
2026년 2월 AI 모델 릴리즈 총정리
2월 한 달간 AI 업계에서는 주요 기업들이 동시다발적으로 새 모델을 쏟아냈다. Opus 4.6의 SOTA 달성으로 시작해 Gemini 3.1 Pro의 SOTA 탈환으로 마무리된 한 달을 출시 순서대로 정리해본다.
Weekly Tech Trend Talk 스터디(26.02.12 ~ 26.02.28)
1. Claude Opus 4.6 (Anthropic, 2/5) - SOTA 달성
2월 5일, Anthropic이 Claude Opus 4.6을 출시했다. 출시와 동시에 Artificial Analysis Intelligence Index에서 종합 1위를 기록하며 화제가 되었다.
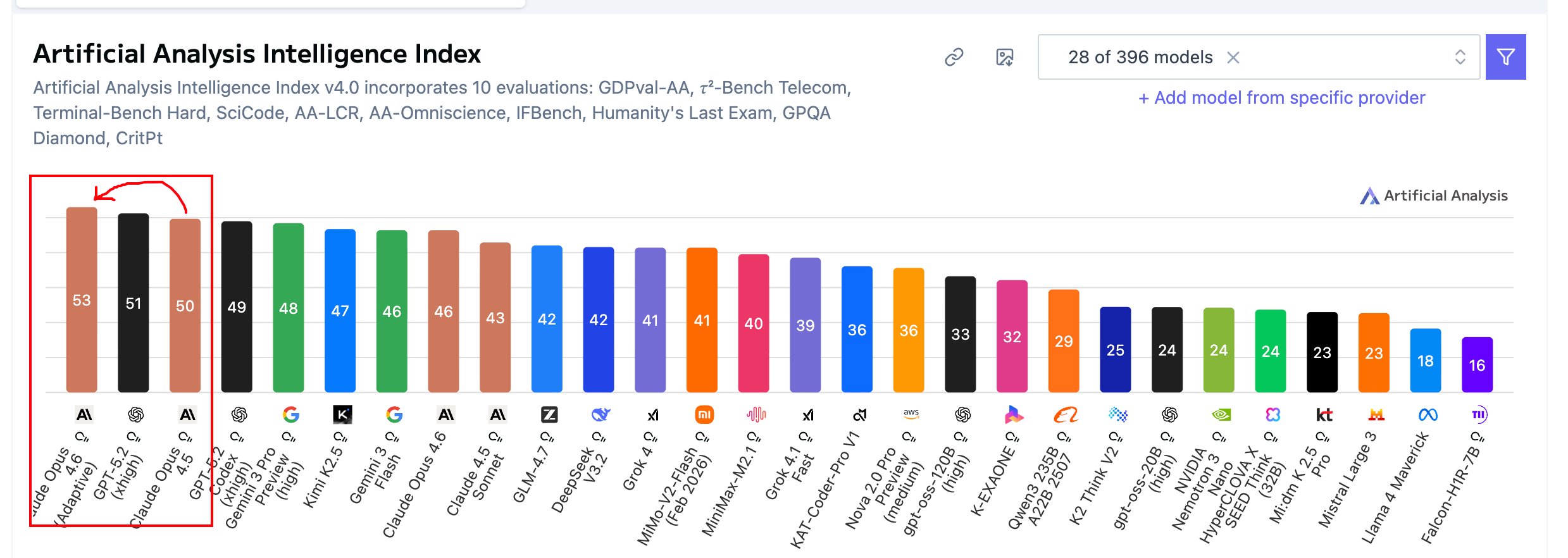
Artificial Analysis Intelligence Index v4.0은 GDPval-AA, τ²-Bench Telecom, Terminal-Bench Hard, SciCode 등 10개 평가를 종합한 지표다. Opus 4.6은 Adaptive Thinking 모드에서 53점을 기록하며, GPT-5.2(51점)와 Gemini 3 Pro(50점)를 근소하게 앞섰다.
특히 경제적으로 가치 있는 실무 작업을 평가하는 GDPval-AA에서는 ELO 1606을 달성해, GPT-5.2 대비 약 144 ELO 포인트 차이로 압도적인 우위를 보였다.
