
[DLS]Sequence Models(3)
Andrew Ng 교수님의 Coursera - Deep Learning Specialization 마지막 강의입니다. Encoder-Decoder, Attention, Transformer 등을 다룹니다.
Machine Translation(Encoder-Decoder)
기계 번역의 경우 입력 문장을 해석하는 Encoder 부분과 번역을 생성하는 Decoder 부분으로 나누어져있다. 최종적으로 $\hat{y}^{\langle T_y \rangle}$ 이 <EOS>가 나오면 멈추게 된다.
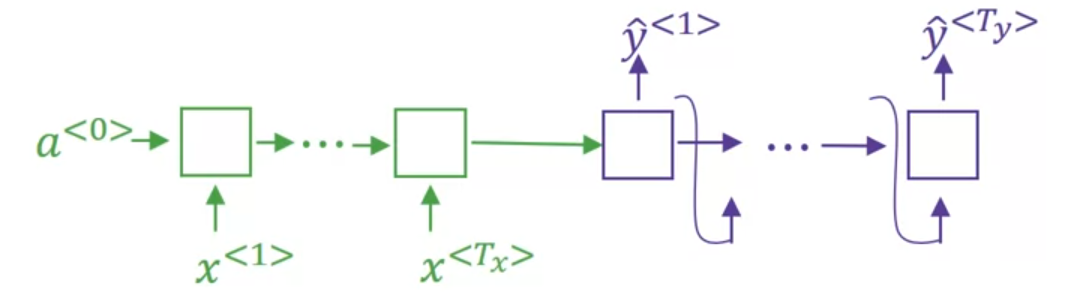
이전 강의의 생성형 언어 모델에서는 다음 단어를 확률 분포에서 선택하였다. 하지만 Machine Translation에서는 가장 최적의 문장을 선택하고 싶기 때문에 방법이 달라진다.
하지만 Greedy하게 매 순간 다음 단어의 확률을 예측하고 최적의 단어를 선택하는 건 최적의 문장이 아닐 수가 있다. 그렇다고 모든 문장에 대한 확률을 평가하기엔 문장의 종류가 많이 때문에 Search Algorithm이 필요하다.
Beam Search
모든 종류의 문장을 확인 할 수 없으니 상단의 몇 개 단어에 대해서 계속 확률을 추적한다.
각 step의 softmax 결과에서 Beam width 개수 만큼의 최상단 단어들을 기억한다. 다음 step이 되어서 기억한 단어에 대해 다음 단어를 예측하면 조합이 총 beam width x vocab size이 나온다. 여기서 다시 beam width 만큼 최상위 확률의 조합을 선택하는 것이다.
Legnth normalization
확률이 가장 높은 문장을 고르기 위해 문장의 확률을 계산하면, 각 단어의 확률을 계속 곱함으로 인해 길이가 길어질 수록 전체 문장의 확률이 낮아진다. 따라서 길이에 따른 패널티를 완화하기 위한 normalization term을 추가한다.
\[\frac{1}{T_y^\alpha}\text{argmax}_y\sum_{t=1}^{T_y}{\log P(y^{<t>} | x, y^{<1>}, ..., y^{<t-1>})}\]- $\alpha$는 heuristic한 값으로 normalization 정도를 변경한다.
- 보통 0.7 같은 값을 사용하곤 한다.
곱하다가 0으로 갈 수 있으니 log scale로 변환하였다.
Beam width
- large B(=100): better result, slow
- small B(=10): worse result, faster
Bleu score(Bilingual Evaluation Understudy)
모델이 생성한 문장을 평가하는 지표이다. 여러개의 좋은 출력 예시가 존재해도 사용 가능하다. 또한 이미지 caption 등의 분야에도 사용할 수 있다.
\[\text{Bleu Score} = BP \cdot \exp\left(\frac{1}{4}\sum_{n=1}^4{P_n}\right)\]- BP(Brevity Penalty): 짧은 출력에 가해지는 패널티 항
- MT_output_length > reference_output_length이면 1
- else
exp(1 − MT_output_length/reference_output_length)
Bleu score on n-grams
\[P_n = \frac{\sum_{ngram \in \hat{y}} count_{clip}(ngram)}{\sum_{ngram \in \hat{y}} count(ngram)}\]n gram이란 연속된 n 개의 단어를 말한다. 생성한 문장에서 각 n-gram들의 count 합계와 각 n-gram의 clip된 count의 합계의 비율이다.
