
[Level 2]Machine Reading Comprehension
이번주는 새로운 프로젝트 기계독해를 진행하기에 앞서 관련된 강의를 학습하였습니다. 시간이 나면 첫번째 프로젝트에 대한 회고도 작성하고 싶은데 가능할지 모르겠네요.
MRC
기계 독해란 주어진 지문(Context)를 이해하고, 주어진 질의 (Query/Question)의 답변을 추론하는 문제이다.
- Extractive Answer Datasets
- 지문에 정확히 포함된 정답
span을 탐색
- 지문에 정확히 포함된 정답
- Descriptive/Narrative Answer Datasets
- 단순히 추출한
span이 아닌 free form의 sentence 응답
- 단순히 추출한
- Multiple-choice Datasets
- 다지선다의 형태로 정답을 고르는 형태
- 요즘은 잘 안함
Challenges in MRC
- Understand same meaning sentence
- 단어들의 구성이 유사하지 않더라도 동일한 의미임을 이해해야함
- Unaswerable questions
- 지문에 정답이 없어 대답할 수 없는 경우
No Answer이 필요함
- 지문에 정답이 없어 대답할 수 없는 경우
- Multi-hop reasoning
- 여러개의 documnet에서 연역적으로 정답을 찾아낼 수 있어야함
Metrics
- Exact Match / Accuracy
- 정답이 정확히 일치하는 비율
- F1 Score
- 정답과 예측의 token overlap을 기준으로 F1을 계산
- 데이터 하나씩 F1을 구하여 합침
- ROUGE-L / BLEU
- n-gram 기반
Extraction-based MRC
문서 내에 존재하는 답변을 정확하게 그대로 찾아내는 문제이다. 이 경우 Exact Match(EM)과 F1 score를 주요 지표로 사용하게 된다.
word piece와 같은 BPE로 tokenizing을 수행한다. 그리고 [SEP] 토큰으로 구별하여 encoder 모델에 넣고 정답의 시작과 끝 위치를 예측하도록 학습한다.
즉, Token Classification 문제로 치환될 수 있다.
이 경우 Post-Processing이 필요할 수 있다.
- 불가능한 답 제거
- End position이 start 앞에 있는 경우
- 예측한 위치가 context 위치가 아닌경우
- max_answer_length 보다 길이가 긴 경우
- 최적 답안 찾기
- Start/end 예측 조합에서 score가 높은 N개 탐색
- 불가능한 조합 제거
- score가 가장 큰 조합 최종 예측으로 선정
Generation-based MRC
Decoder 모델을 사용하여 Auto Regressive하게 답변을 생성한다.
BART(Bidirectional Auto-Regressive Transformer)
BERT + GPT 구조로 encoder와 decoder를 둘 다 가지고 있는 모델이다.
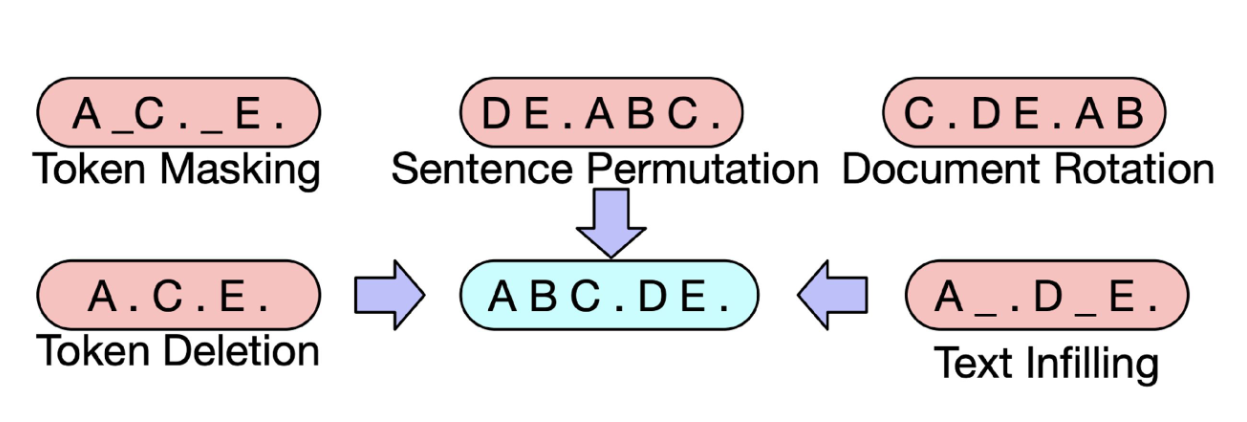
bart는 위와 같은 방식으로 학습을 진행할 수 있다.