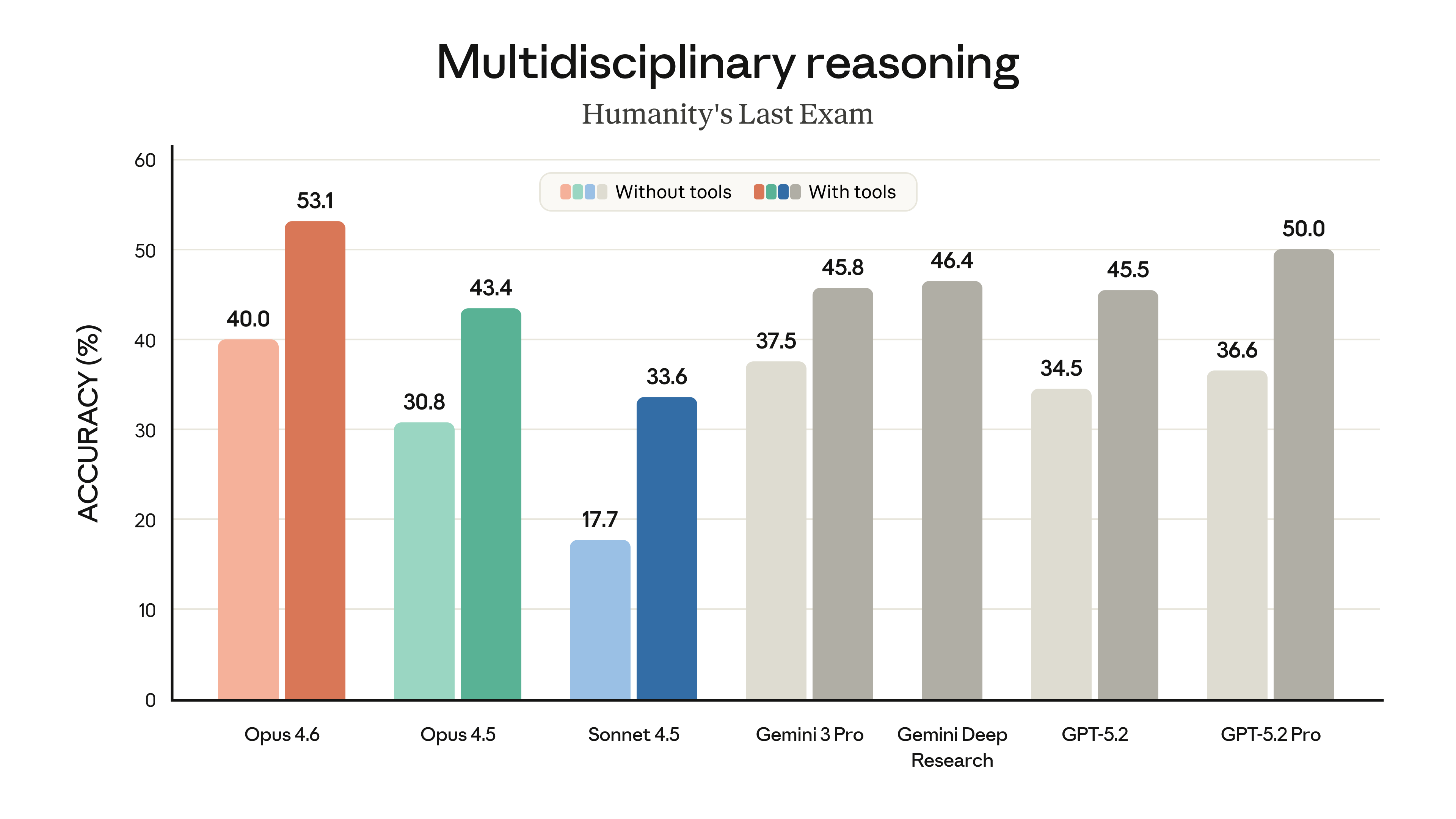
추론 벤치마크인 Humanity’s Last Exam에서도 도구 사용 기준 53.1점을 기록하며 최고 성능을 보여주었다.
