
[프로젝트 회고] UnDoc - RAFT와 RAG 기반 의료상담 챗봇 연구
지난 구글 ML 부트캠프 수료 후기에 이어, 우수 프로젝트로 선정되었던 UnDoc 챗봇에 대해 회고를 남겨본다.
프로젝트 시작 배경
2024년 구글 ML 부트캠프의 최종 단계인 Gemma Sprint에서, 의료 상담 챗봇을 개발하게 되었다. 당시 의사 파업이 사회적 이슈가 되고 있었는데, 이러한 상황에 AI를 활용해 사회적 기여를 목표로 삼았다. 팀원은 게더타운 스터디에서 인연을 맺은 영윤님과 함께였다. 영윤님은 연구 경험이 풍부했고, 나는 개발 경험을 살릴 수 있어 서로 강점을 잘 보완할 수 있었다.
서비스 기획
Gemma 모델은 의료 지식이 부족했기 때문에 RAG(Retrieval-Augmented Generation)를 통해 신뢰할 수 있는 의료 데이터를 검색하여 답변을 생성하는 구조를 설계했다. 사용자에게 친숙한 경험을 제공하기 위해 ChatGPT와 유사한 UI로 서비스 방향을 잡았다.
최초 계획은 단순한 RAG 시스템이었으나, 후반에 발생한 문제로 RAFT(Retrieval Augmented Fine-Tuning)를 추가로 도입하였다.
기술 스택과 구현 과정
데이터셋과 임베딩
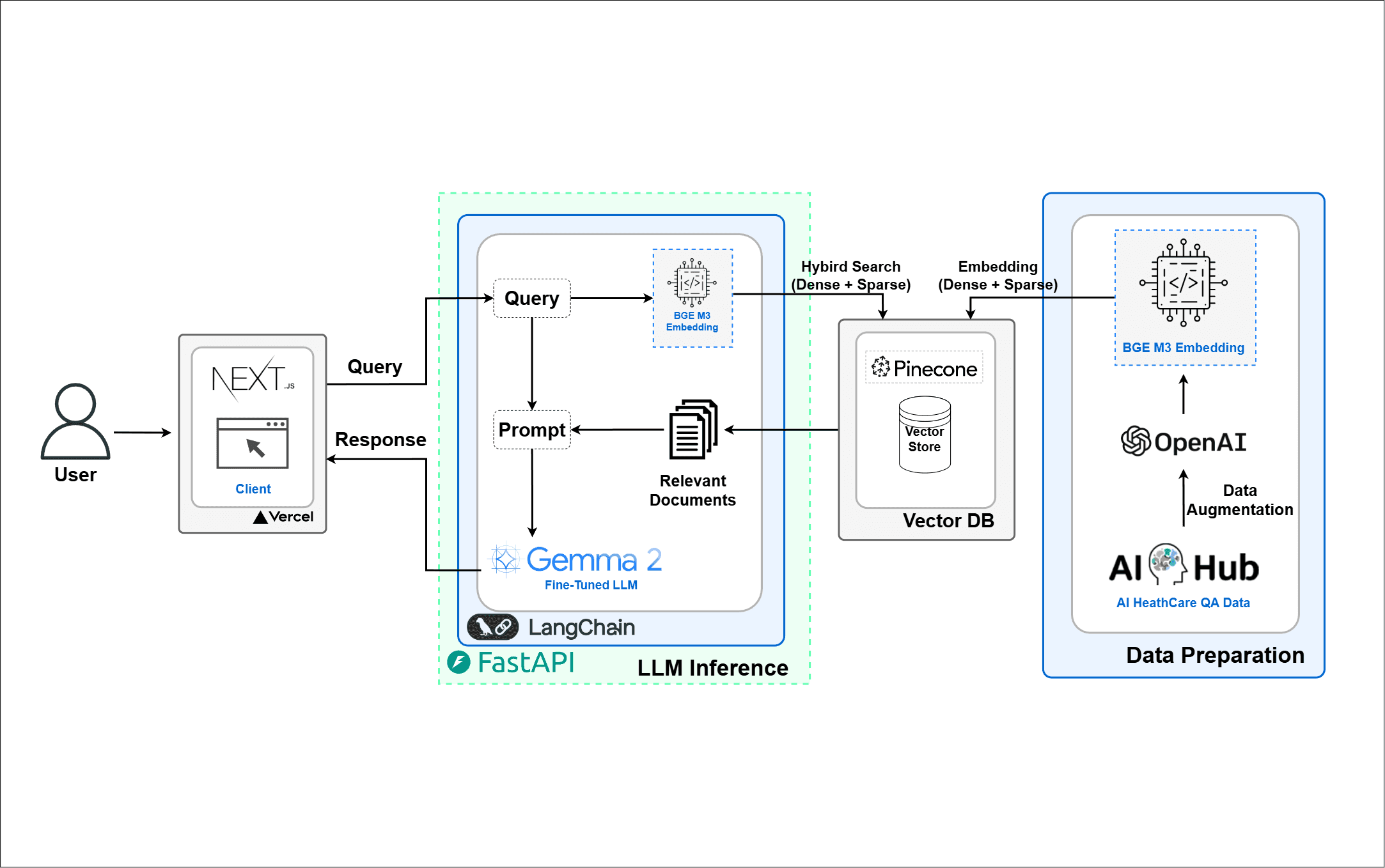
데이터는 AI Hub의 초거대 AI 헬스케어 질의응답 데이터를 활용했고, 임베딩은 한국어에서 성능이 우수한 다국어 모델 BGE-M3를 사용했다. 벡터 DB는 편의성을 위해 PineCone을 선택하였다.
LangChain과의 만남
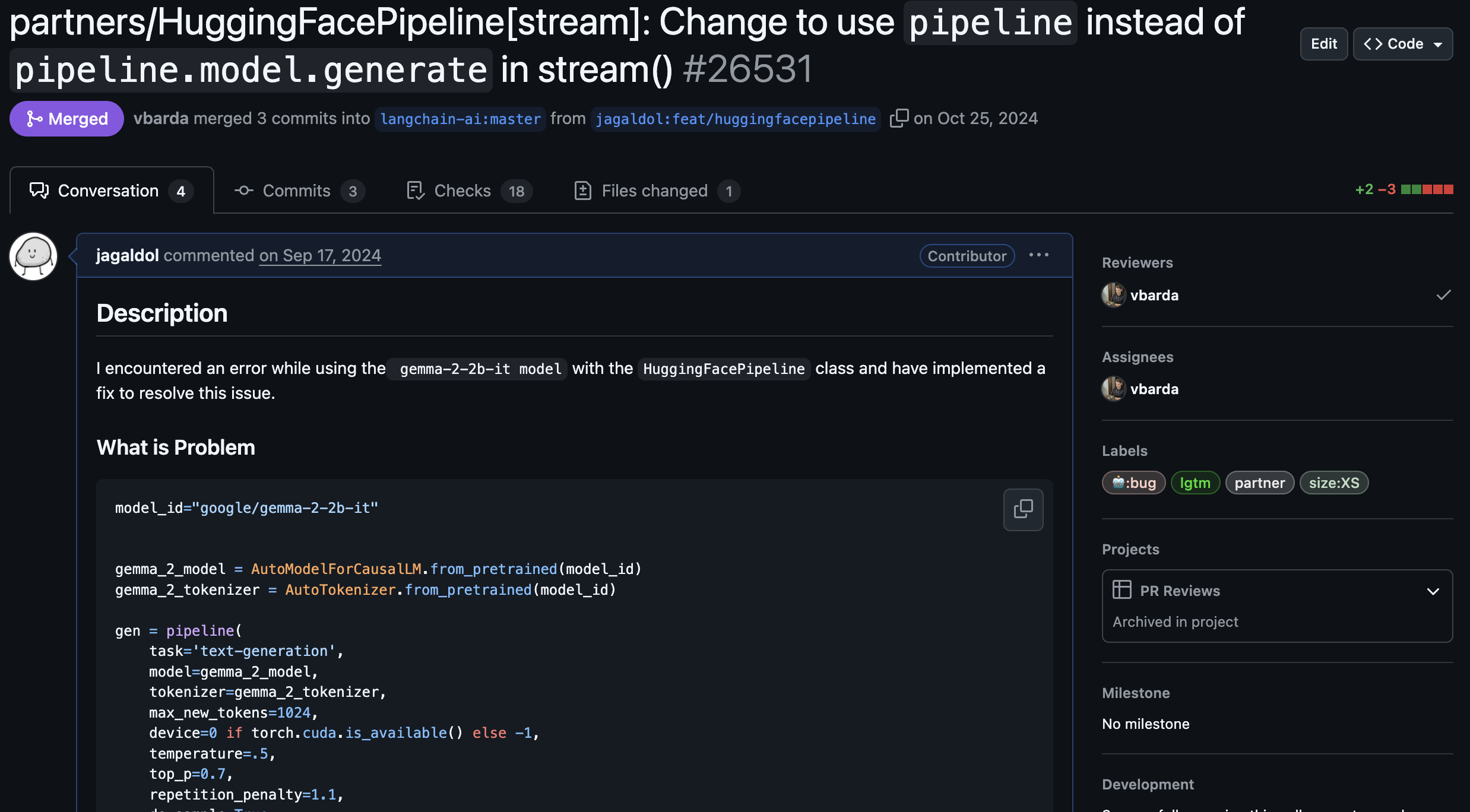
