
[카테캠 BE] week8 - SNS 서버 만들기(MySQL)(1)
이번주부터 2주간 MySQL 강의를 듣습니다. sns 서버를 만든다고 하네요. 실습 위주라 직접 따라가며 프로그램을 만들었습니다.
완성한 프로그램 github link
이론은 다음과 같아요!
배울 내용
- 정규화, 인덱스, 트랜젝션, 동시성 제어
- 부하테스트 ngrinder, jmeter
대용량 시스템
스케일 업과 스케일 아웃
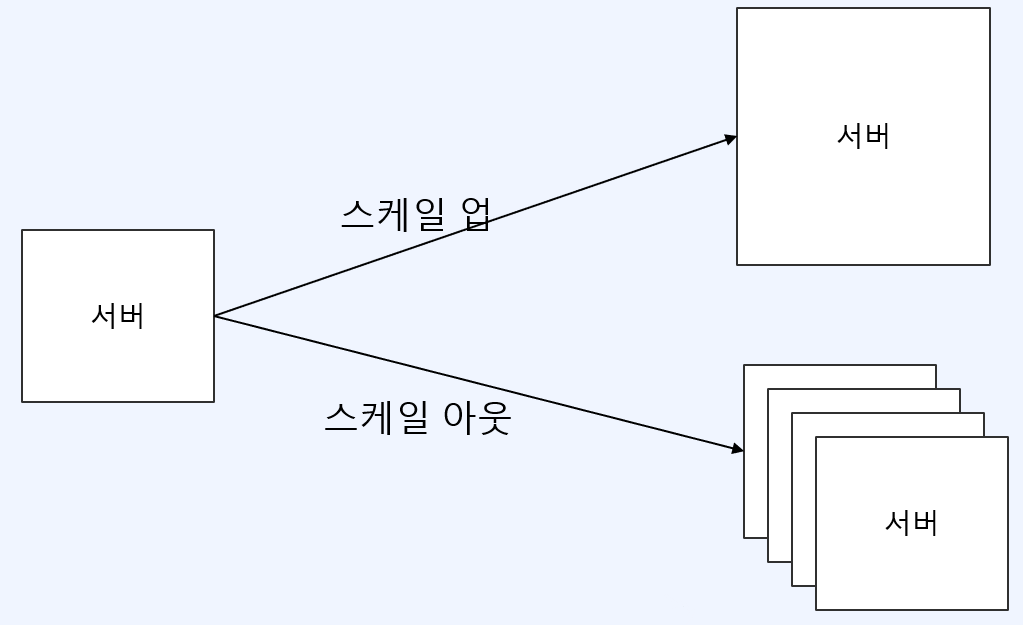
- 스케일 업
- 서버를 거대한 서버로 변경
- 유지보수 및 관리가 쉬움
- 확장성 제한
- 장애 시 위험
- 스케일 아웃
- 서버의 대수를 증가
- 여러 노드에 적절히 부하 분산 필요
- 장애 탄력성
서버의 스케일 아웃은 같은 입력에 대해서 항상 같은 결과를 반환하도록 하나의 데이터베이스를 바라보게 되어있다. 하지만 데이터베이스의 경우, 데이터라는 상태를 관리하고 있어 서버보다 스케일 아웃이 힘들고 비용이 많이 들게 된다. 따라서 서버는 상태관리를 하지 않은 채 데이터베이스에 상태관리를 위임하고, 서버를 스케일 아웃하는 방향으로 발전되었다.
대용량 시스템이 어려운 이유
- 하나의 서버로 감당하기 힘들어 대부분 여러개의 서버 또는 데이터베이스를 사용함
- 여러개의 서버에서 유입되는 데이터의 일관성을 보장할 수 있어야함
- 코드 한줄이 데이터에 미치는 영향범위가 굉장히 커짐
- 여러 서비스들이 얽혀있어, 시스템 복잡도가 상당히 높음
기본 특징
- 고가용성
- 언제든 서비스를 이용할 수 있어야한다.
- 확장성
- 시스템이 비대해짐에 따라 증가하는 데이터와 트래픽에 대응할 수 있어야한다.
- 관측가능성
- 문제가 생겼을 때 빠르게 인지할 수 있어야하고 문제의 범위를 최소화 할 수 있어야한다.
