
GPT 5.4 출시 - Agent 성능 대폭 향상과 SOTA 등극
OpenAI가 GPT 5.4를 출시했다. Tool Calling, Computer Use 등 Agent 성능이 크게 향상되었으며, 주요 벤치마크에서 타 모델들을 확연히 이기며 명실상부한 SOTA에 등극했다.
Weekly Tech Trend Talk 스터디(26.03.12)
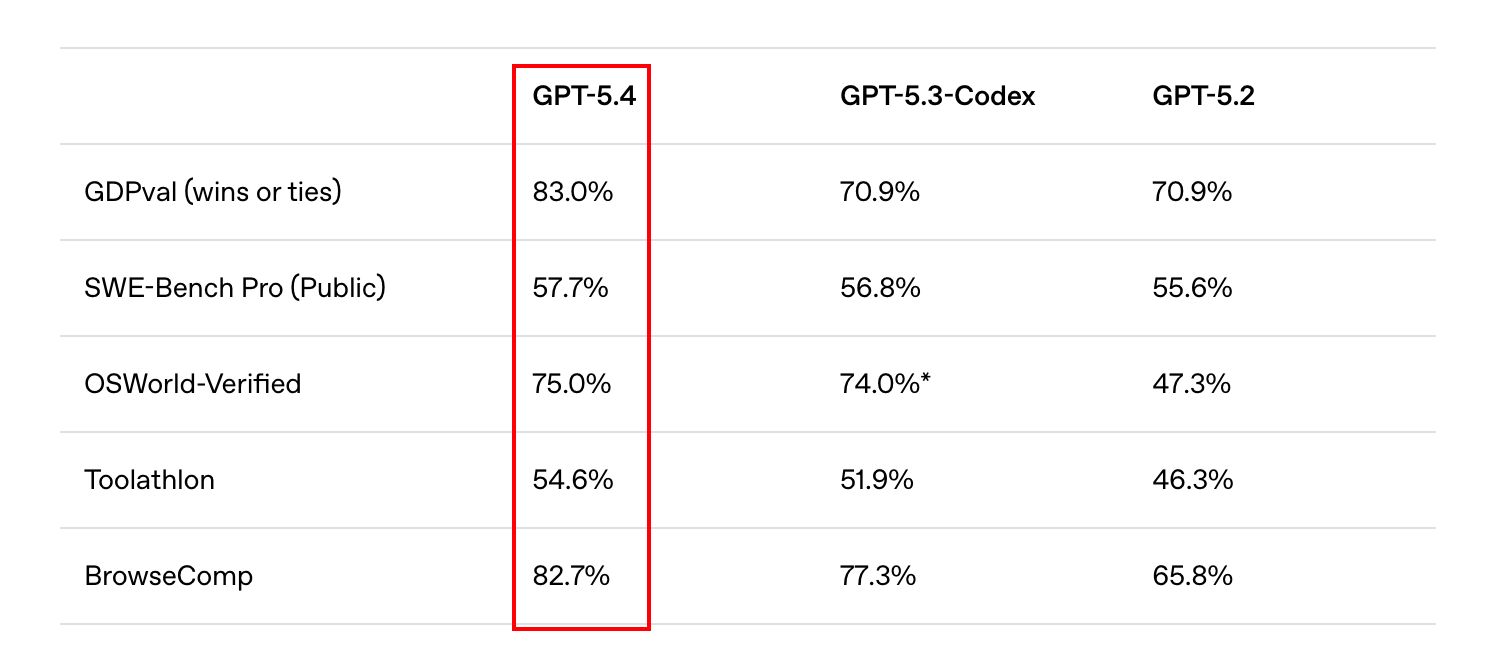
GPT 5.4는 GDPval 83.0%, SWE-Bench Pro 57.7%, OSWorld-Verified 75.0%, Toolathlon 54.6%, BrowseComp 82.7%로 GPT-5.3-Codex와 GPT-5.2를 모든 항목에서 앞섰다.
