
- 커밋된 정보만 읽음
- REPEATABLE READ
- Pantom Read 발생 가능
- 트랜잭션마다 id 부여, id 보다 나중에 들어온 transaction은 보지 않음
- 항상 동일한 읽기를 보장
- SERIALIZABLE READ
- 아무것도 발생 안함
- READ UNCOMMITTED
아래로 갈수록 동시 처리량이 낮다. 그렇기 때문에 SERILIZABLE READ는 거의 쓰이지 않는다. 또한, READ UNCOMMITTED도 안전하지 않아 잘 안 쓰인다.
MySQL의 기본 격리 레벨은 REPEATABLE READ이다.
동시성 제어
동시성 이슈의 가장 일반적인 패턴
-
공유자원 조회
→ 다른 오퍼레이션이 수행(동시성 문제)
-
공유자원 갱신
락(공유 자원에 대한 잠금)
MySQL에서는 트랜잭션의 커밋/롤백 시점에 잠금이 풀린다.(트랜잭션이 곧 락의 범위)
- 읽기 락(Shared Lock)
- Shared Lock 끼리는 Lock을 공유하여 같이 데이터를 읽을 수 있다.
SELECT... FOR SHARE;
- Shared Lock 끼리는 Lock을 공유하여 같이 데이터를 읽을 수 있다.
- 쓰기 락(Exclusive Lock)
- 오직 Exclusive Lock 혼자서 데이터에 접근 가능하도록 한다.
SELECT ... FOR UPDATE; # 또는 UPDATE, DELETE 쿼리
- 오직 Exclusive Lock 혼자서 데이터에 접근 가능하도록 한다.
MySQL에서 잠금은 row가 아니라 인덱스를 잠근다.
- 인덱스가 없는 조건으로 Locking Read 시 불필요한 데이터들이 잠길 수 있다.
-
항상 lock을 걸 때, where 절의 attribute가 인덱스로 만들어져 있는지 확인해야한다.
- 인덱스가 없다면 전체 테이블이 lock 될 수 있다.
START TRANSACTION ; SELECT * FROM post WHERE memberId = 1 and contents = 'string' FOR UPDATE; COMMIT;- memberId는 인덱스가 있지만 contents는 인덱스가 없어서 memberId=1인 모든 row가 락이 된다.
start transaction ; select * from post where memberId= 1 and contents = 'timeline' for update; commit;- 따라서 관련이 없는 데이터를 접근하는데도 락이 발생하게 된다.
- 만약 인덱스가 없는 attribute를 조건으로 하여 락을 건다면 테이블의 모든 데이터가 lock되므로 주의해야한다.
-
transaction 및 lock 확인법
## Transaction 확인 SELECT * FROM information_schema.INNODB_TRX; ## Lock 확인 SELECT * FROM performance_schema.data_locks WHERE LOCK_TYPE = 'RECORD';
비관적 락(Pessimistic Lock)
위에서 한 것들을 동시성 문제가 발생할 거라 가정하고 락을 건다.
즉, 락을 통한 줄세우기이고 비관적 락(Pessimistic Lock)이라고 부른다.
- 락을 통한 동시성 제어는 불필요한 대기 상태를 만든다.
- MySQL에서는 인덱스를 기반으로 불필요한 row까지 잠구게 될 수 있음.
- 동시성이 빈번하지 않은 쿼리로 인해 다른 쿼리가 대기하게 되고 시스템이 느려진다.
낙관적 락(Optimistic lock)
- 동시성 이슈가 빈번하지 않길 기대하고, 어플리케이션에서 제어
- CAS(Compare And Set)을 통해 제어
- 비교(compare)를 하고 맞지 않으면 업데이트(set)을 하지 않는다.
- 버전을 기록할 attribute를 생성
-
read(select)하여 값과 함께 버전을 기록하고 where 문으로 해당 버전에 update
UPDATE POST set memberId = :memberId, contents = :contents, createdDate = :createdDate, likeCount = :likeCount, createdAt = :createdAt, version = :version + 1 WHERE id = :id and version = :version; - 성공 시 버전이 올라가기 때문에 다른 곳에서는 업데이트 전에 읽은 값은 버전이 맞지 않아 update를 실패하게 된다.
- 실패에 대한 처리를 직접 구현해야 함
- 재시도(try-catch문? 다시 시도해도 또 실패할 수 있음 / 비동기 처리를 할 수도 있다.)
