
[Week 7]NLP 기초 프로젝트
문장 유사도 측정 프로젝트를 위한 기초 지식들을 다룹니다.
NLP Benchmarks
GLUE(General Language Understanding Evaluation)
자연어 이해 능력을 평가하고 분석하기 위한 데이터셋
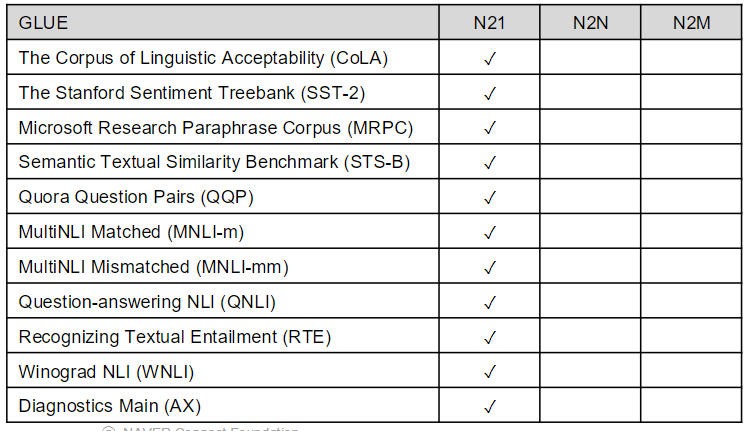
Super GLUE
GLUE의 후속 벤치마크. 조금 더 어려운 언어 이해 작업 및 N2N 문제가 추가되었다.
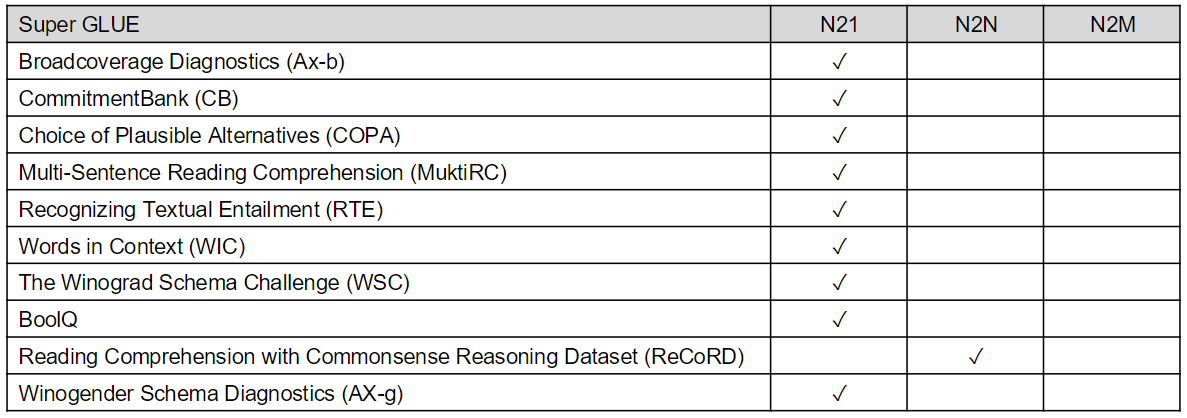
KLUE
GLUE와 유사한 한국어 NLP Benchmark
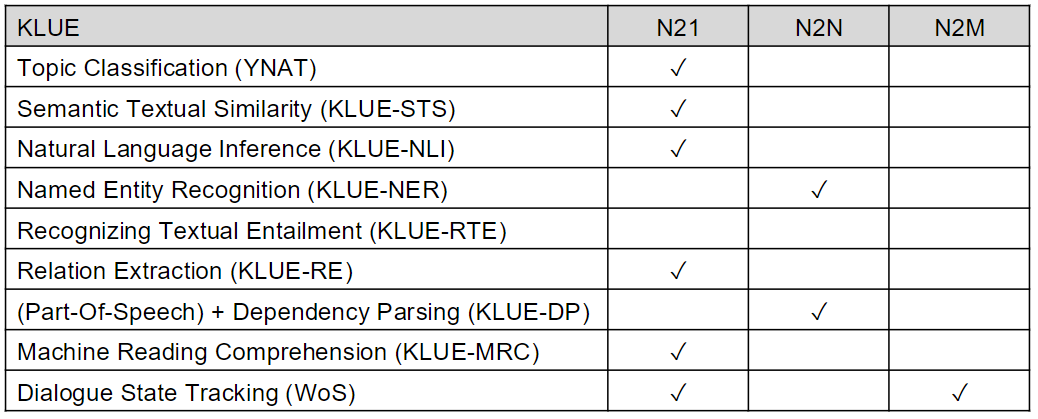
MMLU(Massive Multitask Language Understanding)
Language Model을 평가하는 용도로 사용된다. 다양한 지식 분야의 객관식 문제로 이루어져있다.