여기서 clip된 count란, 하나의 좋은 출력 예시에서 해당 n-gram이 등장한 횟수까지로 count를 clip했다는 뜻이다.
Attention model
Encoder-Decoder구조는 마치 입력 문장들을 통째로 외우고 이해한 후, 한번에 번역해서 말하는 것과 같다. 문장이 길어지면 길어질수록 이 방식에는 한계가 생길 수 밖에 없으며, 실제 인간들도 다음 번역 단어를 적을 때 원본 문장의 특정 부분에 attention 집중해서 확인 후 번역한다.
즉, Attention 구조란 생성의 각 step에서 입력 문장의 각 단어에 Attention 정도를 다르게 두어 필요한 부분만 읽고 생성하겠다는 것이다.
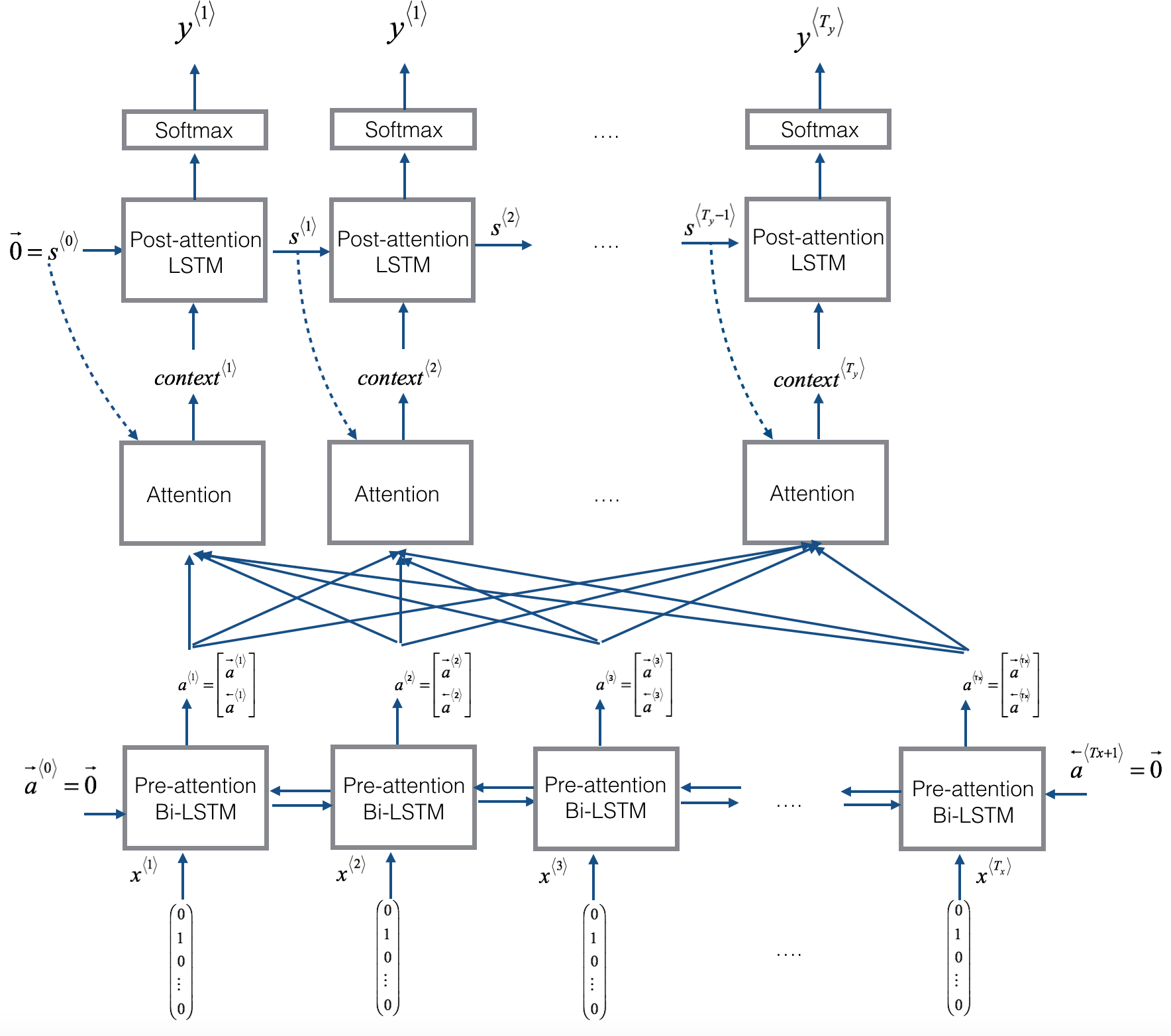
즉, 입력의 어느 부분에 집중하면 될지 계산하는 Attention 파라미터가 추가로 필요하다. Attention의 내부 구조는 아래와 같다.