GDPval - 업계 전문가 기준선 돌파
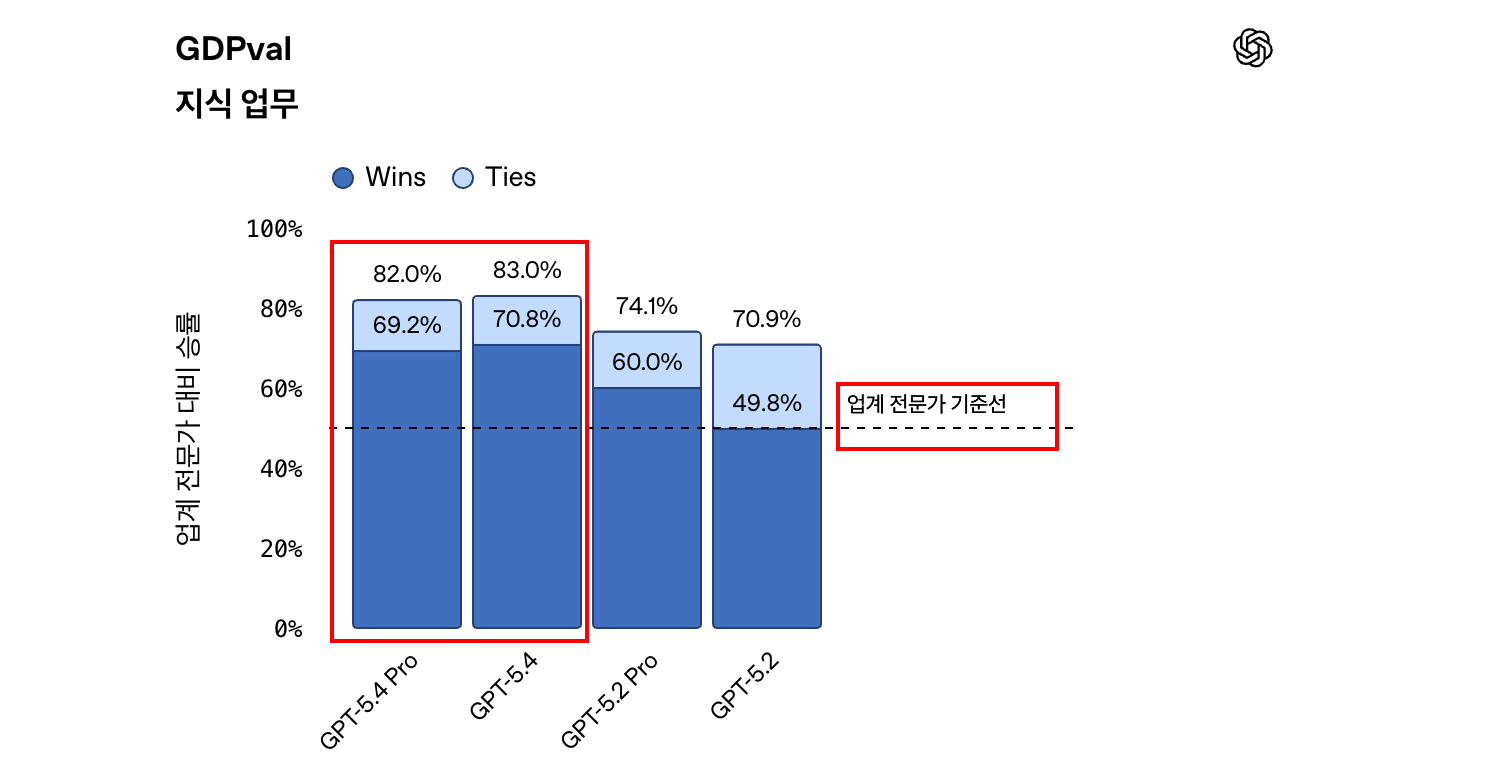
경제적으로 가치 있는 지식 업무를 평가하는 GDPval 벤치마크에서 GPT 5.4가 업계 전문가 기준선(약 50%)을 확실히 넘어섰다.