대용량 시스템 아키텍처
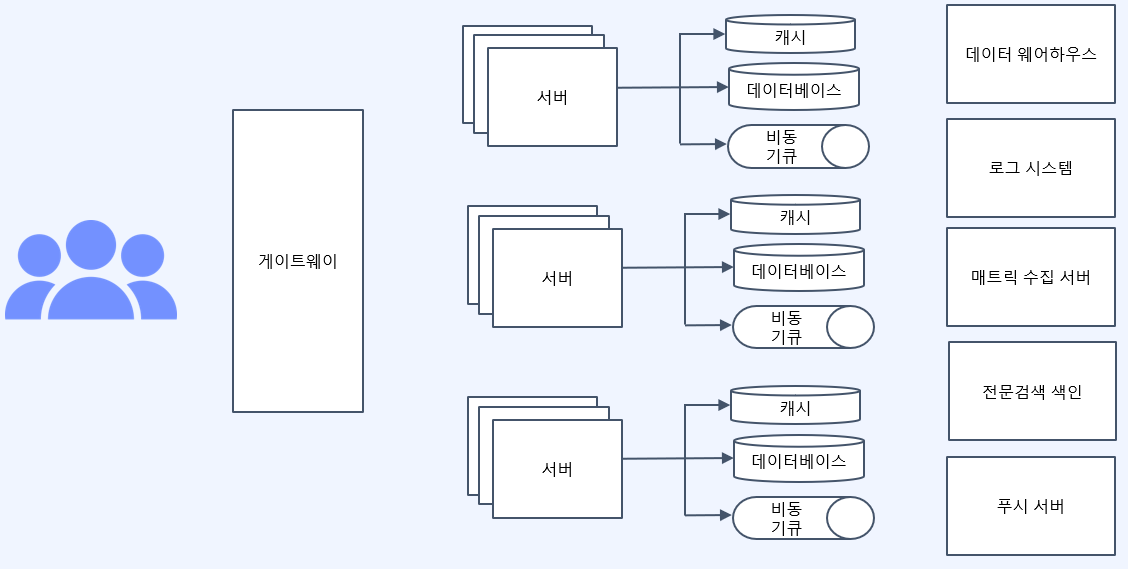
- 로드밸런서
- 여러 서버로 스케일 아웃시 도입
- 서버의 부하 분산을 담당
NGINX
- 캐시
- 단일 데이터베이스로의 요청이 너무 많아 느려서 도입
- 로컬 캐시: 각 서버 메모리에 데이터를 캐싱
- 글로벌 캐시: Reddis 서버같이 여러 서버가 하나의 캐시를 공유하게
- 비동기 큐
- 대외기관의 외부 응답속도가 느려 시스템이 느려졌을 때 도입
Kafka,RebbitMQ같은 기술 또는, 하나의 서버 내에서 쓰레드풀 사용- 클라이언트의 요청 중 대외기관과 연동된 트랜젝션을 요청에서 제외
- 클라이언트는 우리 서버에만 의존하게 되고 대외기관으로의 요청은 비동기큐로 처리
- 이런 시스템이 여러개 존재할 수 있다.
정규화
고려해야 하는 것
- 얼마나 빠르게 데이터의 최신성을 보장해야 하는가?
- 히스토리성 데이터는 오히려 정규화를 하지 않아야 한다.
- 데이터 변경 주기와 조회 주기는 어떻게 되는가?
- 객체(테이블) 탐색 깊이가 얼마나 깊은가?
정규화도 비용이다.
읽기 비용을 지불하고 쓰기 비용을 줄이는 것 - 적절히 사용해야한다.
정규화를 했다면 어떻게 사용?
- 테이블 조인
- 서로 다른 테이블의 결합도를 엄청나게 높인다.
- 별도의 최적화 기법의 적용에 있어 제한이 생긴다.
- 조회 시 성능이 좋은 별도 데이터베이스 사용, 캐싱 등
- 오히려 단순히 한번 더 읽기 쿼리를 보내는 것 큰 부담이 아닐 수가 있다.
인덱스
인덱스는 정렬된 자료구조이다. 이를 통해 탐색범위를 최소화할 수 있다.
인덱스의 자료구조
- Hash Map
- 단건 검색 속도
O(1) - 하지만 범위 탐색은 키를 하나씩 확인해봐야 하므로
O(N) - 전방 일치 탐색 또한 불가능(하나씩 확인 필요) e.g.
like 'AB%'
- 단건 검색 속도
- List
- 정렬 되지 않은 리스트 탐색
O(N) - 정렬된 리스트 탐색
O(log N) - 정렬에 대한 시간 복잡도는
O(N)~O(N * log N) - 삽입과 삭제 비용이 매우 높다
- 정렬 되지 않은 리스트 탐색
- Binary Search Tree
- 트리 높이에 따라 시간 복잡도가 결정
- 트리의 높이를 최소화하는게 중요
- 한쪽으로 노드가 치우치지 않도록 균형을 잡아주는 트리를 사용
- Red-Black Tree, B+ Tree
- B+ Tree
- 삽입 삭제 시 항상 균형을 이룬다.
- 하나의 노드가 여러 개의 자식 노드를 가질 수 있다.
- 리프 노드에만 데이터 존재
- 연속적인 데이터 접근 시 유리(리프 노드만 훑으면 된다!)
B+ Tree Visualization
B+ Tree의 구조의 변화를 삽입과 삭제를 하며 볼 수 있는 사이트
- 연속적인 데이터 접근 시 유리(리프 노드만 훑으면 된다!)
MySQL의 인덱스는 B+ Tree로 되어있다.
클러스터 인덱스
- 클러스터 인덱스는 데이터 위치를 결정하는 키 값이다.
