
[Week 5]NLP theory
이번주는 Transformer와 Bert에 대해 자세히 공부하였습니다.
Transformer
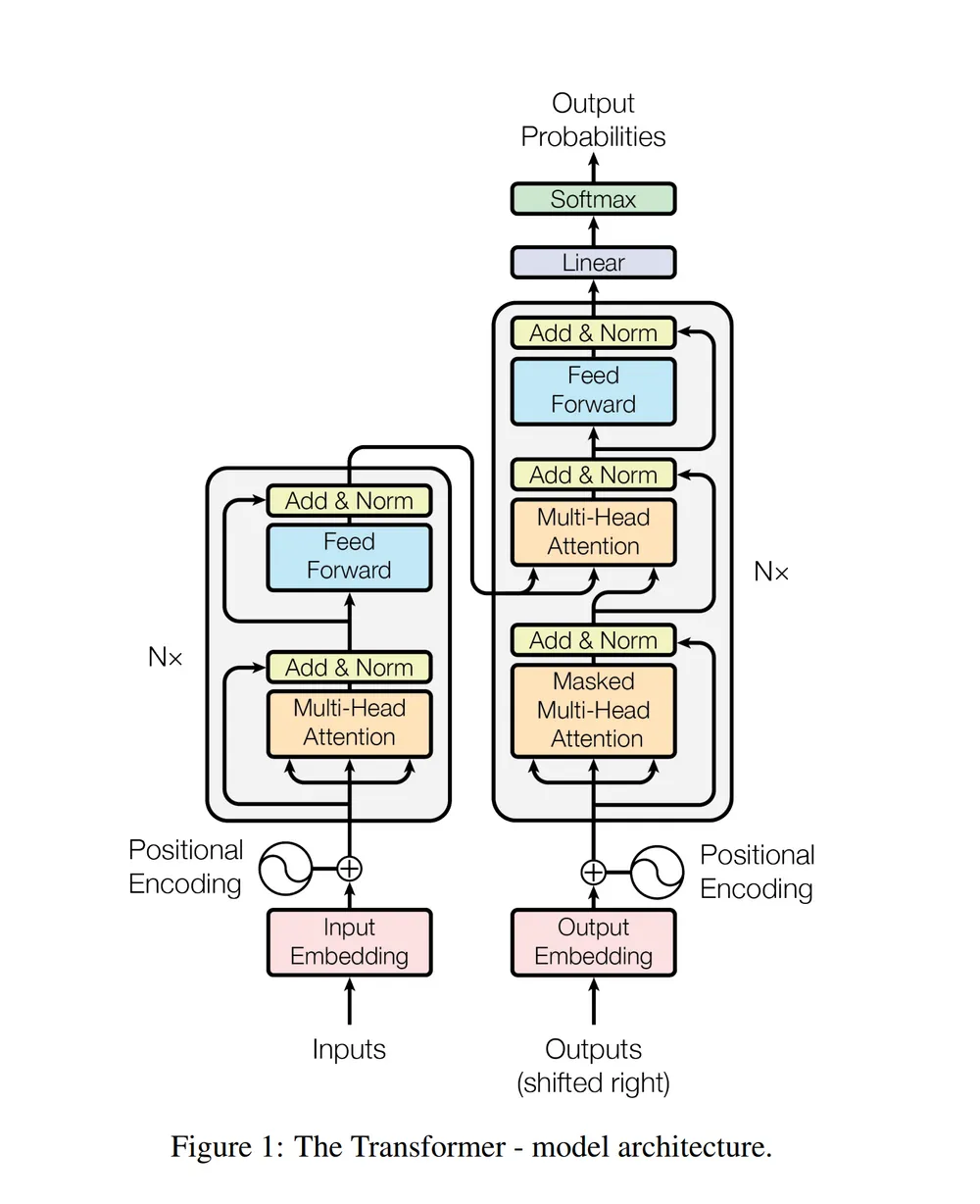
RNN 계열은 입력 sequence를 하나씩 반복해서 읽어야만 하고, 이는 속도 저하와 함께 먼 거리의 token들에 대해 vanishing이 일어나게 된다. 이에 대한 해결로 attention 매커니즘을 통한 각 입력 sequence에 대해 직접 연결을 하도록 self-attention을 도입하였다.