GPT-5.4 Pro는 Win 69.2% + Tie 12.8% = 82.0%, GPT-5.4는 Win 70.8% + Tie 12.2% = 83.0%를 기록했다. GPT-5.2 Pro(74.1%), GPT-5.2(70.9%)와 비교하면 확연한 차이를 보인다.
OSWorld-Verified - 데스크탑 조작 능력
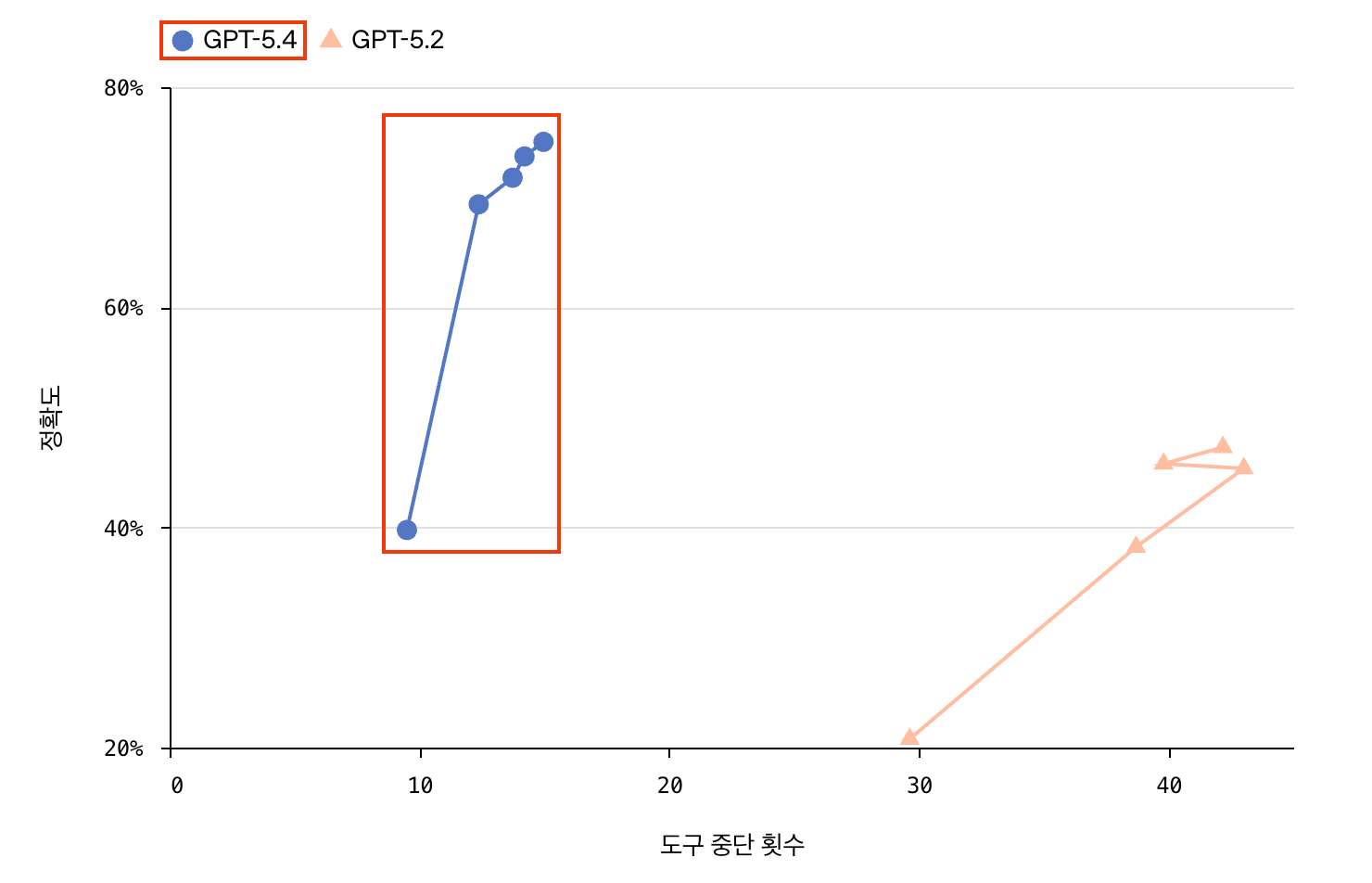
OSWorld-Verified는 스크린샷과 키보드, 좌표 기반 마우스 조작을 통해 데스크탑 환경을 탐색하는 능력을 평가하는 벤치마크다.