- MySQL의 PK는 클러스터 인덱스다.
- auto increment와 UUID?
- MySQL에서 PK를 제외한 모든 인덱스는 PK를 가지고 있다.
클러스터 키는 정렬을 이루고 있고, 정렬된 순서에 따라 데이터 주소가 정해진다.
인덱스 사용하기
create index POST__index_member_id
on POST (memberId);
create index POST__index_created_date
on POST (createdDate);
create index POST__index_member_id_created_date
on POST (memberId, createdDate);
- 특정 인덱스 사용
SELECT createdDate, memberId, count(id) FROM POST use index (POST__index_member_id_created_date) WHERE memberID = 5 and createdDate between '1900-01-01' and '2023-01-01' GROUP BY memberID, createdDate;- use index를 하지 않으면 알아서 적절한 index를 사용한다. 하지만 잘못된 인덱스를 사용할 수도 있으니 주의해야 한다.
- 잘못된 인덱스를 사용 시 매우 낮은 성능을 볼 수 있다.
- 1번의 post는 2개, 5번의 post는 2백만 개
POST__index_member_id사용 시 4번을 조회하면 훨씬 늦게 된다.- 원래도 대부분을 조회해야 찾을 수 있었는데 인덱스 테이블(1과 5밖에 없음)을 보고 원래 테이블도 봐야해서 거의 2배의 시간이 걸리게 된다.
- 1번의 경우는 바로 끝난다.
POST__index_created_date사용 시 1번을 조회하면 훨씬 늦게 된다.- 날짜는 총 19,000가지 이상 존재해서 식별성이 높아진다. 따라서 4번은 매우 빠르게 실행된다.
- 하지만, 1번은 그냥 다 찾아봐야해서 늦어진다.
POST__index_member_id_created_date의 경우 모든 경우에서 빠르다.- 복합 인덱스이다.
- member_id로 정렬되고, member_id가 동일할 시 created_date로 정렬된다.
- 따라서 1번도 빠르게 확인하여 더 없는걸 확인 후 빠르게 끝나고
- 4번도 빠르게 날짜 범위를 파악해서 선택이 가능하다.
-
explain
EXPLAIN SELECT createdDate, memberId, count(id) FROM POST use index (POST__index_member_id_created_date) WHERE memberID = 5 and createdDate between '1900-01-01' and '2023-01-01' GROUP BY memberID, createdDate;- 쿼리 실행에 대한 세부 내용을 볼 수 있다. (type, key, rows, filtered 등)
인덱스를 다룰 때 주의해야 할 점
- 의도대로 인덱스가 동작하지 않을 수 있다.
- explain으로 확인 필요
- 인덱스도 비용이다.
- 쓰기를 희생하고 조회를 얻는 것.
- 꼭 인덱스로 해결할 수 있는 문제일까? 고민해보자.
인덱스 필드 가공
필드를 변형하거나 필드 타입에 맞지 않게 조건문을 작성하면 인덱스를 사용할 수 없게 되어 인덱스 테이블이 무용지물이 된다.
- 타입 잘못 넣기
SELECT * FROM Member WHERE age = '1' - 필드를 변형하기
// age는 int 타입 SELECT * FROM Member WHERE age * 10 = 1
복합 인덱스
첫번째 인덱스가 동일할 때, 두번째 인덱스를 기준으로 정렬된다.
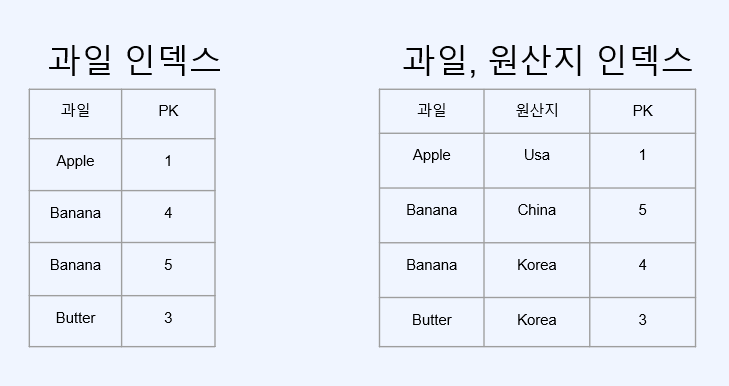
하나의 쿼리에는 하나의 인덱스 테이블만 사용된다
- 여러 인덱스 테이블을 동시에 탐색하지 않는다.
- WHERE, ORDER BY, GROUP BY를 혼합하여 사용 시 인덱스를 잘 고려해야 한다.
index merge hint를 사용하면 가능하긴 하다.
✏️여담
Spring 강의에서 안 배운 내용이 너무 많아서 실습 따라가기가 힘들었어요. 그래도 어찌어찌 잘 해냈네요. 인덱스가 저렇게 중요한 거라니 대용량 시스템에서는 생각해야할 부분이 너무 많아요. 공부할 게 끊이지 않네요..!
댓글남기기