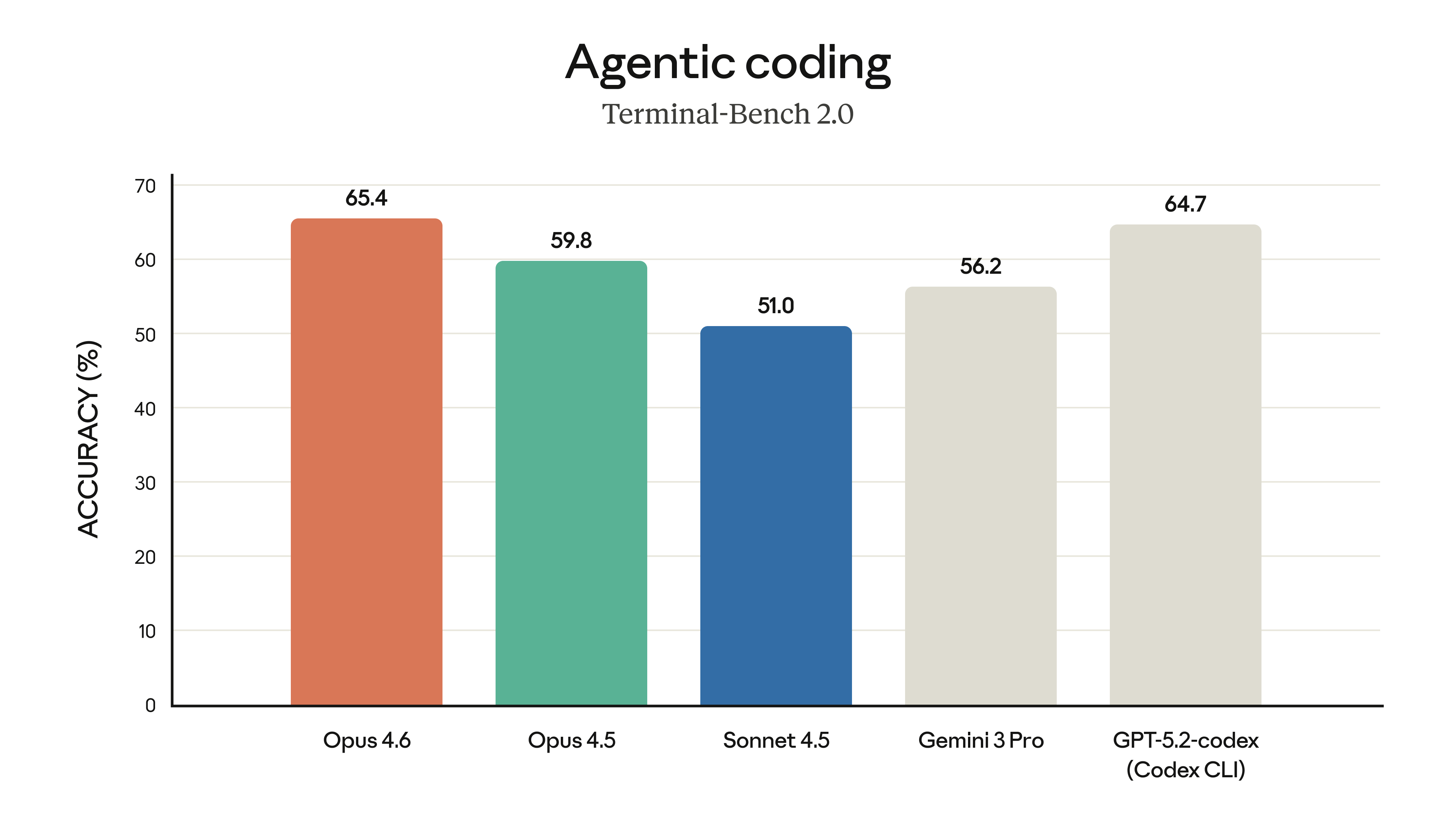
에이전트 코딩 벤치마크 Terminal-Bench 2.0에서는 65.4점을 달성했다.
2. GLM-5 (Zhipu AI, 2/11)
중국 Zhipu AI의 GLM-5는 744B 파라미터(토큰당 40B 활성) MoE 모델이다. 주목할 점은 NVIDIA 칩 없이 Huawei Ascend 칩만으로 학습했다는 것이다. 200K 토큰 컨텍스트를 지원하고, MIT 라이센스로 Hugging Face에 오픈소스 공개되었다. API 가격도 입력 \$1.00, 출력 \$3.20(백만 토큰당)으로 Opus 4.6 대비 5~8배 저렴하다.
공식 가이드에 공개된 벤치마크 자료 기준으로, MMLU-Pro, LiveCodeBench, AIME 등에서 경쟁력 있는 성능을 제시했다.
3. Google Aletheia (Google DeepMind, 2/12) - 자율 수학 연구 에이전트
Google DeepMind가 공개한 Aletheia는 수학 연구를 자율적으로 수행하는 에이전트 시스템이다.
Aletheia는 Gemini Deep Think를 기반으로 Generator → Verifier → Reviser 루프를 반복하며 자연어로 증명을 생성, 검증, 수정한다.