T5(Text-to-Text Transfer Transformer)
모든 텍스트 처리 문제를 text-to-text 로 취급하여 학습을 진행한다.
Input: "translate English to German: That is good"
Output: "Das ist gut"
위와 같은 방식으로 prefix를 붙여 task를 주며, 적절한 대답을 생성하도록 학습하였다.
요즘에는 GPT로 인해 당연한 방식이지만, 당시에는 최초의 접근이였다.
Passage Retrieval
질문(query)에 맞는 적절한 문서(passage)를 찾는 것을 의미한다. 각각을 임베딩하고 MIPS(maximum inner product search)으로 최대가 되는 문서를 찾는다.
Sparse Embedding
먼저 단순하게 질문의 단어들을 기반으로 embedding을 할 수 있다. 큰 사이즈의 vocab에서 출현한 단어 일부만 값을 가지니 sparse한 벡터가 만들어지기에 sparse Embedding이라고 부른다.
TF-IDF
Term Frequency - Inverse Document Frequency의 약자이다.
문장에서 자주 나오는 단어들(TF)을 기반으로 embedding을 형성하되, 전체 문서들에 대해 자주 나오는 a, the 같은 것들은 패널티를 적용(IDF)하여 sparse embedding을 구성한다.
- $\text{TF}(t, d)$: 특정 문서 $d$에서 단어 $t$의 출현 빈도 (Term Frequency)
- $\text{IDF}(t, D)$: 단어 $t$가 전체 문서 집합 $D$에서 얼마나 드물게 나타나는지를 나타내는 역문서 빈도 (Inverse Document Frequency)
- $N$: 전체 문서의 수
-
$ {d \in D : t \in d} $: 단어 $t$가 포함된 문서의 수
BM25
TF-IDF의 개념을 바탕으로 문서의 길이까지 고려하여 점수를 매긴다.
TF 값에 한계를 지정하여 일정 범위를 유지하도록 하며, 길이가 더 작은 문서에 가중치를 부여한다. 실제 검색엔진, 추천 시스템 등에 아직까지 많이 사용되는 알고리즘이다.
\[\text{BM25}(q, d) = \sum_{i=1}^{n} \text{IDF}(q_i) \cdot \frac{\text{TF}(q_i, d) \cdot (k_1 + 1)}{\text{TF}(q_i, d) + k_1 \cdot \left(1 - b + b \cdot \frac{|d|}{\text{avgdl}}\right)}\]- $q$: 질의 (query)
- $d$: 문서 (document)
- $q_i$: 질의의 $i$번째 단어
- $\text{TF}(q_i, d)$: 문서 $d$에서 단어 $q_i$의 출현 빈도
- $\text{IDF}(q_i)$: 단어 $q_i$의 역문서 빈도
-
$ d $: 문서 $d$의 길이 (단어 수) - $\text{avgdl}$: 전체 문서의 평균 길이
- $k_1$: TF scaling factor (일반적으로 1.2 또는 2.0)
- $b$: 문서 길이 보정 인자 (일반적으로 0.75)
Dense Embedding
Sparse에 비해 훨씬 작은 벡터 차원(50 ~ 1000), 대부분이 요소가 non-zero이다.
- 단어의 유사성 또는 맥락을 파악하는 성능이 뛰어남
- 학습을 통해 임베딩을 만들며 추가적인 학습 또한 가능하다.