Chatbot Arena
여러 언어 모델들이 생성하는 응답을 사람들이 직접 더 나은 응답을 선택하는 식으로 아레나를 만들어두었다.
데이터셋으로 평가하는 것이 아닌 사람들의 선택으로 모델의 순위를 매긴다.
Chatbot Arena: An Open Platform for Evaluating LLMs by Human Preference
마치 언어모델 월드컵 같다.
HellaSwag
문장 완성을 통해 LLM 모델의 상식적인 추론 능력을 평가한다. 4개의 선택지 중에서 적절한 말을 선택할 수 있는지 평가한다.
Tokenizer
Byte-Level BPE
글자 단위 BPE가 아닌 Byte 단위로 BPE를 적용한다. 아스키 코드와 달리 다국어 환경 및 이모지 등의 unicode의 경우 글자 수가 너무 많기 때문에 글자 단위가 아닌 Byte 단위로 BPE를 수행하기도 한다.
WordPiece
\[Score = \frac{\text{freq of pair}}{\text{freq of first element} \times \text{feq of second elemnt}}\]위 Score 식을 기준으로 모든 토큰쌍에 대해 점수가 높은 쌍을 사전에 추가한다.
- BPE와 달리 단순 빈도가 아닌 Score 기반이다.
- Score는 같은 빈도의 pair라도 두 Token이 개별적으로 더 많이 등장한다면 패널티가 주어진다.
Unigram
unigram은 일단 가능한 모든 토큰 조합을 단어장에 추가하고, loss 값을 계산하여 loss가 가장 커지는 토큰부터 삭제한다.
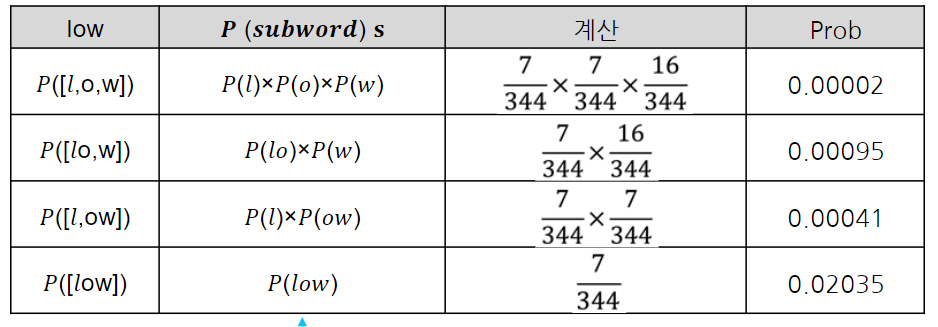
어떤 토큰을 사용했을 때와 안했을 때의 loss를 각각 계산해서 비교하고 제거한다.
세부적인 것은 다른 문서를 확인하여 공부해보자.
Language Model들의 tokenizer
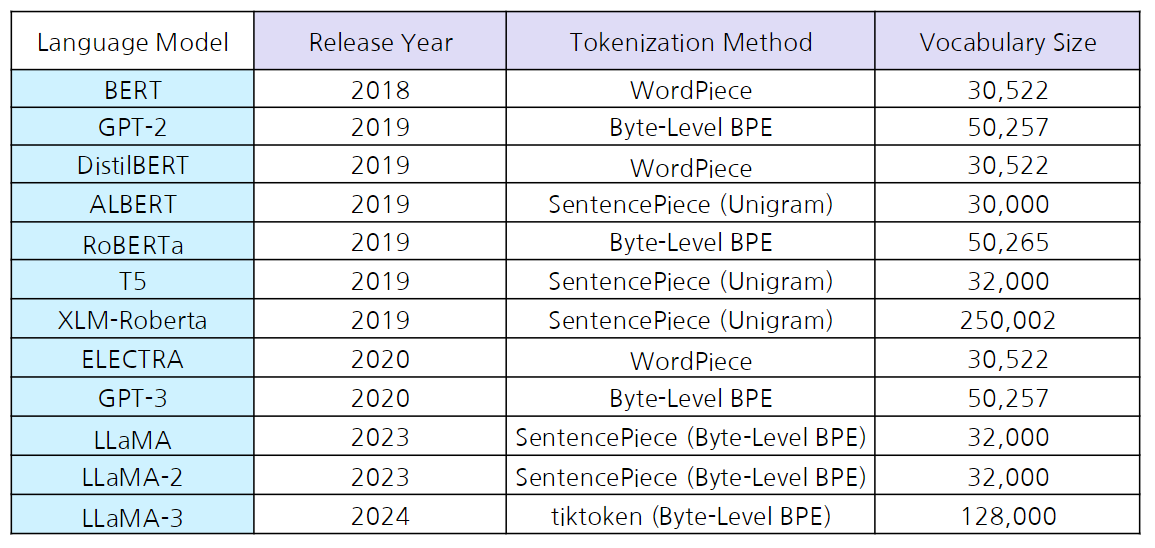
최근에는 결국 의미 기반(형태소 기반) 보단 BPE 계열의 데이터 기반 토크나이저를 대부분 사용중이다.