GPT 5.4는 도구 중단 횟수(tool call) 8~17회로 정확도 40~75%를 달성한 반면, GPT 5.2는 28~43회의 도구 호출로 20~50% 정확도에 그쳤다. 더 적은 도구 호출로 더 높은 정확도를 달성한 것이 핵심이다.
Computer Use - 빌트인 지원
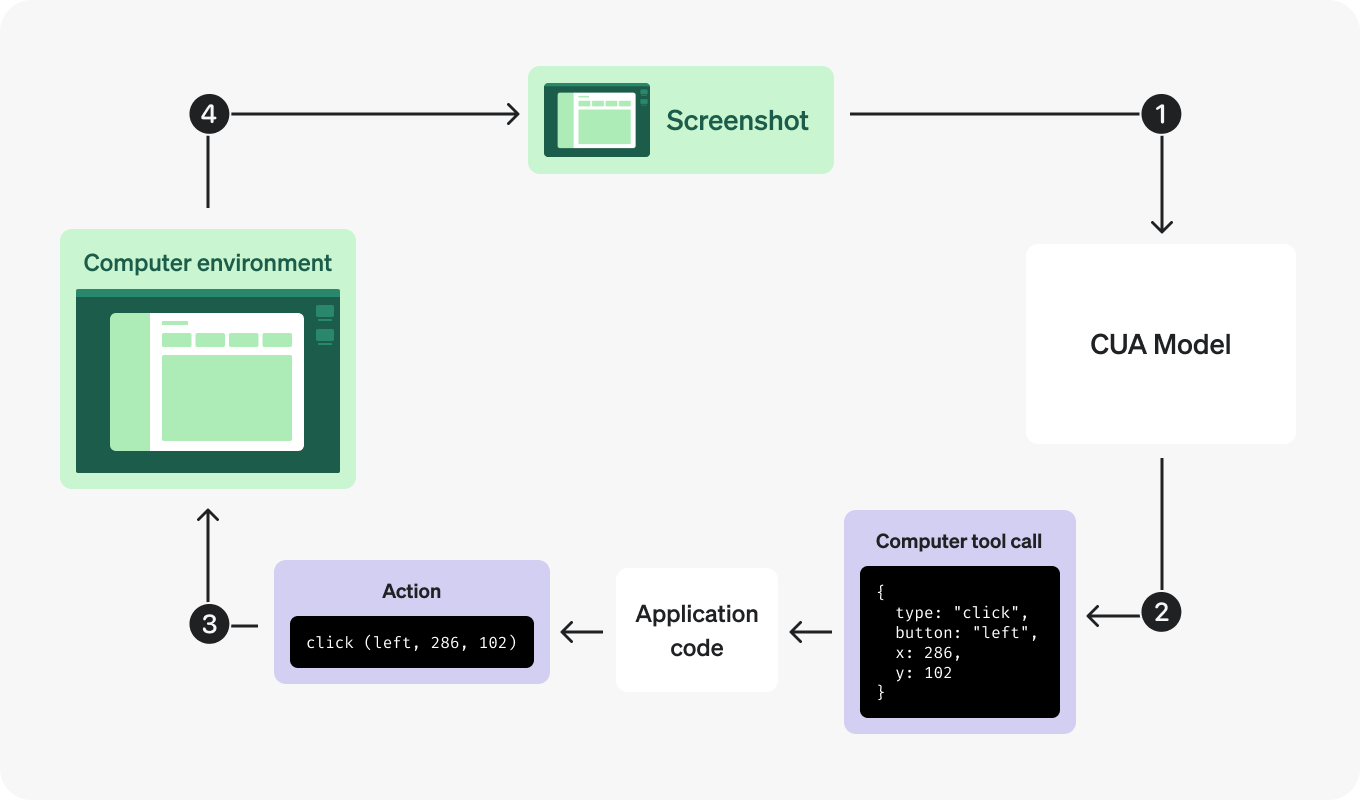
OpenAI가 GPT 5.4부터 빌트인 Computer Use 기능을 도입했다. 기존에는 Computer Use를 위해 별도의 모델을 사용해야 했지만, 이제 GPT 5.4에서 직접 지원한다.