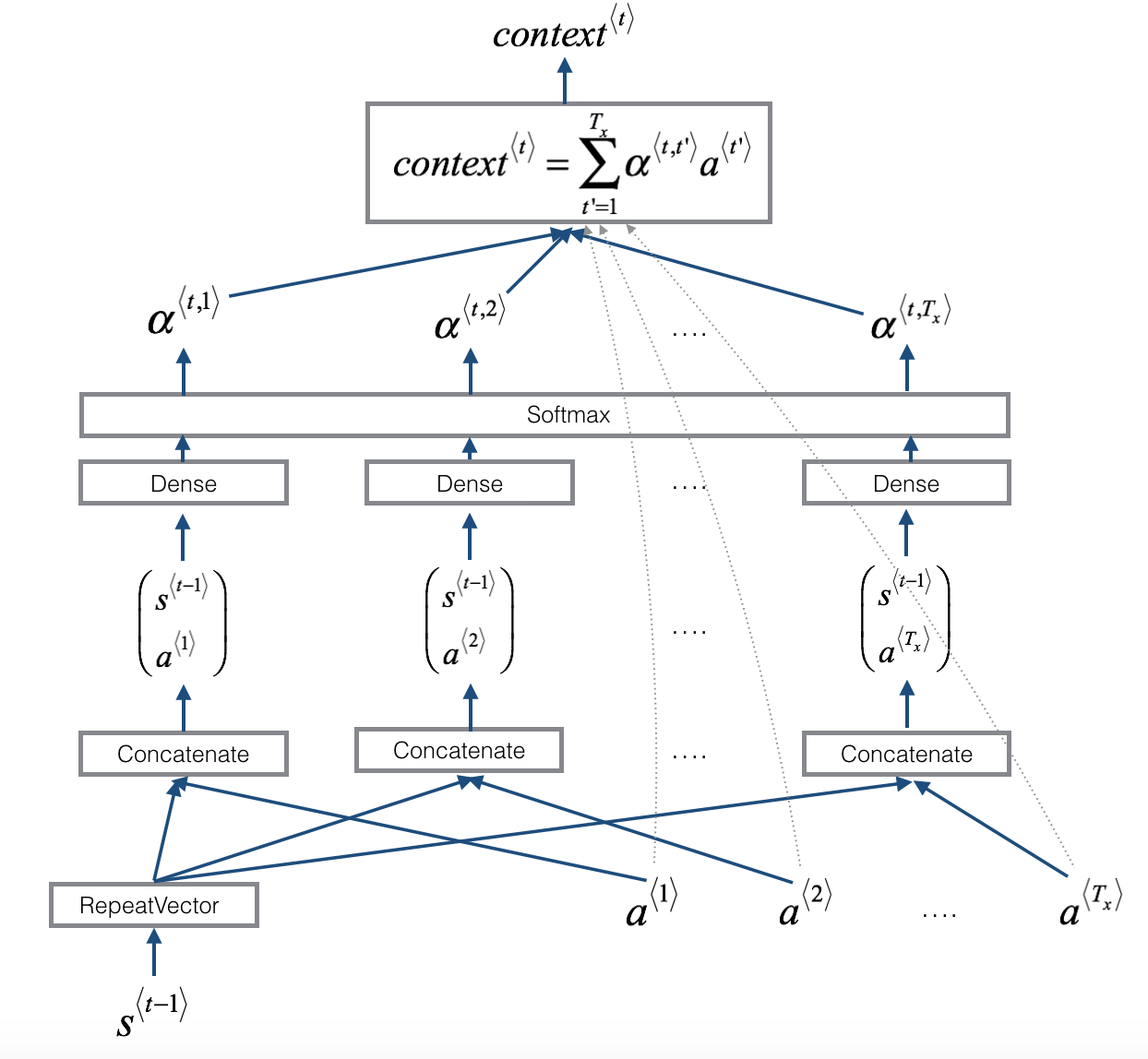
이전 출력 값과 함께 각 입력을 Dense layer를 거쳐 중요도를 판단한다. 각 입력에 대해 attention $\alpha$를 계산하고 softmax를 취해 각 비율에 맞게 더해 현재 step에 맞는 context를 생성한다.
e: Engeies Variable- $s^{\langle t - 1 \rangle}$ 과 $a^{\langle t \rangle}$ 값을 인풋으로 하여 2 layer dense를 거친 값이다.
