
[Week 6]AI 개발 기초
이번 주부터는 다음주 추석을 끼워서 총 3주(학습 기간 2주) 간 문장 유사도 측정 프로젝트를 진행하게 되었습니다. 해당 기간의 강의로 먼저 AI 개발 기초를 수강하였습니다.
AI 엔지니어링의 사례
우버 택시
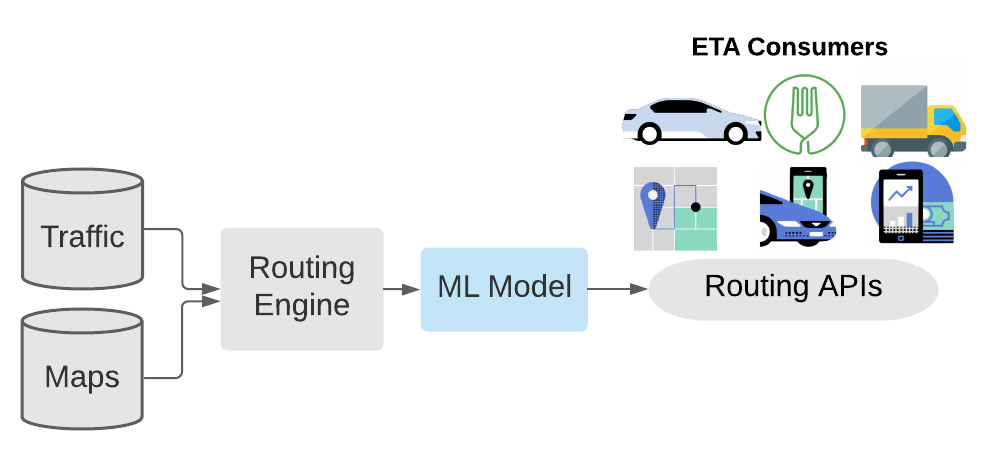
우버는 시간대별로 지역별 수요 예측을 진행하여 운전자를 수요가 많은 지역으로 이동시킴으로써 수요/공급 균형을 맞춘다.
도착 예정 시간(ETA; Estimated Time of Arrival)을 Tabular 데이터에 Transformer를 적용하여 해결하였다.
DeepETA: How Uber Predicts Arrival Times Using Deep Learning
도어대시
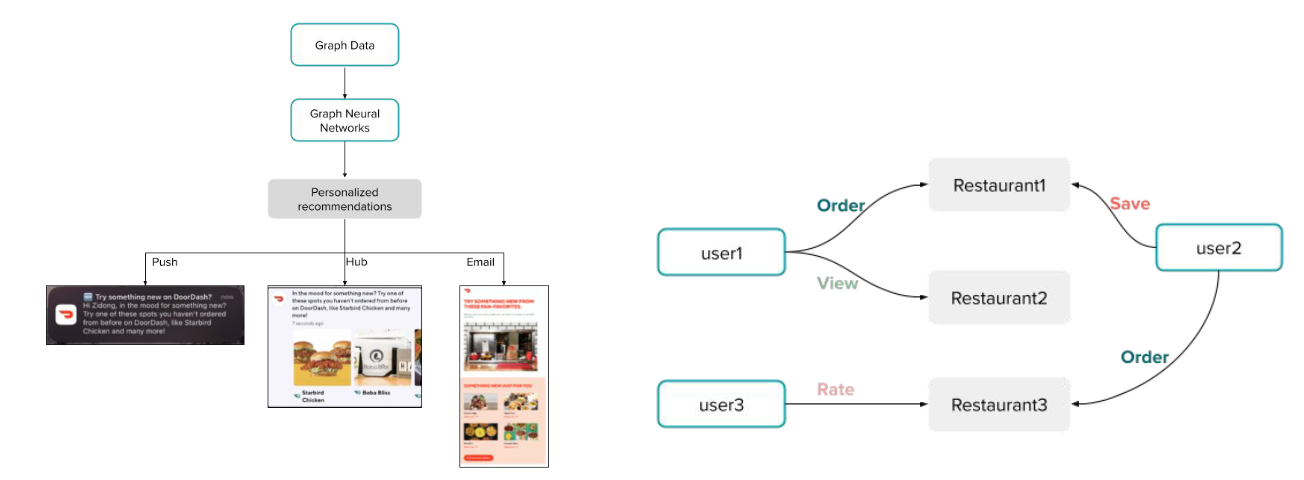
개인화 추천 서비스에 graph 알고리즘을 적용하였다.
Beyond the Click: Elevating DoorDash’s personalized notification experience with GNN recommendation
듀오링고

Birdbrain이라는 학습자의 맞춤형 난이도를 계산하는 인공지능을 제작하였다.
