
[Week 3]EDA & DataViz
이번 주는 데이터 분석과 함께 데이터 시각화를 배웠습니다.
카테고리형 데이터
텍스트로 구분되는 데이터(국가/혈액형/과일/성별 등)
모델이 학습하기 위해 인코딩이 필요하다.
- Label encoding
- 각 label에 값을 부여해서 처리
- 하지만 순서가 생기며 불필요한 수리 관계가 발생함
- One-hot encoding
- 각 label을 하나의 컬럼으로 변경하여 각 label인지(1) 아닌지(0) 값을 할당
- 더 나은 표기지만 카테고리의 종류가 많아지면 차원이 너무나도 커질 수 있다.
- Binary encoding
- 레이블링을 이진수로 변환하여 encoding
- 순서 정보를 없앨 수 있으며 차원 개수를 줄일 수 있지만, 범주 의미가 거의 사라짐
- Embedding / Hashing
- word embedding 같이 의미나 통계값을 활용해 적절한 값으로 변경
순환형 데이터
순서가 존재하는 경우 label encoding 등을 사용해도 좋지만, 순환형의 경우 까다롭다. (e.g.) 요일, 각도
이 경우 삼각함수 등 크기에 따라 순환되는 값을 활용하면 좋다.
NeRF에서는 각도 값의 표현력을 넓히기 위해 한 값을 sin, cos 값으로 치환해서 사용한다.
Skewness
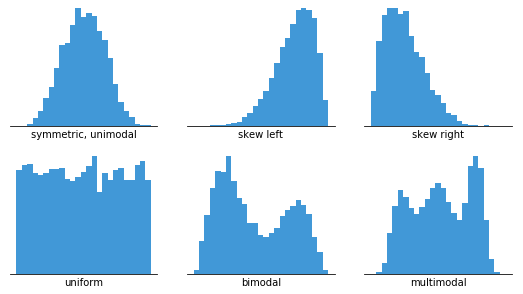
데이터의 분포는 skew되어있을 수도 있고, 혹은 여러 분포가 하나에 합쳐진 모양인 multimodal형식이 될 수도 있다.
Negative Skewness
왼쪽으로 꼬리가 긴 경우, 큰 값이 서로 큰 차이가 나게 하기 위해 지수를 적용한다.
- Square/Power Transformation
- Exponential Transformation
Positive Skewness
오른쪽으로 꼬리가 긴 경우, 작은 값이 서로 큰 차이가 나게 하기 위해 로그, 제곱근 등을 적용한다.
- Square-root Transformation
- Log Transformation
Box-Cox Transformation라는 범용적인 log 기반 방법이 존재한다.
Transformation 들을 적용하기 위해서는 부호를 주의해야하므로 표준화 등 전처리 이후 변형을 적용해야한다.
결측치(Missing Value)
- 결측치가 과반수 이상
- 결측치 유뮤만 사용
- 해당 열 삭제
- 결측치가 5% 이상
- 결측치에 대한 분석
- 결측치를 채울 대푯값 전략
- 결측치가 매우 적은 경우
- 해당 행을 그냥 무시하는 것도 고려 가능
missingno 같은 라이브러리로 결측치 분포 확인 가능
이상치(Outlier)
- IQR(Inter Quantile Range)
- 3분위수와 1분위수의 차이를 의미함
1분위 수 - 1.5 * IQR 이하 / 3분위수 - 1.5 * 이상을 outlier로 판단
- DBSCAN
- Density-Based Spatial Clusering of Applications with Noise
- 밀도 기반 클러스터링
- 클러스터링 되지 않은 값들을 outlier로 간주할 수도 있다.
- Isolated Forest
- Decision Tree와 같이 동작
- 루트 노드와 거리를 통해 이상치 탐지(거리 정규화 필수)
- 이상치가 많으면 효과적이지 않음
Clustering
유사한 성격을 가진 데이터를 그룹으로 분류한다.
- K-Mean
- K개로 그룹화하여,각 클러스터의 중심점을 기준으로 데이터 분리
- DBSCAN
- 밀도 기반 클러스터링
- HierarchicalClustering
- 수치를 동적으로 조정하며 클러스터링을 수행
HDBSCAN등이 존재
- GMM
- 가우시안 분포가 혼합된 것으로 모델링
차원축소
기존 특성 중 일부를 선택하거나(Feature Selection), 기존 특성을 합쳐 새로운 특성을 만들 수 있다(Feature Extraction).