TF-IDF(Term Frequence - Inverse Document Frequency)
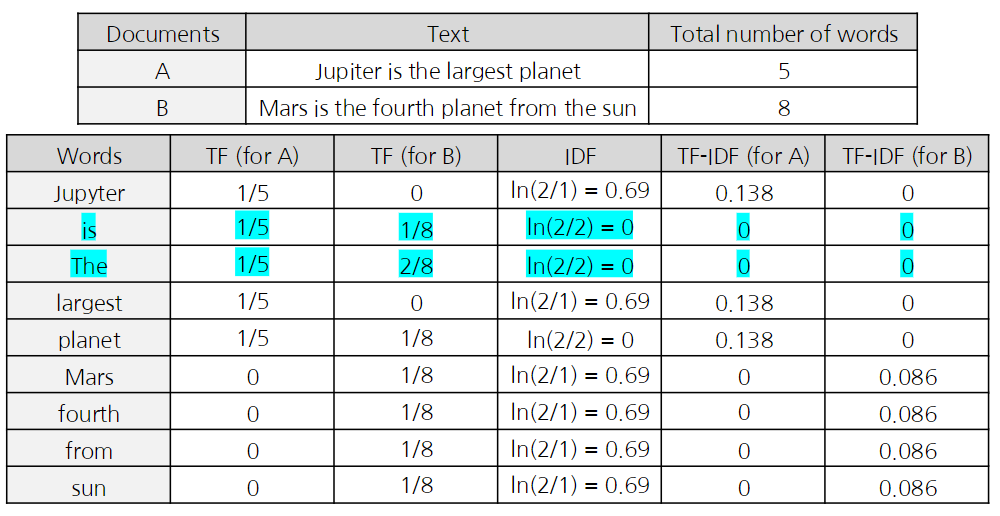
문장에서 각 단어의 가중치를 만들어 핵심 단어를 찾는 방법
docs = [
'먹고 싶은 사과',
'먹고 싶은 바나나',
'길고 노란 바나나 바나나',
'저는 과일이 좋아요'
]
# 총 문서의 수
N = len(docs)
def tf(t, d):
return d.count(t)
def idf(t):
df = 0
for doc in docs:
df += t in doc
return log(N/(df+1))
def tfidf(t, d):
return tf(t,d)* idf(t)
- idf는 df(특정 단어 t가 등장한 문서의 수)를 반전(inverse) 시킨 것이다.
Metrics
출력 형태에 따라 다양한 Pereformance Metrics가 존재한다.
Confusion Matrix
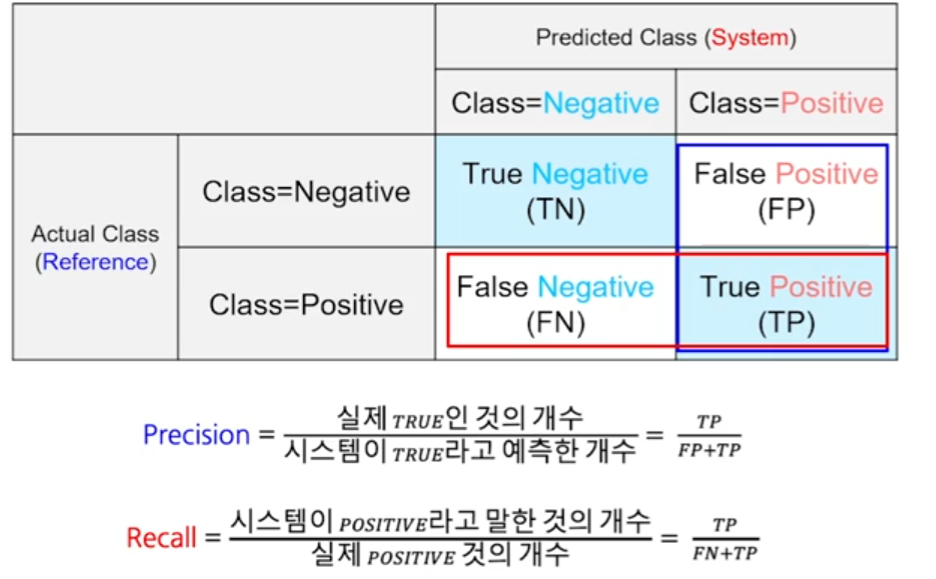
F1 score
confusion matrix를 기반으로 계산된다.