- $\alpha^{\langle t, t’ \rangle}$: $y^{\langle t \rangle}$ 가 $a^{\langle t’ \rangle}$ 에
pay attention해야하는 정도 - $t$: 출력 y의 timestamp
- $t’$: 입력 x의 timestamp
Transformer Network
RNN과 LSTM 등의 recurrent unit을 사용하지 않고 Q, K, V를 사용해 attention을 병렬로 연산가능하도록 하여 연산 속도를 끌어올렸다
- Attention + CNN style
- 기존 RNN, LSTM들은 순차 실행으로 속도가 느리지만, 마치 CNN 처럼 parellel 연산이 가능하다.
Self-Attention
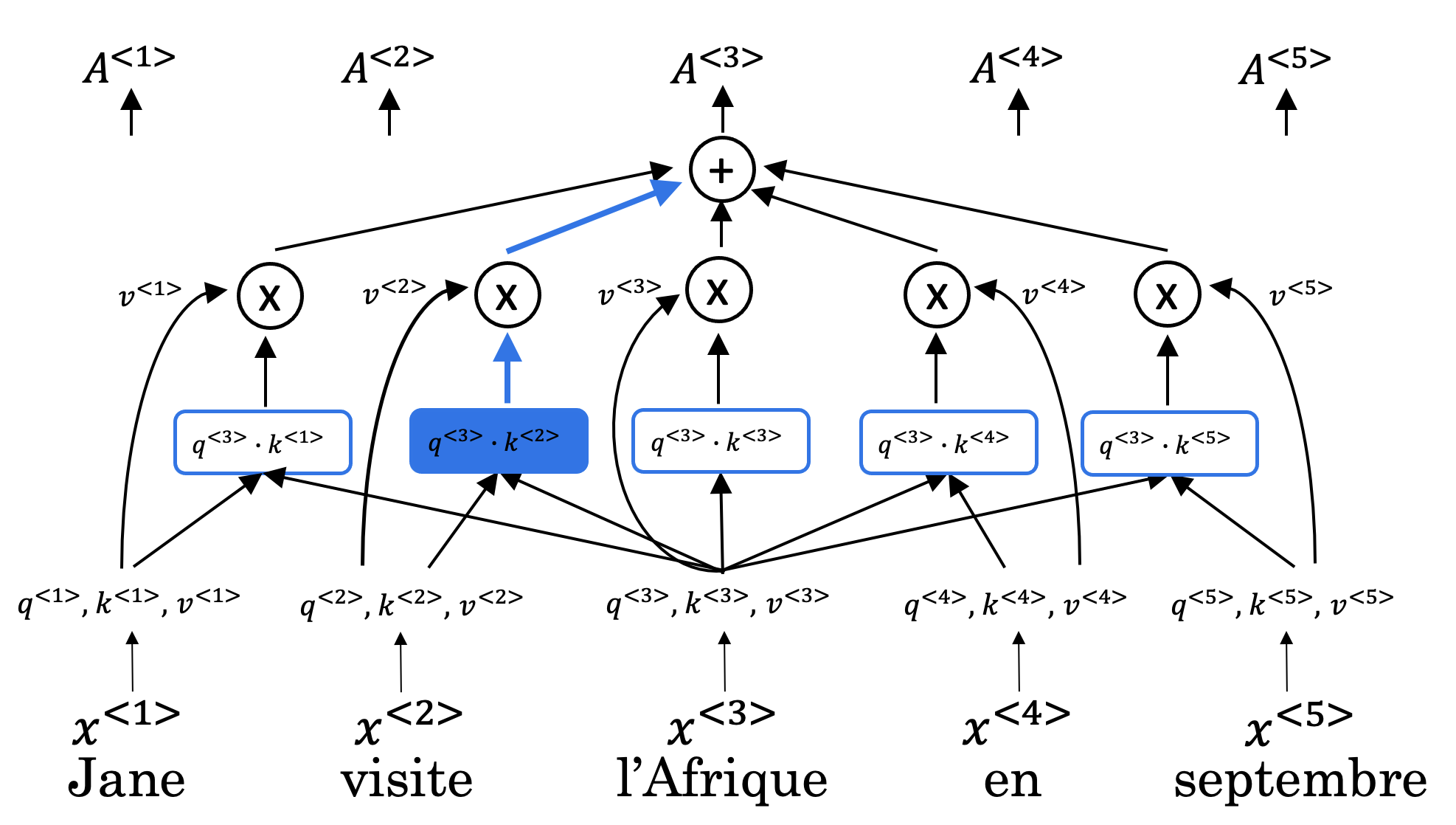
- Q: query; 해당 단어와 관련된 어떠한 질문