이번 프로젝트를 계기로 LangChain을 처음 사용했다. 하지만 HuggingFacePipeline 클래스의 stream() 메서드가 제대로 작동하지 않는 버그를 맞닥뜨렸다. 문제 해결을 위해 라이브러리 내부 구현을 분석했고, 결국 직접 패치를 제작하여 PR을 보내 LangChain의 공식 contributor가 되는 의미 있는 경험을 했다.
RAFT의 도입
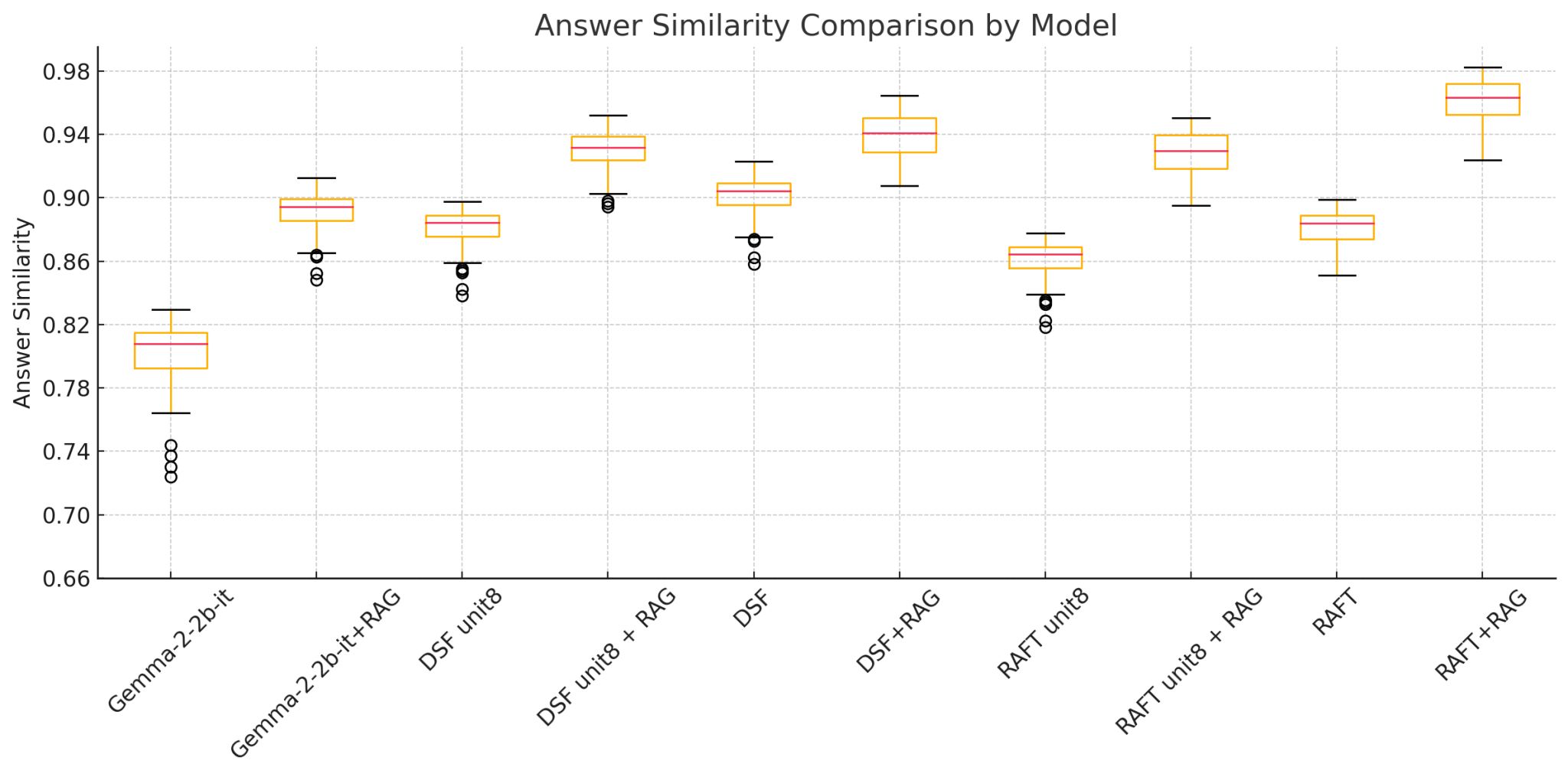
초기에는 단순한 RAG 시스템으로 구현했으나, 모델이 부정확한 문서를 참조하여 잘못된 답변을 하는 문제가 있었다. 해결책으로 Retrieval-Augmented Fine-Tuning(RAFT)을 도입했다. RAFT는 RAG 상황을 학습 단계에서 모사하여 잘못된 참조를 방지하는데 효과적이었다. 결과적으로 답변 정확도를 96.02%까지 끌어올렸다.
서버 및 프론트엔드 구축