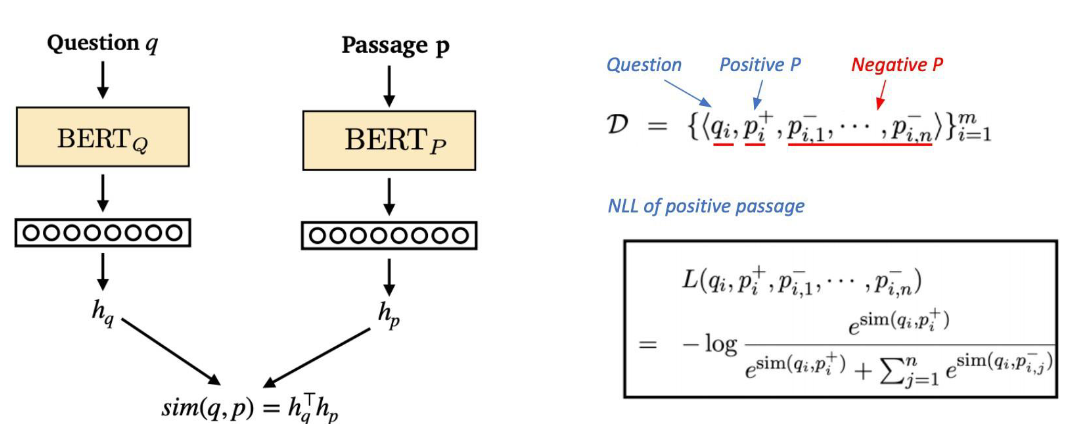
단일 모델로 문서와 질문을 임베딩하는 방법을 주로 많이 사용하기도 하지만,
강의에서는 DPR 방식을 소개하며 별개의 파라미터를 갖는 모델을 학습하는 법을 제시함
Negative Sampling
각각의 query-positive 쌍 데이터에 대해 negative documents를 추가한다.
그렇게 query에 대한 positive/ negatives들의 dot-product 값을 계산하고 positive를 최대화 할 수 있게 cross entropy로 positive를 분류해내는 문제로 학습한다.
In-batch Negative
in-batch 방식은 별도의 negative documents를 sampling하지 않는다. 대신, 같은 batch 내의 다른 데이터들의 문서를 negative로 삼고 분류하게 된다.
# (batch_size, emb_dim)
p_outputs = p_encoder(**p_inputs)
# (batch_size, emb_dim)
q_outputs = q_encoder(**q_inputs)
# Calculate similarity score & loss
# (batch_size, batch_size)
sim_scores = q_outputs @ p_outputs.T
targets = torch.arange(batch_size).long().to(args.device)
loss = F.cross_entropy(sim_scores, targets)
Faiss
Faiss는 벡터 유사도 검색을 가속화 하고 쉽게 할 수 있도록 해주는 vector db 엔진이다.
문서가 수억, 수조개 존재할 때, 모든 문서에 대해 비교하면 속도가 매우 느리고 연산자원도 많이 필요할 것이다. 이를 위해 생각해볼 수 있는 것이, clustering, quantization 등이 존재한다. Faiss는 자체적으로 이 방식들을 구현해놓아 쉽게 사용할 수 있다.
- Compression
- SQ(Scalar Quantization)
- PQ(Product Quantization)
- Pruning
- IVF(Inverted File): 클러스터링
또한, GPU 지원도 되기 때문에 빠른 검색이 가능하다!
Bias
- Bias in learning
- Inductive Bias: 학습 할 때 의도적으로 편향을 줌
- A Bias World
- Historical Bias: 현실 세계가 이미 편향되어 있어 원치 않는 속성이 학습
- Co-occurence Bias: 성별-직업 관계등 표면적인 상관관계로 원치 않는 속성이 학습
- Bias in Data Generation
- Specification Bias: 입력-출력 정의 방식에 따라 생기는 편향
- Sampling Bias: sampling 방식에 따라 생기는 편향
- Annotator Bias: 데이터 작업자의 특성에 따라 생기는 편향
이러한 특성은 ODQA에서도 볼 수 있는데 평가 데이터셋들에 주목할 수 있다.