- K: Key; 해당 단어가 대답 가능한 질문 유형
- V: Value; 해당 단어의 정보
- M: optional mask
- $d_k$: Key의 차원; softmax가 explode 하지 않게 막는 용도
각 단어의 워드 임베딩에 $W^q, W^k, W^v$를 곱해 q, k, v를 만든다. 이를 이용해 각 단어와 다른 단어들간의 관계를 계산해 각 단어에 pay attention에야 하는 비율을 softmax로 찾아내고 각 value를 곱해 해당 단어의 출력을 구할 수 있다.
Multi-Head Attention
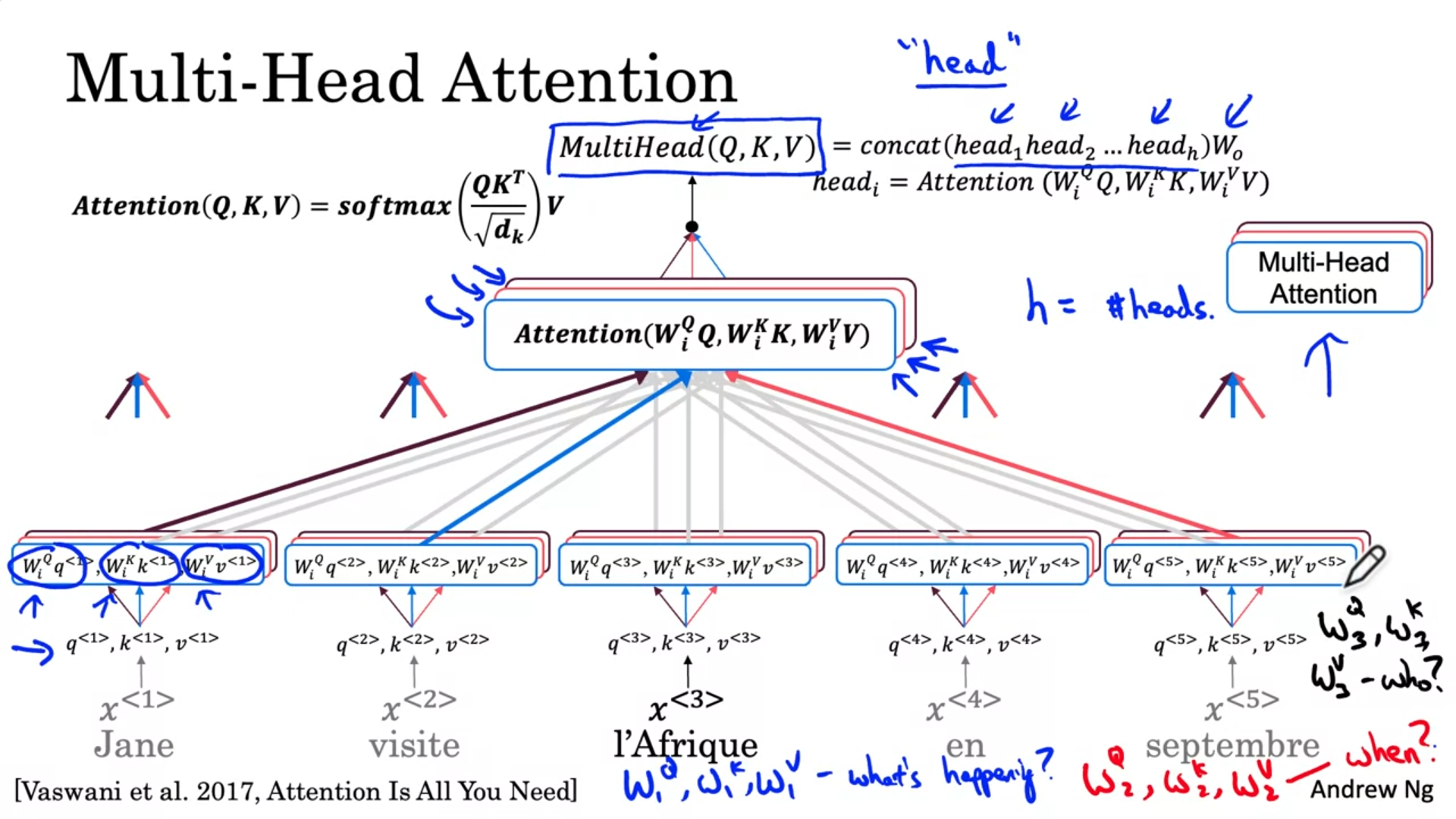
Multi-Head Attention은 각 q, k, v이 head에 대해 다른 값을 갖도록 W를 추가로 곱해서 여러개의 쌍을 만들어 각 head에 대해 Attention을 계산한다.