Self-Attention(Dot-Product)
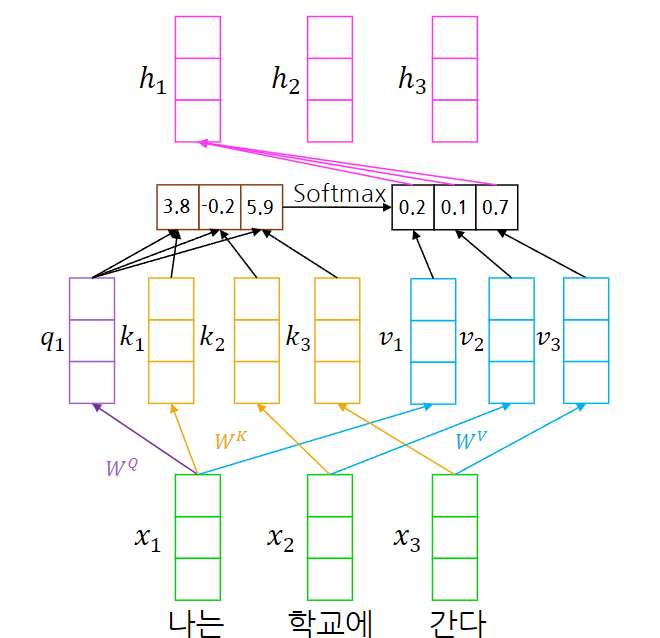
- “나는 학교에 간다” 문장에서의 “나는”에 대한 attention 계산
각 입력 토큰은 Query, Key, Value로 선형 변환 되고 이를 통해 attention을 계산한다.
이미지의 예시를 보면, 나는에 대한 query vector와 모든 token들의 key vector를 doct product를 통해 유사도를 계산한다. 각 dot product 값(scalar)들에 softmax를 적용하여 해당 token이 다른 token들에 주의(attention)를 기울여야하는 비율을 얻을 수 있다.
softmax로 구한 각 attention 정도의 비율로 각 token들의 value vector를 가져와 더해 최종 해당 token에 대한 attention layer 출력을 얻을 수 있다.
이것을 모든 token에 대해 연산하여 입력 sequence를 attention을 통해 다른 token들과의 관계를 적절하게 반영한 encoding 표현을 얻을 수 있다.
Scaled Dot-Product Attention
attention은 앞서 말한 것과 같지만, 그대로 적용하기에 한가지 문제가 있을 수 있다. Key의 차원(= query의 차원)이 커지면 커질 수록 분산이 커진다는 문제이다.
query와 key vector를 dot product했을 때 각 element의 곱이 N(0, 1)이라면, $d_k$ 차원일 경우 분산은 $d_k$가 된다.
분산이 커진다는 것은 softmax 내 특정 값이 유난히 커질 가능성이 증가하는 것이며, 한 값에 유난히 편중되어 나머지의 gradient가 매우 작아질 수도 있다.
이에 대한 해결법으로 분산 값을 줄이기 위해 $\sqrt{d_k}$ 로 나눠 scaled 한다.
- $d_k$: Key vector의 차원(dimension)
Multi-Head Attention
Attention으로 다른 단어와의 관계를 고려한 풍부한 표현이 가능해졌다. 그렇지만 더 많은 관계에 대해 동시에 표현하고 싶기 때문에 Multi-Head Attention이 등장했다.
Scaled Dot-Product Attention 하나를 하나의 head로 삼고 병렬적으로 h개의 attention을 각각 계산한다.