Linux Shell
사용자가 문자를 입력해 컴퓨터에 명령할 수 있도록 하는 프로그램
- sh: 최초의 쉘
- bash: Linux 표준 쉘
- zsh: Mac 카탈리나 OS 기본 쉘
shell command
$ man # 커맨드의 메뉴얼 확인
$ ls -alh # a: All(숨김파일도 확인)
# l: Long(퍼미션, 용량, 날짜 등 표시)
# h: Human-readable(용량을 GB, MB로 읽기 쉽게 표시)
$ pwd # Print Working Directory
$ sudo # superuser do
$ cat # 파일 내용 출력
$ cat hello.sh > world.sh # 결과를 해당 파일에 Overwrite
$ cat hello.sh >> world.sh # 결과를 해당 파일에 Append
$ history # 최근 입력한 쉘 커맨드 history 출력
# !{history num} 입력 시 해당 커맨드 다시 사용 가능
$ find . -name "File" # 현재 폴더에서 File이란 이름을 가지는 파일/디렉토리 검색
$ alias # 명령어 단축별칭 확인 가능
$ alias ll2='ls -l' # 별칭 지정
$ tree -L 2 # 레벨(깊이)까지의 폴더 구조 tree 출력
$ head -n 3 test.sh # 파일 앞/뒤 n행 출력
$ tail -n 3 test.sh
# 파이프라인을 통해 결과 chaining
# sort로 행 단위 정렬(-r: 내림차순)
# uniq로 중복 제거
# wc -l 로 개수 세기
$ cat fruits.txt | sort | uniq | wc -l
$ grep -i "e$" grep_file # 패턴과 매칭되는 라인 검색
# -i: 대소문자 구분X, -w: 정확히 그 단어
# -v: 특정 패턴 제외 결과
$ cut -d : -f 1,7 cut_file # -d로 delimeter 지정
# -f로 잘라낼 field 지정(첫번째와 7번째)
# 잘라낸 값을 delimeter로 구분해 출력해준다.
$ awk -F: '{print $1}' cut_file # -F로 구분자 지정
# 수행할 동작 지정 가능
# $1은 첫번째 값을 의미
# 표준 스트림
# 0:stdin; 1:stdout; 2:stderr
# 2>&1 stderr를 stdout에 포함해서 출력
# &는 background로 실행한다는 뜻
$ python train.py > log_file 2>&1 &
$ nohup python3 app.py & # nohup으로 하면 해당 백그라운드 프로세스가 터미널 종료 후에도 동작
$ curl -X localhost:5000/ {data} # Clinet URL 웹 서버로 요청 테스트 가능
$ df -h # Disk Free; -h: 읽기 쉽게 표시
SSH(Secure Shell)
vscode로 ssh 연결해서 편하게 원격 조작도 가능하다.
SSH Tunneling
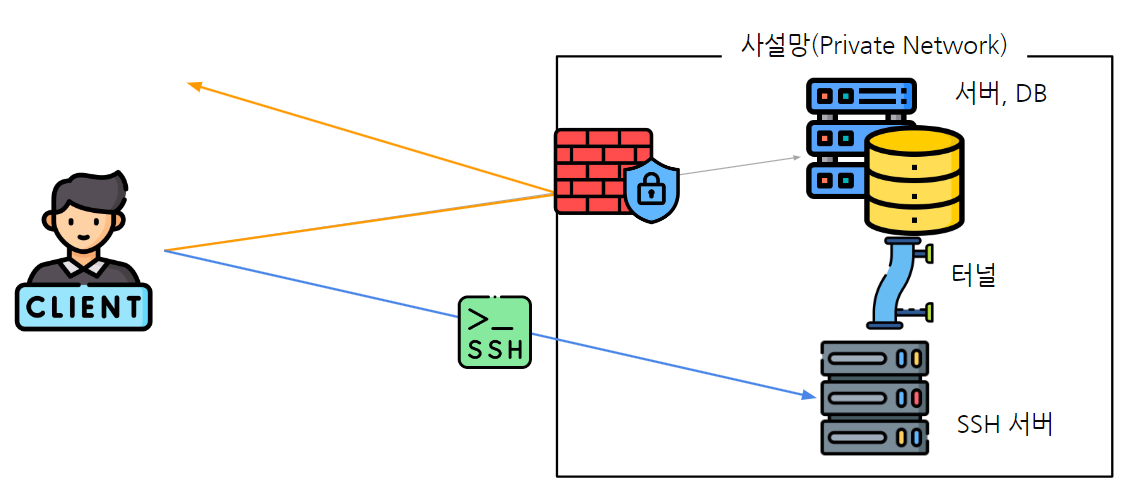
방화벽 등의 이슈로 접근이 제한될때 안전한 터널을 만들고 터널을 통해 우회한다.