동작 흐름은 다음과 같다:
- 스크린샷을 CUA Model에 전달
- 모델이 Computer tool call 생성 (예:
click(left, 286, 102)) - Application code가 Action을 실행
- Computer environment에서 새 스크린샷 캡처 후 다시 1번으로
from openai import OpenAI
client = OpenAI()
response = client.responses.create(
model="gpt-5.4",
tools=[{"type": "computer"}],
input="Check whether the Filters panel is open. If it is not open, click Show filters. Then type penguin in the search box. Use the computer tool for UI interaction.",
)
print(response.output)
응답 예시:
{
"output": [
{
"type": "computer_call",
"call_id": "call_002",
"actions": [
{ "type": "click", "button": "left", "x": 405, "y": 157 },
{ "type": "type", "text": "penguin" }
],
"status": "completed"
}
]
}
물론 기존 방식인 Playwright MCP 활용 등의 방식도 더 뛰어나졌다.
Tool Search - 토큰 절감을 위한 도구 검색
Tool Search는 대량의 도구를 효율적으로 관리하기 위한 새로운 기능이다.
defer_loading을 설정한 함수는 모델에게 함수 이름과 설명만 전달되고 parameter schema는 숨겨져서 토큰을 절약할 수 있다.
모델이 도구 검색을 수행할 경우, defer_loading이 설정된 함수/네임스페이스/MCP를 보고 다시 도구를 선택한다.
from openai import OpenAI
client = OpenAI()
crm_namespace = {
"type": "namespace",
"name": "crm",
"description": "CRM tools for customer lookup and order management.",
"tools": [
{
"type": "function",
"name": "get_customer_profile",
"description": "Fetch a customer profile by customer ID.",