주요 성과:
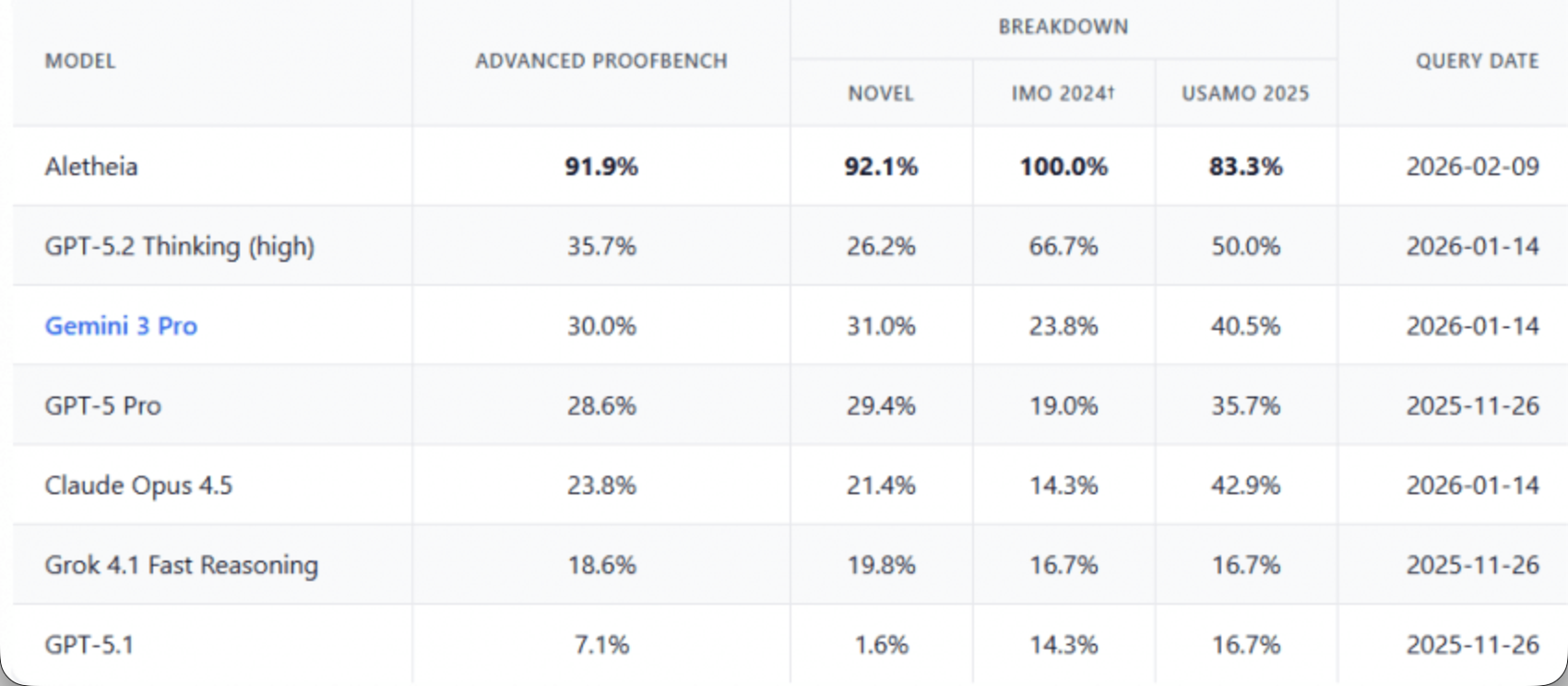
- Advanced ProofBench에서 91.9% 달성 (GPT-5.2 Thinking: 35.7%, Gemini 3 Pro: 30.0%)
- IMO 2024에서 100%, USAMO 2025에서 83.3% 기록
- FirstProof 챌린지에서 10문제 중 6문제 자율 해결
- Erdős 추측 데이터베이스 700개 미해결 문제 중 4개를 독립적으로 풀어냄 (그 중 하나는 논문으로 발표)
경쟁 수준을 넘어 실제 연구 수준의 수학 문제 해결에 도달했다는 점에서 의미가 크다.
4. Qwen 3.5 (Alibaba, 2/16)
알리바바의 Qwen 3.5는 397B 파라미터 MoE 모델로, 전작 대비 60% 저렴한 운영 비용과 8배 효율 개선을 달성했다. 텍스트, 이미지, 비디오를 하나의 시스템에서 처리하는 네이티브 멀티모달 기능이 특징이며, 2시간 분량 비디오와 200개 이상 언어를 지원한다. 오픈 웨이트로 공개되어 GPT-5.2, Claude Opus 4.5, Gemini 3 Pro를 여러 벤치마크에서 넘어섰다고 주장한다.