서비스 출시까지 목표로 삼았기 때문에 웹 서비스도 제작하였다. 서버는 Python의 FastAPI로 구현했고, 프론트엔드는 Next.js를 활용했다. 이전 프로젝트 ChatFoodie의 경험을 살려 디자인과 반응형까지 신경을 썼다.
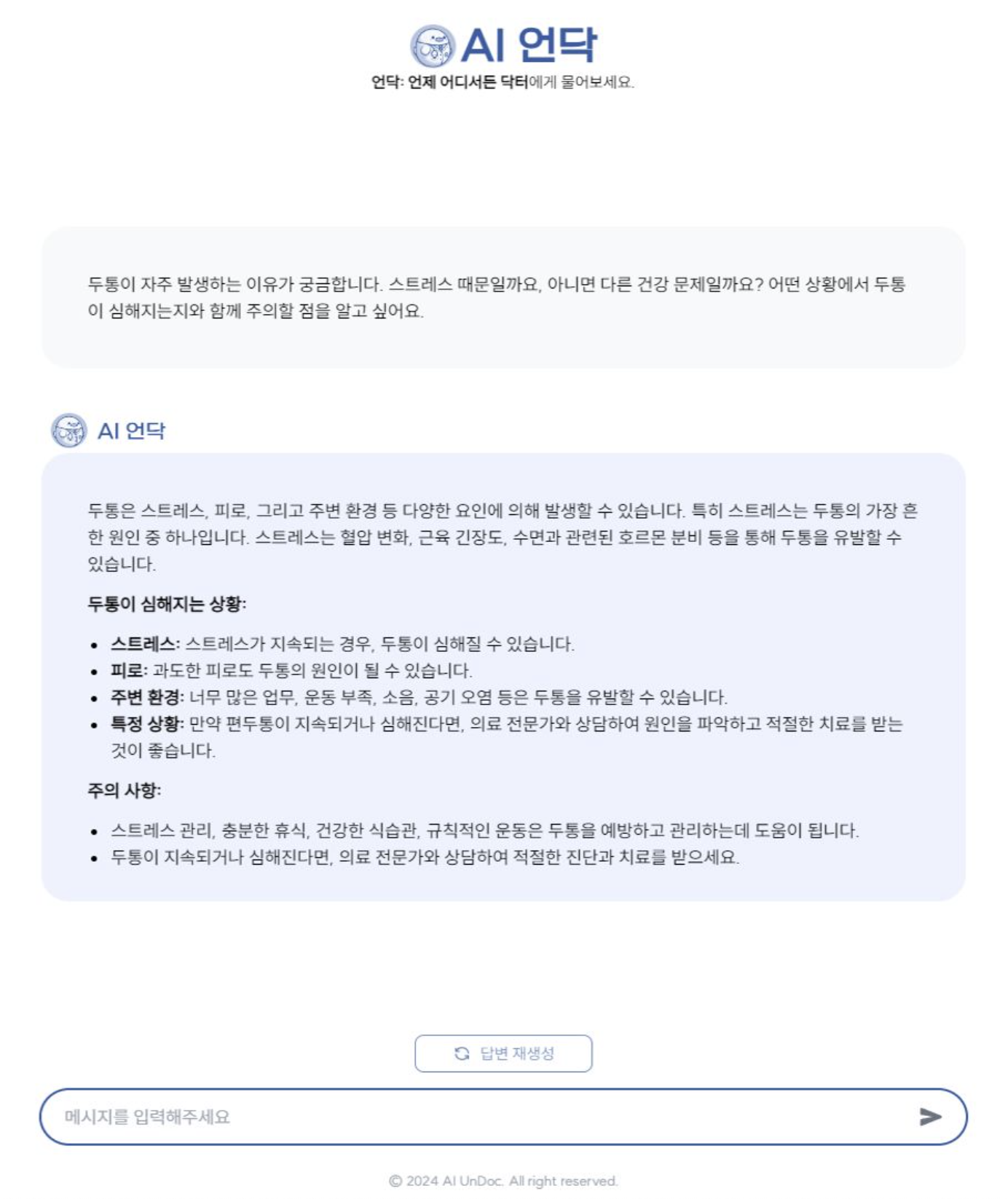
추석 연휴에도 노트북을 들고 다니며 개발을 진행했던 기억이 새롭다.
프로젝트 성과
약 한 달 동안 집중적인 연구와 개발 끝에 우수 프로젝트로 선정되어 구글 ML 부트캠프 수료식에서 전시까지 하게 되었다. 매일 밤 게더타운에 모여 꾸준히 협업한 결과였다.
회고
아직 이론적 기반이 부족한 상태에서도 문제를 해결하고자 다방면으로 직접 부딪혀가며 해결하였다. 이러한 과정에서 처음으로 LangChain 기여자가 되는 경험을 하기도 했다.
RAG와 RAFT라는 최신 NLP 기술들의 경우, 이 프로젝트를 통해 독학으로 먼저 접한 뒤 이후의 네이버 부스트캠프를 통해 더욱 심화된 학습을 하여 지식을 견고히 할 수 있었다.
항상 그렇지만, 단순히 이론을 공부하는 것보다, 현장의 문제들을 겪고 나름의 해결법을 세워 접근해본 뒤 그에 따른 이론을 공부하면 절대 잊을 수 없도록 깊게 이해되는 것 같다.
앞으로도 계속해서 다양한 프로젝트를 경험하고 실질적인 기술을 익히며 성장해 나가고자 한다.
많은 것을 배우고 더 많은 경험을 쌓아, 더 나은 엔지니어가 되기를 다짐하며 이 회고를 마친다.
더 자세히 둘러보기
- RAG + RAFT AI 모델 코드 <FontAwesomeIcon size=”lg” icon={faGithub} />
- 프론트엔드 코드 <FontAwesomeIcon size=”lg” icon={faGithub} />
- RAFT 파인튜닝 모델🤗
- AI Hub 초거대 AI 헬스케어 질의응답 데이터
- RAFT 및 DSF 파인튜닝 예제
댓글남기기