그 후, 각 token들에 대해 head들의 attention 출력을 concat하여 원하는 최종 dimension에 맞게 선형 변환한다. 이로써 입력과 출력 형태는 동일하지만, Multi-head 구조를 통해 더 풍부한 표현의 출력을 만들 수 있다.
Encoder
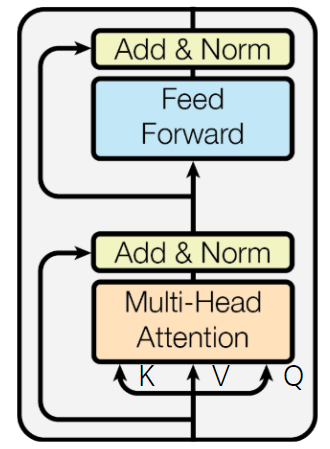
Transformer의 Encoder의 핵심 Multi-Head Self Attention을 알아봤다. 이 출력은 입력으로 들어왔던 sequence 데이터들의 shape과 동일하여 Residual 구조를 통해 Skip connection(Add)를 적용하고 Layer Normalization을 수행한다.
이에 대한 출력은 다시 2개 layer의 MLP를 통과하고 Add 및 Layer Norm을 수행하여 하나의 Encoder 블럭을 완료할 수 있다.
Layer Normalization
Layer Normalization을 설명하기 전에 앞서 알고 있는 Batch Normalization(BN)을 설명하고 차이를 비교하겠다.
BN은 동시에 학습하는 Batch data들에 대해 normalization이 일어난다. 정확히는 각 node 혹은 채널들에 대해 feature vector들을 전부 합한 통계량으로 normalization이 이루어진다.
반면, Layer Normalization은 Batch를 고려하지 않고 개별적인 data들 각각에서 layer(모든 채널의 feature vector)를 normalization한다.
transformer 구조에서는 layer 단위가 각 sequence들의 output feature vector 단위이다.
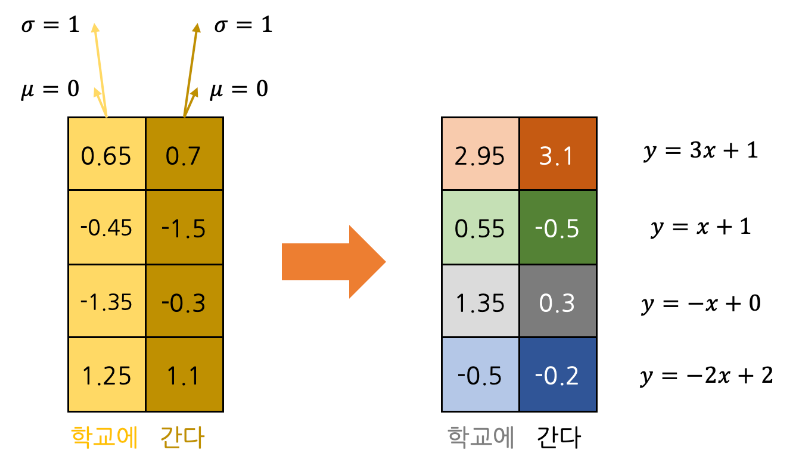
그렇게 normalization을 한 이후 batch norm 처럼 $\gamma, \beta$를 개별적으로 적용한다.
Positional Encoding
Transformer 구조는 순서를 바꾸어도 똑같은 출력이 나오기 때문에 순서 정보를 encoding에 추가해서 전달해줄 필요가 있다.
이때 Sinusoidal function을 활용한다.
Decoder
Masked Multi-Head Attention이 사용되며 2번째 Attenion block에서는 Key와 Value로써 Encoder의 출력을 사용한다.
decoder의 input은 <SOS>에서 부터 시작되어 다음 단어;token을 예측하고, 예측 결과가 output에 이어 붙어 다시 decoder를 거쳐 또 다시 다음 단어를 예측하는 식으로 동작한다.