- 혹은, 실패에 대한 알림
- 혹은, 그냥 버리기
- JPA를 사용하면
@version사용해서 가능하다.
💡 정합성이 중요한 데이터들은 낙관적 락과 비관적 락을 섞어서 쓰기도 한다.
또한, 여러 데이터베이스를 쓰는 분산 환경에서는 비관적 락을 쉽게 사용할 수 없다는 걸 주의하자.
좋아요 테이블을 개선하기
조회 시점의 병목이 존재(조회 시 마다 count query가 필요하다)
- 좋아요 수는 높은 정합성을 요구하는 데이터인가?
- 100% 정확해야 할 필요가 없는 데이터
- 몇 초의 delay로 늦게 반영되어도 상관이 없다.
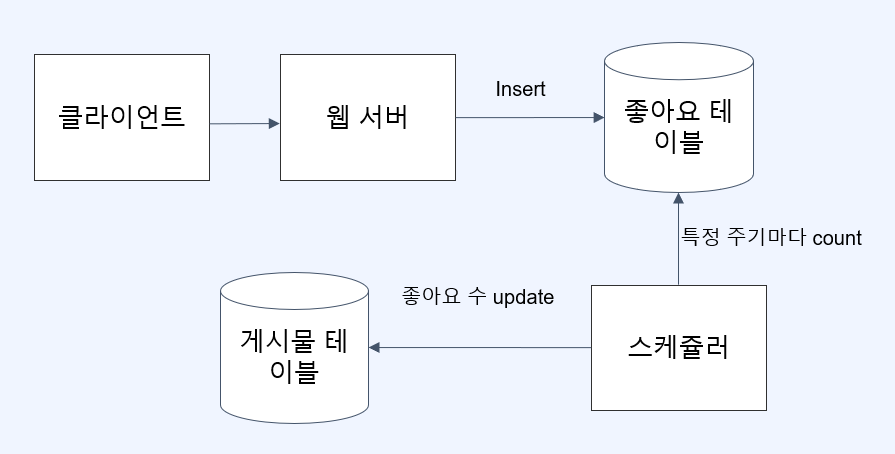
- 스케쥴러를 사용해 일정 주기마다 좋아요 수를 게시물 테이블에 갱신해 주자.
- Reddis???
- 기본적으로 싱글 쓰레드로 동작 하기 때문에 별도의 락 작업이 필요없다.
- 그리고 메모리에 데이터를 올리고 있기 때문에 RDBMS보다 훨씬 빠른 작업이 가능하다.
- 이걸로 count를 관리하면 장점을 활용할 수 있다?
- 하지만, 내가 누른 좋아요가 바로 반영이 안된다…
- 이는 프론트의 클라이언트 캐싱을 통해 처리를 하면 된다.
데이터의 성질, 병목지점등을 파악하고, 적당한 기술들을 도입해 해소하자!
더 나아가기…
- Repository Layer를 JPA로 리팩토링
- 팔로워가 100만명인 유저의 게시물 작성 성능 테스트
- 현재 게시물 쓸 때, 100만 개 timeline 만들어줘야함
- 비동기 큐를 통해 개선
- Mixed Push / Pull Model
- 팔로워 많은 사람의 게시물은 뉴스피드 읽기 시점에 들고오기?
- nGrinder 부하 테스트 자동화 도구 사용해보기
- 로그인 / 팔로우 승인, 취소 / 댓글 구현
- MySQL Master / Slave
- read에 대한 부하를 해소하는 방법
- 어떻게 동작하는 지 세부 학습하기
- 파티셔닝
- 데이터 많아졌을 때 어떻게 관리해야 하는 지에 대한 방법
의존성 주입
- Autowired
- RequiredArgsConstructor
나중에 공부할 거
- 테스트 코드?
- TDD
- propagation level:
@Transactional에서 transaction 어떻게 동작하는지 설정 가능 - 자바/스프링(Java/Spring)과 Node.js의 비교
✏️여담
JPA를 몰라서 JPA 이야기가 이해가 안됐어요. 따로 JPA를 공부해야겠어요. 구글링하면서 공부하고 있는데 생각보다 잘 정리된 블로그를 못 찾겠어요😭 일단 써보면서 시행착오를 거치며 해야겠어요.
댓글남기기