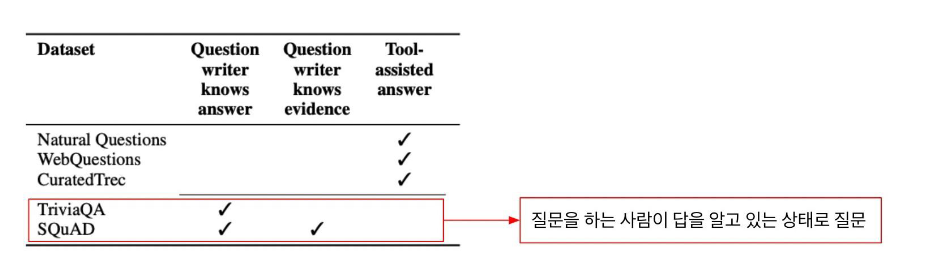
질문을 생성하는 annotator가 정답을 알고 있거나 문서(evidence)를 보고 만든다면 정답에 편향되게 질문을 생성하게 된다.
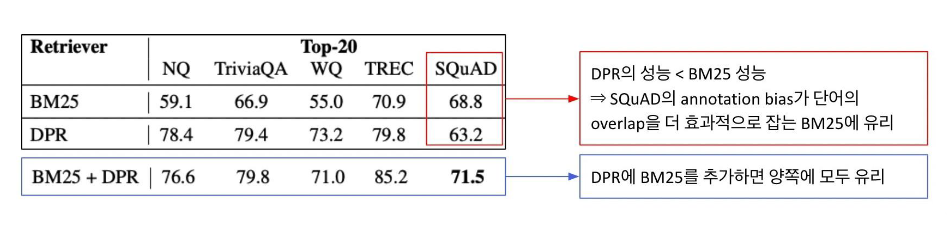
따라서 SQuAD의 경우 context 내부의 단어 위주로 질문이 생성될 가능성이 높고 자연스럽게 BM25의 성능이 높다.
이는 실제상황과 맞지 않다.
Closed-book Question Answering
LLM은 방대한 데이터를 기반으로 사전 학습을 하였다. 따라서 이미 Open Domain들에 대한 지식을 가지고 있을 것이기 때문에 Closed-book으로 질의응답을 수행할 수 있다.
In-context Learning
역전파를 통한 파라미터 업데이트 없이, 순전파만을 통해 이루어지는 학습이다.
Translate Englist to French:
sea otter => loutre de mer
peppermint => menthe poivree
plush girafe => girafe peluche
cheese =>
즉, few shot learning을 말한다. Task에 대한 insturction과 몇 개의 예제들을 넘겨 다양한 형태의 output을 원하는 대로 얻을 수 있다.
LLM이 이를 수행할 수 있는 이유는 다음과 같은 특성을 가지고 있기 때문이다.
- Generalization and Reasoning
- Factual Knowledge
Phrase Retrieval in ODQA
위에서 제시한 방법들은 Retrieval -> Reader 구조의 파이프라인을 가지고 있다. 이를 한번에 처리할 수 없을까? 이에 대한 접근으로 Phrase Retireval이 있다. 처음부터 질문에 대한 답을 임베딩해두는 것이다.

documents를 참고하여 phrase를 직접 embedding한다!