즉, output으로 들어온 input들에 대해 각각 다음 단어를 vocabulary 내에서 softmax를 통해 예측하여 task를 수행하게 된다.
predict 때는 현재까지 생성된 내용으로 decoder를 거치고 마지막 token의 출력을 다음 단어로 사용하여 다시 decoder를 거치는 식으로 auto-regressive하게 동작한다.
그리고 train 단계에서는 Masked Multi-Head Attention을 사용해 각 token이 자신 이전 sequence만을 볼 수 있도록 masking을 하여 각 token이 다음 단어를 예측하게 하고 이를 backprop하여 학습하게 된다.
Masked Multi-Head Attention
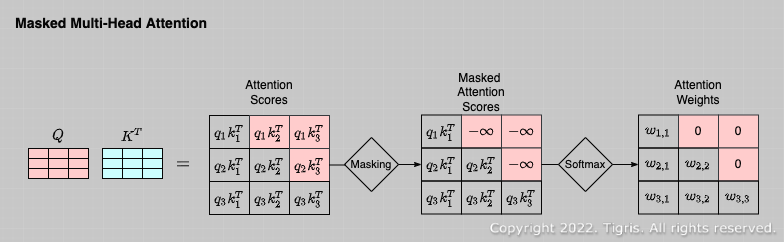
위 사진과 같은 구조로 각 token의 query에 대해 이후 시간대에 등장하는 token의 key와의 유사도를 $-\infin$ 으로 변환하여 softmax에서 결과를 0으로 만든다.
BERT(Biderectional Encoder Representations from Transformer)
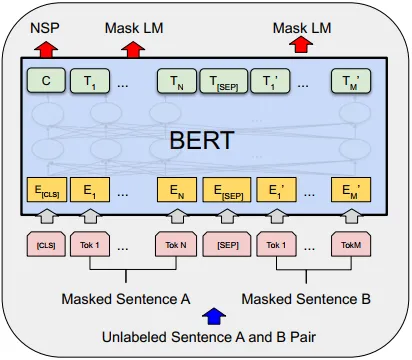
Transformer의 Encoder만을 사용해 self-supervised learning으로 대량의 데이터를 pretrained 한 모델이다.
Input Embedding
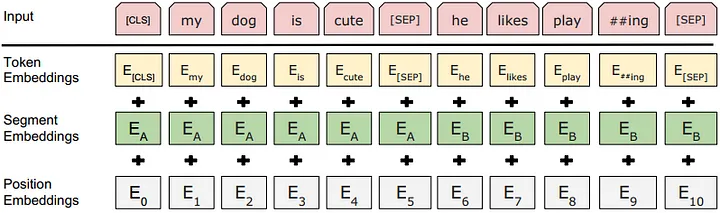
bert는 Trainable한 Position embedding과 함께 두개의 문장을 구분하는 Segment embedding을 추가하여 입력을 encoding한다.
token은
WordPiece embedding을 사용하여 embedding 되었다.
MLM(Masked Language Model)
Bert에는 special token으로 [Mask]를 가지고 있다. 입력 데이터의 일부(15%)에 대해 MLM을 적용하여 해당 위치의 실제 단어를 예측하는 것을 학습한다.
15%의 Token은 아래와 같이 처리된다.
- 80%:
[Mask] - 10%: 다른 무작위 Token
Transfer learning시에는[Mask]Token이 없기 때문에 일반화하기 위해 필요하다.
- 10%: 원래의 Token 그대로 사용
- 다른 무작위 token만 존재한다면 입력 토큰은 무조건 틀렸다고 판단이 가능하기 때문에, 안 틀렸을 가능성도 부여하였다.
이렇게 MLM Task를 수행할 토큰의 BERT를 거친 embedding 표현을 MLM Fully-Connected layer를 거쳐 softmax로 단어를 예측한다.