"parameters": {
"type": "object",
"properties": {
"customer_id": {"type": "string"},
},
"required": ["customer_id"],
"additionalProperties": False,
},
},
{
"type": "function",
"name": "list_open_orders",
"description": "List open orders for a customer ID.",
"defer_loading": True,
"parameters": {
"type": "object",
"properties": {
"customer_id": {"type": "string"},
},
"required": ["customer_id"],
"additionalProperties": False,
},
},
],
}
response = client.responses.create(
model="gpt-5.4",
input="List open orders for customer CUST-12345.",
tools=[
crm_namespace,
{"type": "tool_search"},
],
parallel_tool_calls=False,
)
print(response.output)
토큰 절감 효과
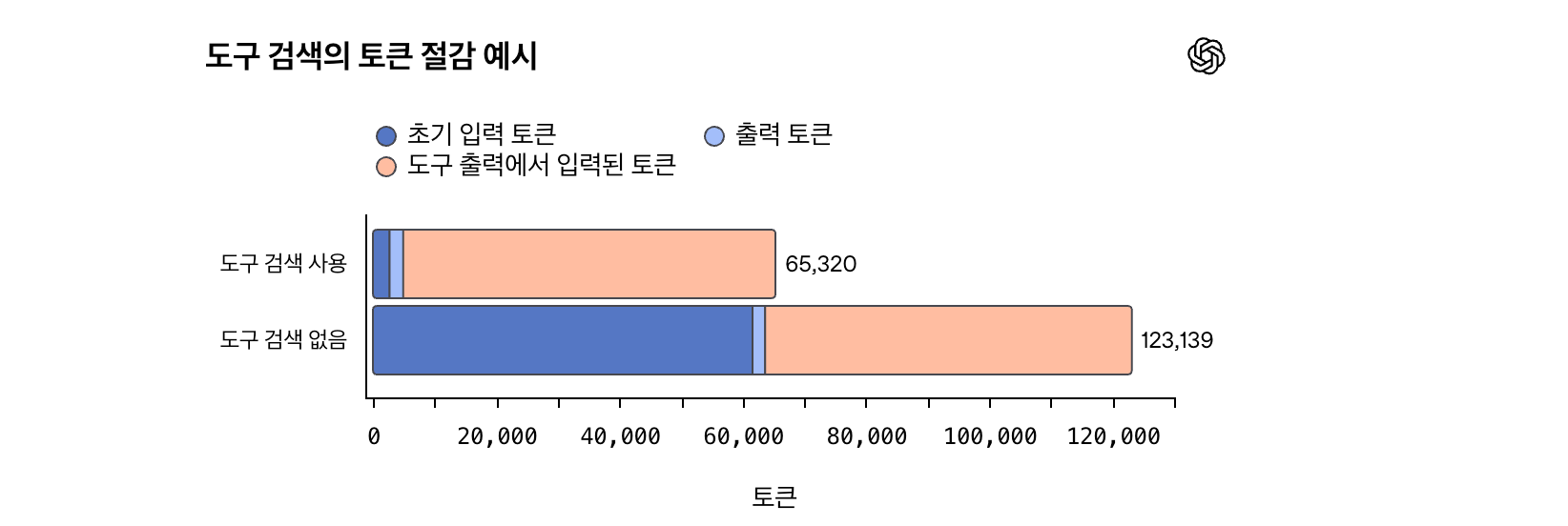
도구 검색을 사용하면 총 65,320 토큰으로 처리되지만, 사용하지 않으면 123,139 토큰이 필요하다. 약 47%의 토큰 절감 효과를 보여준다.
추가 벤치마크
Abstract Reasoning
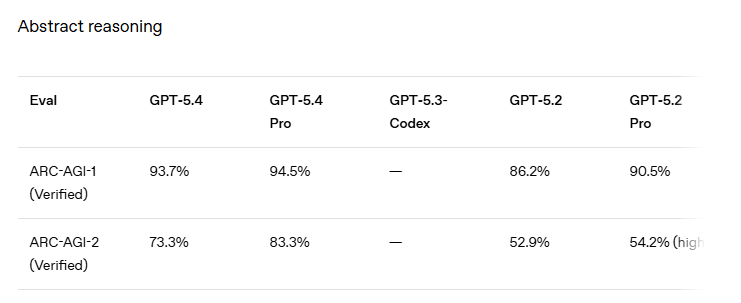
ARC-AGI-1(Verified)에서 GPT-5.4는 93.7%, GPT-5.4 Pro는 94.5%를 기록했다. ARC-AGI-2(Verified)에서는 GPT-5.4가 73.3%, GPT-5.4 Pro가 83.3%로, GPT-5.2(52.9%) 대비 크게 향상되었다.
FrontierMath

FrontierMath에서도 GPT-5.4가 새로운 기록을 세웠다. Tiers 1-3에서 GPT-5.4 Pro가 가장 높은 성적을 기록했으며, Tier 4에서도 GPT-5.4 Pro(web app)가 Opus 4.6(max), Gemini 3 Pro를 크게 앞섰다.
모델 스펙
| 항목 | 사양 |
|---|---|
| Context Window | 1M 50K |
| 최대 출력 토큰 | 128K |
| 지식 Cut-off | 2025.08.31 |
댓글남기기