- PCA
- 데이터의 공분산을 계산하여 고유 벡터를 찾아 투영
- t-SNE
- 데이터 포인트 간 유사성 모델링하여,저차원 공간에서 재현
- UMAP
- 위상 구조의 정보를 최대화하여 저차원 공간에 재현
- LDA
- 클래스 간 분산을 최대화하고,클래스 내 분산을 최소화하는 방식
- Isomap
- 고차원에서 최단 경로 거리에 대한 정보를 저장
- Autoencoder
- 인코더/디코더 구조로 원본 데이터를 압축하였다가 복원하는 신경망을 구성하여 학습
- 학습된 신경망에서 인코더만을 사용하여 차원 축소 가능
Autoencoder가 성능이 좋지만, 학습이 필요하며 시간이 오래 걸리는 단점이 존재한다.
간편하게 사용가능한
t-SNE,UMAP이 가볍게 많이 사용된다.학습을 위해 차원축소를 적용할 때는 보통 100개의 feature vector로 만든다.(어느 정도 PCA나 t-SNE 등으로 줄인다음 100 size로 Autoencoder를 적용하는 2step도 가능하다.)
시계열 데이터
추세, 계절성, 주기, 노이즈의 성분 분석을 통해 시계열을 분석한다.
- Additive Model: 추세+계절성+주기 + 노이즈
-
Multiplicative Model: 추세*계절성*주기 + 노이즈
- 추세(trend)
- 장기적인 증가 또는 감소
- 계절성(seasonality)
- 특정 요일/계절에 따라 영향
- 주기(cycle)
- 형태적으로 유사하게 나타나는 패턴
- 계절성과 다르게 고정된 빈도가 아님
- 노이즈(noise)
- 왜곡된 값
정상성과 비정상성
시간에 따라 통계적 특성이 변하기 때문에 관측 시간에 따라 결과가 다를 수 있음
- 정상성: 시간에 따라 통계적 특성이 변하지 않는 것
- 비정상성: 시간에 따라 통계적 특성이 변하는 것
따라서 통계 모델에서 사용하기 위해 비정상적을 제거할 필요가 존재한다.
- 차분(Differencing)
- 이웃된 두 값의 차이를 사용
trend를 제거하고 패턴을 확인 할 수 있다.- 경우에 따라 2차 차분을 적용하기도 한다.(차분 값에 차분 적용)
- 평활(Smoothing)
- 지수 이동 평균(
EMA) 등을 사용해noise를 제거한다.
- 지수 이동 평균(
이미지 데이터
이미지 데이터에서 주요하게 분석해야 하는 것은 Domain(어떤 분야에 관련된 것인지), Task(수행할 목표가 뭔지), Quality(이미지 데이터셋이 적절히 선택되었는지)이다.
image data EDA
- Target 중심
- 정형적인 분석
- 이미지 분포가 고르게 되었는지
- 각 범주의 이미지가 고르게 존재하는지
- 색, 밝기 등 편향된 데이터만 존재하지는 않는지
- Input 중심
- input 데이터 이미지가 이상한 건 없는지
- 이미지를 직접 보며 분석
- Process 중심
- 전처리-모델-결과해석 등을 반복하며 분석
텍스트 데이터
텍스트 데이터는 언어에 따라 구조가 다르며, 문법에 다양한 규칙(다양한 예외)이 존재하고, 데이터에 오타가 있는 경우가 많으며, 신조어/방언 뿐만 아니라 시기적/사회적에 따라 의미가 달라질 수가 있다. 또한 수집한 데이터에 개인정보들이 포함되어 있을 수 있으므로 데이터 처리가 매우 까다롭다.
텍스트 데이터 전처리
- 짧은 단어 또는 표현에 대한 전처리
- 텍스트 패턴(정규표현식)
- 텍스트 토큰화
- 소문자 변환(영어등)
- 불용어 제거
- 철자 교정
- 어간추출(stemming)
beginning => begin
- 표제어추출(lemmatization)
are,is => be
- 문단 등에 대한 전처리
- 문장 토큰화
- 띄어쓰기 교정
- 문장구조 분석
- 문맥적 의미분석
HCI(Human-Computer Interaction)
개인과 디지털 기기/디지털 시스템 간의 상호작용을 연구하는 분야이다.