DenSPI(2019)
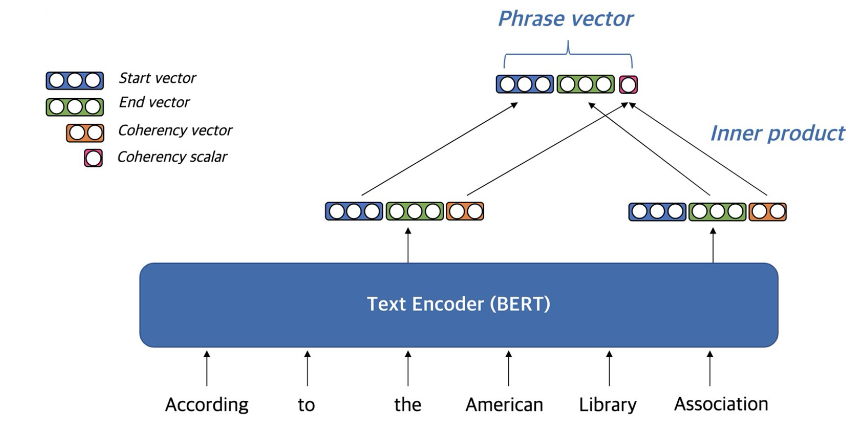
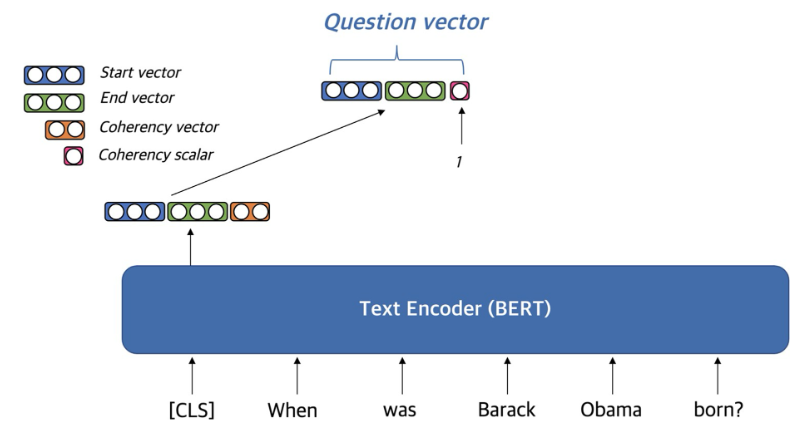
- 이외에도 Phrase에 대한 문서의 Sparse vector 만들어 함께 활용한다.
- FAISS로 dense vector에 대한 search 이후 sparse로 reranking
DensePhrases(2021)
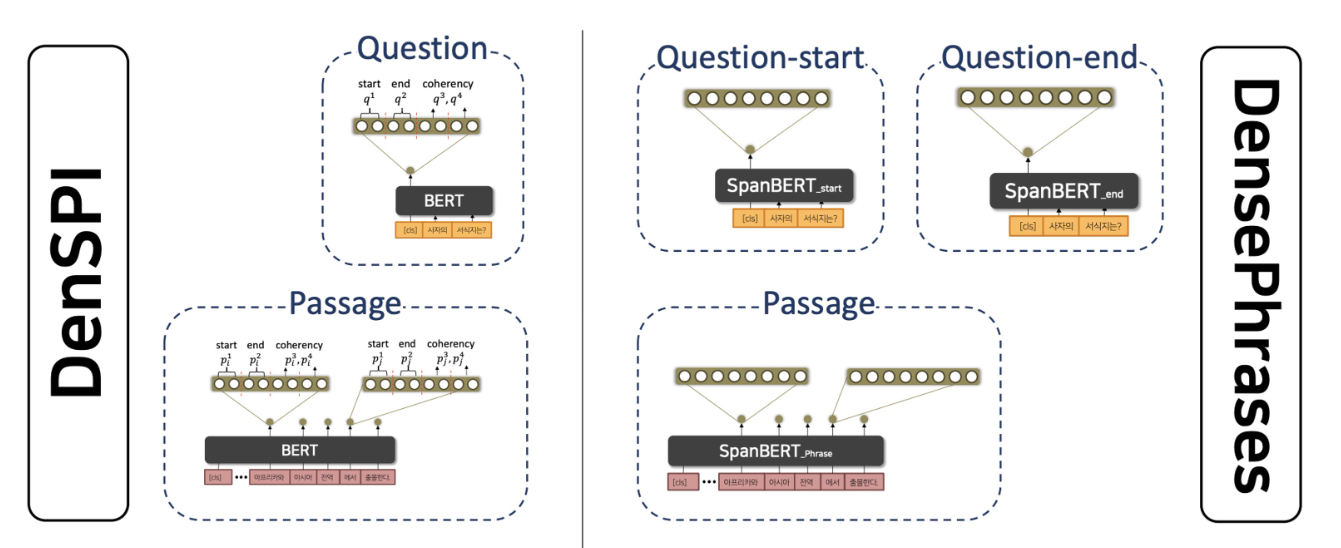
- DenSPI와 다르게 sparse Embedding이 필요없어 졌다.
- dpr보다 성능이 높아졌다고 한다.
댓글남기기