NSP(Next Sentence Prediction)
Bert는 2가지의 문장을 받는다. NSP는 문맥을 파악하여 두 문장이 연속되는지 아닌지 판단한다.
이를 위해 각 문장을 구분하는(시작과 끝에도 존재) [SEP] 토큰이 존재하며, 특정 token에 편향되지 않은 전체 문맥을 파악할 수 있는 [CLS] 토큰을 맨 앞에 두어 최종 [CLS] 토큰의 임베딩 값을 사용해 분류 task를 수행한다.
Transfer learning
BERT 모델을 학습하기 위해 사용했던 MLM, NSP layer를 버리고 BERT를 embedding 모델로 사용한다.
앞서 말했듯이 self-supervised learning을 사용하여 BERT 모델을 충분히 학습할 수 있으므로 다른 Task에 일반적으로 사용할 수 있을 풍부한 표현의 모델을 만들 수 있다.
- Sentence Classification
- 주어진 한 문장에 대해 분류
[CLS]에 layer를 붙여 학습- 예시
- SST-2(Staford Sentiment Tree bank)
- CoLA(Corpus of Linguistic Acceptability)
- Sentence Pair Classification
- 두 문장의 관계를 예측
- 문장 구분을 위해
[SEP]을 사용하고[CLS]에 layer를 붙여 학습 - 예시
- MNLI(Multi-Genre Natural Language Inference)
- 전제-가설 쌍이 존재하며 관계를 예측
- 함의;
entailment, 모순;contradiction, 관련없음;neutral
- QQP(Quora Question Pairs)
- STS-B(Semantic Textual Similarity)
- MNLI(Multi-Genre Natural Language Inference)
- Sentence Tagging
- 문장 내의 모든 token에 대해 token 단위로 속성을 예측
- 각 token에 동일한 classification layer를 붙여 개별적으로 예측
- 예시
- CoNLL-2003(Named Entity Recoginiton Task) 대명사 분류
- Machine Reading Comprehension
- 주어진 질문에 대해
paragragh에서 정답을 찾아냄 - 시작 단어와 끝 단어를 각각 찾아낸다.
- 두번째 문장(
paragragh)의 각 토큰 별로 하나의 scalar 값으로 변경 후 softmax를 취하는 것을 두번 반복 - 하나는 시작단어, 하나는 끝 단어를 예측하는 것으로 하여 정답을 찾는다.
- 예시
- SQuAD(Stanford Question Answering Dataset)
- 주어진 질문에 대해
GLUE(General Language Understanding Evaluation) Benchmark
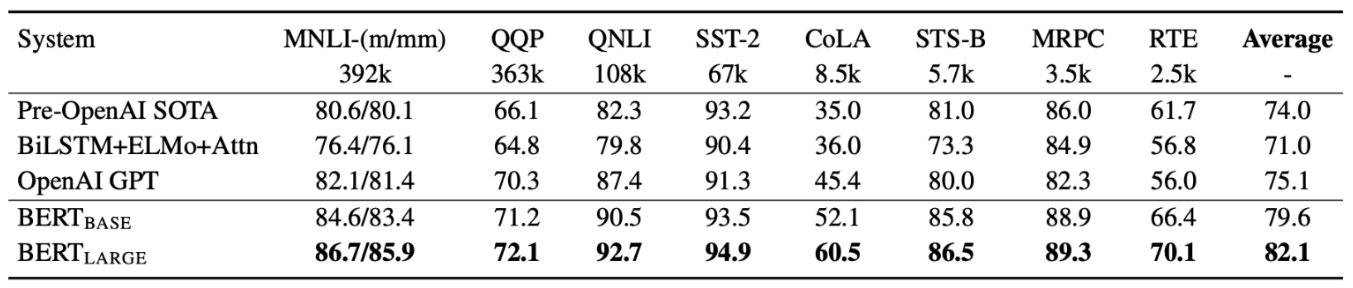
위와 같은 여러 task에 대한 dataset을 가지고 각 task의 점수들을 구해 언어모델의 성능을 파악하는 지표이다.