\[F1 = 2 \times \frac{\text{precision} \times \text{recall}}{\text{precision} + \text{recall}}\]ROC(Receiver Operating Curve) / AUC(Area Under ROC)
classification type의 soft decision의 metric이다.
분류기의 threshold를 변경했을때 나오는 곡선이다. AUC는 ROC의 아래 면적으로 AUC가 높을수록 분류기의 성능이 높다는 걸 의미한다.
Sequential
생성형 언어 모델 같은 경우, BLEU 등 유사도 평가를 적용할 수 있다.
Multiple label
여러개의 라벨이 출력 되는 경우이다.
- Exact match Ratio
- 0/1 Loss
- Auccuracy
- Hamming Loss
- Precision, Recall, F1
등을 사용 가능하다.
Mutliple Rank
RAG 같은 임베딩의 검색 시스템의 경우 유사도에 따라 등수가 출력된다. 이에 대한 평가를 아래의 지표들을 활용가능하다.
- F1 @ k
- 순서 반영되지 않음
- Precision @ K
- K 개까지의 랭킹을 확인하고 관련 있는지 확인하여 몇개가 성공했는지 검사
- Recall @ K
- 실제 일치하는 데이터들 중 몇개가 리턴되었는지 검사
- MRR(Mean Reciprocal Rank)
- Q개의 query들에 대해 각각 정답이 몇번째에 처음 등장했는지 확인하여 rank를 계산한다.
- 이 등수의 역수를 평균내어
MRR값을 도출한다.
- AP(Average Precision)
- P(k):
Precision@k - rel(k): k번째 문서가 연관된 경우면 1
- 즉, 연관 문서들에 대해서
Precision@k를 평균 냄
- 즉, 연관 문서들에 대해서
- P(k):
Ansemble Methods
- N21, N2N에 적용 가능
- Voting
- Bagging
- Boosting
- N2M에도 적용 가능
- Average Log-probability
- MoE
- Router
PEFT(Parameter Efficient Fine Tuning)
- 일부 레이어만 튜닝
- 파라미터 보정
- LoRA(Low Rank Adapatation)
- 매우 낮은 rank; r=5; 로 기존 weight 옆에 adapter를 붙여 이것만 학습
- hideen states 보정
- ReFT(Representation Finetuning)
- hidden state 즉, representation에 집중하여 보정하기 위해 새로운 행렬을 추가하여 이것만 학습
N21 문제
N 시퀀스의 자연어로 한가지 값을 만드는 문제
Instance-based Classification
- Non-Trainable
- 단순히 데이터 셋을 임베딩을 한 뒤 KNN과 같은 방식으로 분류를 할 수 있다.
- Trainable
Triplet Loss를 활용하여Anchor/Positive/Negative의 임베딩에서의 거리를 가깝거나 멀게 조정할 수 있다.- 이후 역시 유사도를 검사하여 분류할 수 있다.
Head-based Classification
기존 모델의 결과 에 MLP Head를 붙여 원하는 차원의 데이터를 얻어낸다. 이를 통해 분류 혹은 회귀 문제를 해결할 수 있다.
N2M 문제
주로 입력 시퀀스를 기반으로 새로운 시퀀스를 생성해야하는 문제이다. decoder가 필수적으로 필요하며 auto-regressive하게 동작한다.
번역, 요약, QA 등 다양한 Task가 존재한다.
Evaluation
ROUGE(Recall-Oriented Understudy for Gisting Evaluation)
주로 요약 task에서의 평가지표로 활용된다.
recall 기반으로 평가한다.
ROUGE-L은 정답과 예측의 LCS 길이의 ROUGE score를 따른다.
ROUGE-L이 45점 정도이면 우수하다고 볼 수 있다.
BLEU
주로 번역 task에서의 평가지표로 활용된다.
precision 기반이며 기본적으로 1-gram부터 4-gram 까지의 일치를 계산하여 합한다.
BLEU가 30점 이상이면 우수하다고 볼 수 있다.
댓글남기기