$ ssh -L 로컬_포트:원격_호스트:원격_포트 사용자명@SSH_서버
- 명령어를 실행시킨 컴퓨터의 8080 포트가 오픈
- 8080포트로 들어오는 트래픽은 SSH터널을 통해 SSH서버의 30952포트로 전달
- 해당 컴퓨터의 localhost:8080에 접속하면 SSH서버의 30952포트에 연결
Streamlit
Python으로 Server Side하게 빠르게 프로토타입을 제작하여 배포 가능하다.
streamlit 배포예시 https://streamlit.io/gallery
import streamlit as st
import pandas as pd
import pickle
from sklearn.preprocessing import LabelEncoder
import plotly.express as px
import plotly.graph_objects as go
st.set_page_config(page_title="Titanic Survival Predictor", layout="wide")
st.sidebar.title("User Login")
# 개발을 할 때 정말 많이 발생하는 오류는 대부분 오타 때문
# 모델 Load, DB 연결 등을 cache_resource 사용
@st.cache_resource
def load_model():
"""
titanic_rf_model과 scaler를 불러오는 함수
"""
with open('titanic_rf_model.pkl', 'rb') as f:
model = pickle.load(f)
with open('titanic_scaler.pkl', 'rb') as f:
scaler = pickle.load(f)
return model, scaler
# 데이터, API Request의 Response를 저장하고 싶은 경우 사용
@st.cache_data
def load_data():
url = "https://web.stanford.edu/class/archive/cs/cs109/cs109.1166/stuff/titanic.csv"
data = pd.read_csv(url)
data = data.drop(['Name', 'Siblings/Spouses Aboard', 'Parents/Children Aboard'], axis=1)
data['Age'].fillna(data['Age'].median(), inplace=True)
data['Fare'].fillna(data['Fare'].median(), inplace=True)
return data
def prepare_input(pclass, sex, age, fare, scaler):
"""
Input 데이터 전처리
"""
input_data = pd.DataFrame({
'Pclass': [pclass],
'Sex': [sex],
'Age': [age],
'Fare': [fare]
})
label_encoder = LabelEncoder()
input_data['Sex'] = label_encoder.fit_transform(input_data['Sex'])
input_data_scaled = scaler.transform(input_data)
return input_data_scaled
# 로그인 구현(Session State)
# session state는 st.session_state에 저장. st.session_state.{key}에 저장해서 사용
# logged_in
if 'logged_in' not in st.session_state:
st.session_state.logged_in = False
# logged_in이 False면 => 로그인에 필요한 정보를 입력할 수 있는 공간을 노출
if not st.session_state.logged_in:
username = st.sidebar.text_input("Username")
password = st.sidebar.text_input("Password", type="password")
if st.sidebar.button("Login"):
if username == "admin" and password == "boostcamp-ai-tech!!":
st.session_state.logged_in = True
st.sidebar.success(f"{username}으로 로그인 되었습니다")
else:
st.sidebar.error("아이디 또는 비밀번호가 틀렸습니다. 다시 시도해주세요")
if st.session_state.logged_in:
st.sidebar.success("Welcome to the Titanic Survival Predictor!")
menu = st.sidebar.radio("Menu", ["데이터 분포 확인하기", "생존 예측하기"])
else:
st.warning("로그인을 진행해주세요")
st.stop() # 특정 조건에서 나머지 부분의 실행을 막고 싶을 때 사용(아래 코드가 실행되지 않도록 설정)
model, scaler = load_model()
# st.selectbox, radio, slider, number_input, date_input
st.title("Titanic Survival Predictor!")
st.subheader(":crystal_ball: Predict Survival")
# pclass
pclass = st.selectbox("Passenger Class", [1, 2, 3])
# sex
sex = st.radio("Sex", ["male", "female"])
# age
age = st.slider("Age", 0, 100, 30)
# fare
fare = st.number_input("Fare", min_value=0.0, value=32.2)
if st.button("Predict"):
st.write("hello")
user_input = prepare_input(pclass, sex, age, fare, scaler)
prediction = model.predict_proba(user_input)[0][1]
st.write(prediction)
if prediction > 0.5:
st.success(f"Passenger Survived with {prediction:.2%} probability :thumbsup:")
else:
st.error(f"Passenger did not Survive with {1-prediction:.2%} probability :thumbsdown:")
외에도 sidebar로 메뉴 토글 등 적은 시간으로 빠르게 demo 사이트를 제작가능하다.
Streamlit은 상호작용 시 전체 코드를 재실행하게 된다. interactive 후 기억을 위해서는 session_state를 활용해야한다.
if st.sidebar.button("Login"):
if username == "admin" and password == "boostcamp-ai-tech!!":
st.session_state.logged_in = True
st.sidebar.success(f"{username}으로 로그인 되었습니다")
하지만, 웹에서 주로 이야기하는 쿠키와 세션과 같이 클라이언트 정보를 쿠키로 관리하는것이 아니기 때문에 새로고침하면 세션이 날아가버린다.
데이터 로드 등 개별적으로 항상 실행할 필요 없는 함수는 @st.cache_data 나 @st.cache_resource 등으로 캐싱전략을 취할 수 있다.
python venv로 requirements.txt 깔끔하게 정리하기
$ pip list --not-required --format=freeze > requirements.txt
위 명령어로 하면 다른 패키지의 종속성으로 포함되지 않는 패키지만 출력되어 compact 하게 requirements.txt를 관리할 수 있다.
댓글남기기