- 유용성(Usefulness)
- 기술적으로 뛰어나서 쓸모가 있어야함
- 사용성(Usability)
- 개발자만 사용할 수 있는 게 아닌, 일반 사용자도 쉽게 사용가능해야함
- 감성(Affect)
- 사용하는 과정에서 적절한 느낌을 받을 수 있어야함
HCI의 목표는 사용자에서 최적의 경험을 제공하는 것
Schneiderman’s Mantra
효과적인 데이터 탐색 및 분석을 위해 제안한 3단계 접근 방식
- Overview first
- 사용자가 데이터의 전체적인 개요를 먼저 볼 수 있어야함
- Zoom and filter
- 사용자가 관심 있는 부분을 확대
- 불필요한 정보를 필터링
- 다양한 필터링 방식 제시 필요
- Details-on-demand
- 사용자가 언제든지 특정 데이터에 대한 세부 정보를 요청할 수 있어야함
이러한 원칙을 명심하고 dashboard를 만들자
게슈탈트 이론
인간의 인지는 개별 요소들의 합이 아닌 전체적 구조에 기반한다는 이론
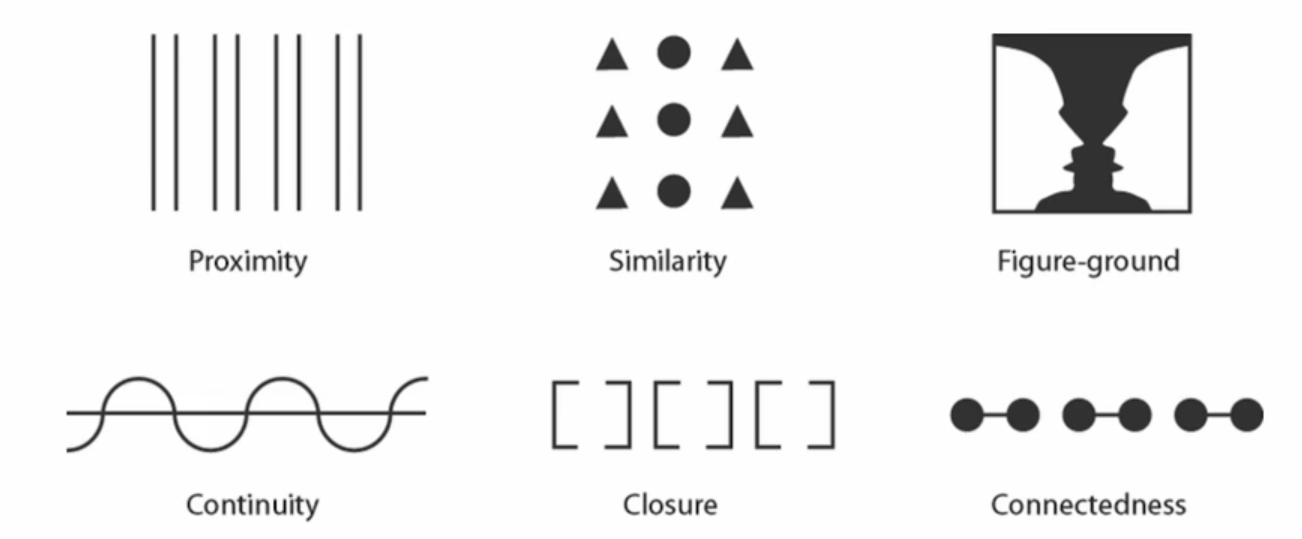
- 근접성의 원리
- 유사성의 원리
- 연속성의 원리
- 폐쇄성의 원리
- 그림-배경 분리
이러한 이론에 입각해서 원하는 부분에 주목하도록 만들 수 있다.
인지편향
- 확증편향(Confirmation Bias)
- 자신의 믿음을 뒷받침하는 정보만을 수집하는 경향
- 가용성 휴리스틱(Availability Heuristic)
- 자신의 경험이나 쉽게 떠올릴 수 있는 정보에 의존해서 판단하는 경향
- 앵커링(Achoring)
- 최초에 제시된 정보(앵커)에 계속해서 의존하고 판단하는 경향
- 프레임 효과(Framing Effect)
- 상황의 제시 방식에 따라 다른 결정을 내리는 경향
댓글남기기