그렇게 나온 head 값들을 concat 후 변환(W)하여 MultiHead 값을 도출한다.
결국 self-attention의 for loop라고도 볼 수 있다.
실제 구현에서는 vectorization되어 한번에 계산이 가능할 것이다.
Transformer
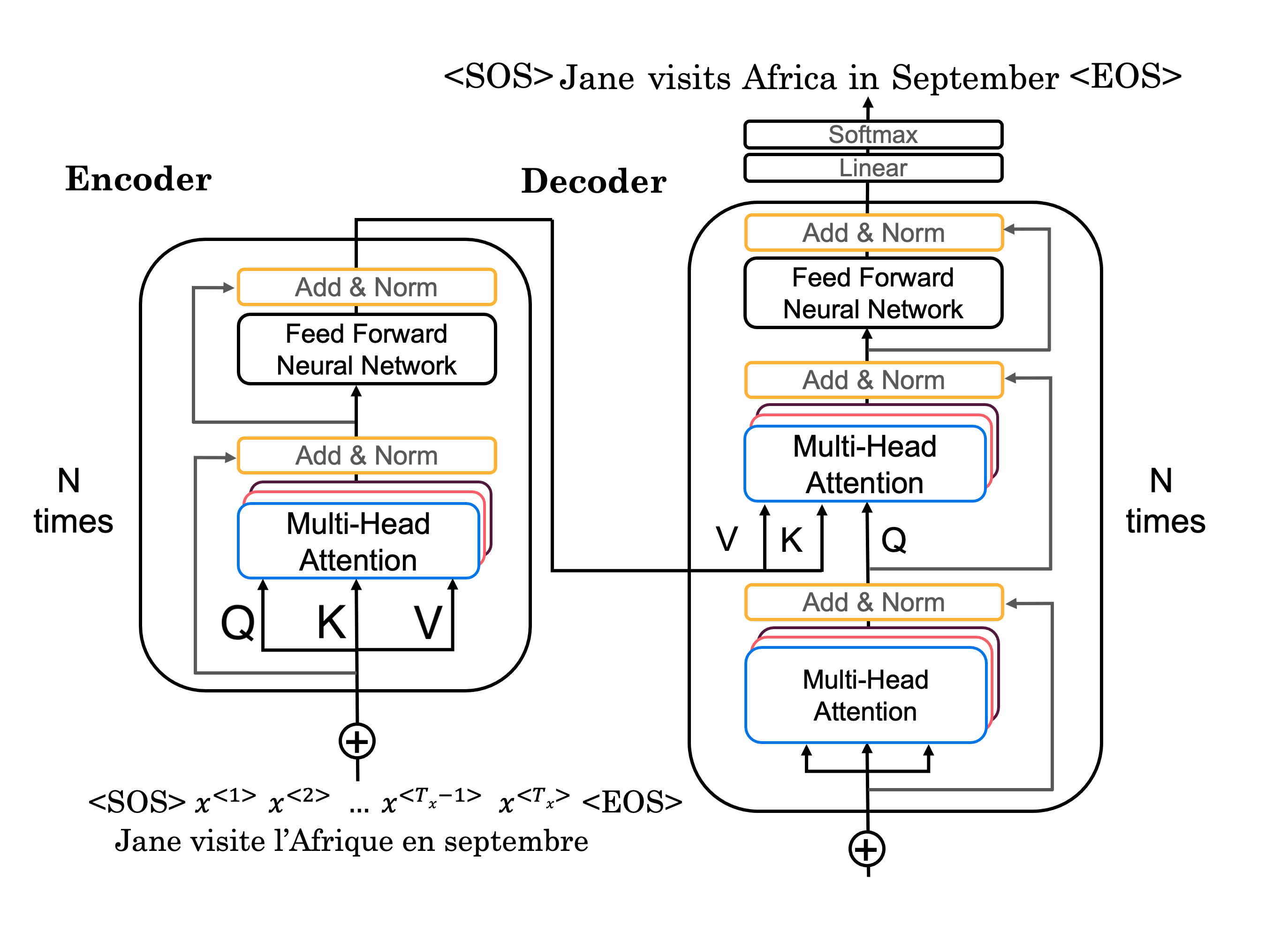
최종적으로 Transformer는 MHA를 사용하여 위와 같은 구조로 구현된다.