BERT의 처음 나왔을 당시 GLUE score에서 높은 점수를 기록하였다.
Decoding for Generation
학습 과정이 아니라 실제 predict(generate)를 수행할 때 어떤 식으로 생성해야할까?
가장 간단하게는 한 단어씩 가장 높은 확률의 단어를 생성해나가는 Greedy 방식이다. 하지만 Greedy는 최적해를 보장하지 못하기 때문에 Beam Search 같은 기법이 제시되었다.
하지만 beam search도 만능이 아니다.
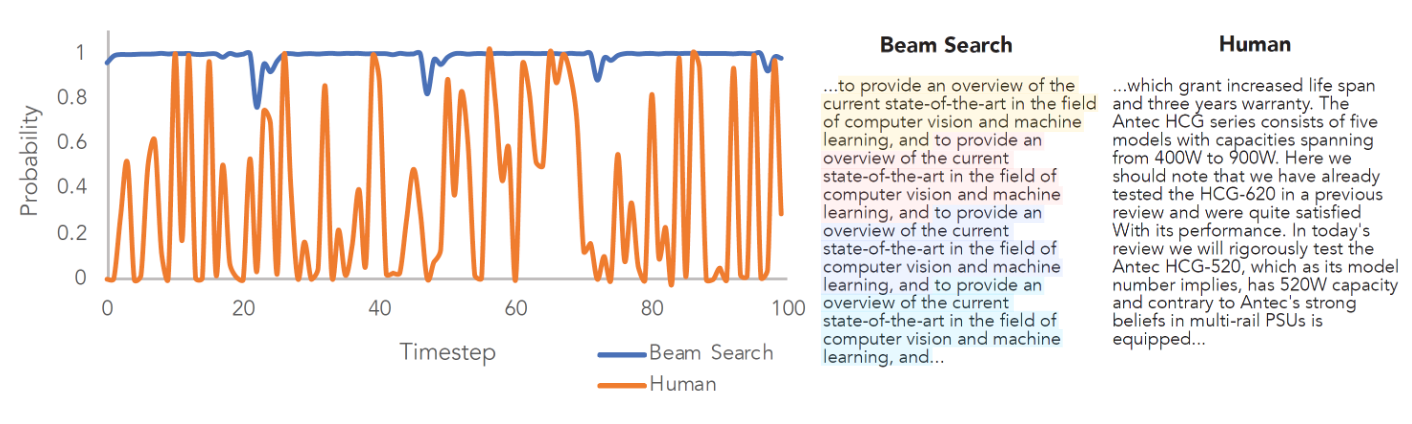
반복에 취약하며 가끔씩 흔치 않은 단어를 사용하기도 한다.
Sampling
이에 따라 또다른 방법으로 Sampling이 있다. softmax로 나온 각 단어의 확률 분포에서 Ramdom sampling을 수행하여 다음 단어를 도출한다.
그리고 평범한 Sampling을 보완하여 고도화하는 방법들이 존재한다.
- Temperature
- $\frac{\exp(z/\tau)}{\sum_i \exp(z_i/\tau)}$
- 최종 확률 분포를 만들기 위한
softmax에tau를 추가한다. - $\tau > 1$: 확률 분포를 평탄화하여 다양성 증가
- $\tau < 1$: 확률 분포를 뾰족하게 하여 정확성 증가
- Top-k
- 상위 k개의 확률 값에 대한 단어들 중에서 선택한다.
- 이 방법은 분포에 따라 적당한 확률의 단어도 무시될 수 있다.
- Top-p
- 생성 확률 합이 p가 될때까지 후보 단어를 선정하여 sampling
top-k의 단점을 보완한다.
댓글남기기