- 입력 문장을 word embedding
- embedding에 positional Encoding 추가
- Q, K, V 계산(간단하게는 동일 값 집어 넣을 수도 있음)
- MHA layer 통과
- Residual Connection으로 이전 값 add 후 Layer norm
- dense 2개 층 통과 후 residual 및 layer norm
3, 4, 5, 6의 encoder layer N회 반복- 현재까지 생성된 출력 문장을 word embedding
- embedding에 positional Encoding 추가
- MHA로 값 계산
- 마찬가지로 residual 및 layer norm
- 계산된 값을 Q로만 넣고 encoder 값을 V, K로 삼고 MHA
- 역시 residual 및 layer norm
- dense 2개 통과 및 residual, layer norm
10, 11, 12, 13, 14N회 반복- Linear(dense) 및 softmax로 다음 단어 예측
<EOS>가 나올 때까지8~16반복
Positional Encoding
Transformer는 병렬 처리로 인해 단어의 순서 정보가 사라진다. 따라서 순서 정보를 추가하기 위해 입력 데이터에 positional encoding 값을 더해준다.
- $d$: Word Embedding의 차원(postion encoding도 같은 차원으로 나옴)
- $pos$: 현재 단어의 position
- $k$: 포지션 인코딩 벡터의 각 index; $i = k // 2$
이런 값을 사용하는 이유는 다음과 같다.
- sin과 cos은
-1 ~ 1사이 값으로 word embedding 값을 덜 왜곡한다. - 모든 pos encoding의 벡터의 norm은 동일하다.
- 자리가 t 만큼 떨어진 encoding 벡터의 차이의 norm도 일정하다.
회고
드디어 구글 ML 부트 캠프에서 제시했던 Coursera Deep Learning Specialization 강의를 완강하였다. 7월안에 끝마치고 싶었지만 내용이 학습 난이도가 높아 8월 중반이 되어서야 끝이 났다.
요즘 네이버 부스트 캠프도 함께 수강하며 잠잘 시간도 부족했는데 한숨 돌릴 수 있을 것 같다. 아쉬운 점은 부트 캠프 2개를 동시에 하느라 4강 중반부터는 내용 정리에 이전처럼 시간을 많이 투자하지 못했다는 것이다.
그래도 드디어 강의 수강이 끝났으니 kaggle에 집중해 도전해봐야겠다.
Thanks to
Andrew Ng 교수님이 정말 강의를 잘 하십니다. 핵심적인 내용들을 아주 직관적이고 이해하기 쉽도록 설명해주시고 Model의 수식을 일목요연하게 정리해주십니다.
덕분에 1차적으로 모델이 고안된 이유를 이해할 수 있었고, 2차적으로 모델의 세부적인 수식을 정확히 알 수 있었으며, 마지막으로 왜 이러한 수식을 사용했는지 수식의 의미를 이해할 수 있었습니다.
앞으로 누가 딥러닝을 공부하고 싶다고 한다면 망설임없이 해당 DLS 과정을 추천할것 같네요. 한달 반동안 많은 걸 배웠습니다!
ps. coursera에서 제시하는 학습 기간은 17주 과정이지만 전 7주만에 들었습니다😂
댓글남기기