공개 벤치마크 자료에서는 MMMU, MMLU-Pro, SWE-bench 등 다양한 항목에서 동급/상위 모델과 경쟁 가능한 점수를 제시했다.
5. Claude Sonnet 4.6 (Anthropic, 2/17)
Sonnet 4.6은 Sonnet 계열 최초로 1M 토큰 컨텍스트 윈도우(베타)를 지원한다. 코딩, 컴퓨터 유즈, 에이전트 플래닝 전반에서 전작 대비 크게 향상되었으며, 가격은 Sonnet 4.5와 동일한 \$3/\$15(입출력 백만 토큰당)를 유지했다. 현재 claude.ai와 Claude Cowork에서 기본 모델로 설정되어 있다.
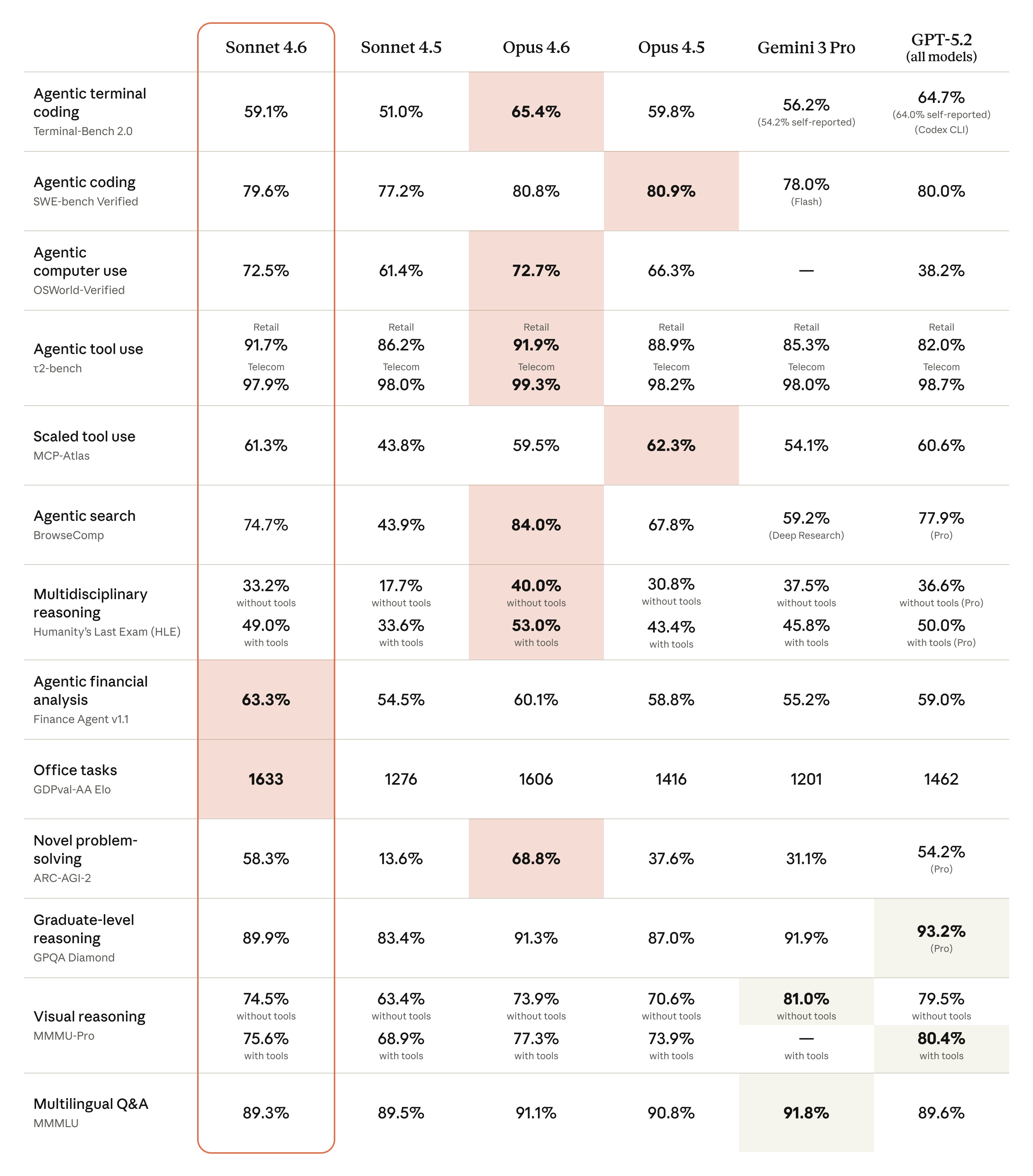
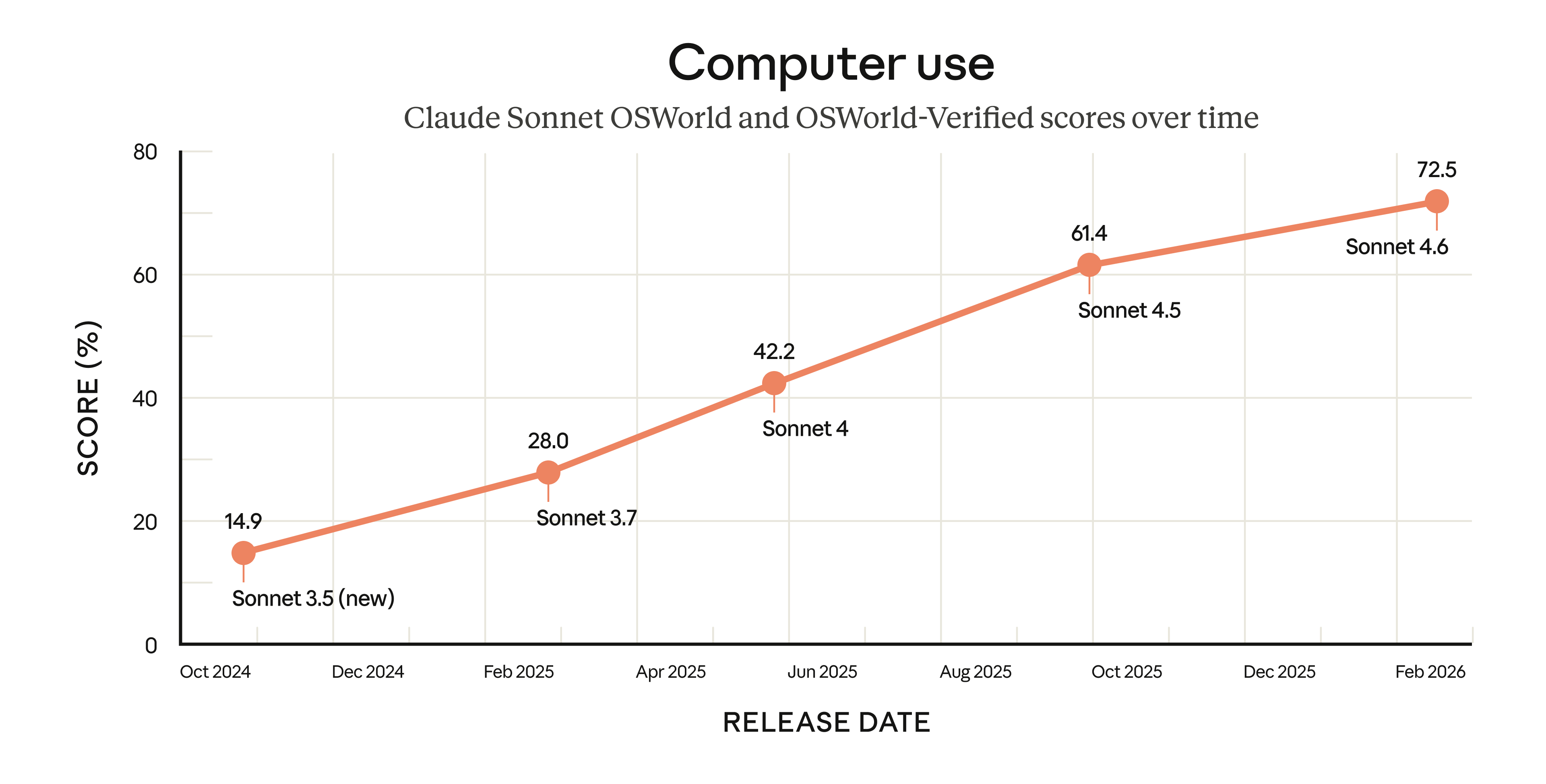
특히 OSWorld 계열 에이전트 환경과 코딩 중심 평가에서 전작 대비 개선 폭이 컸다.
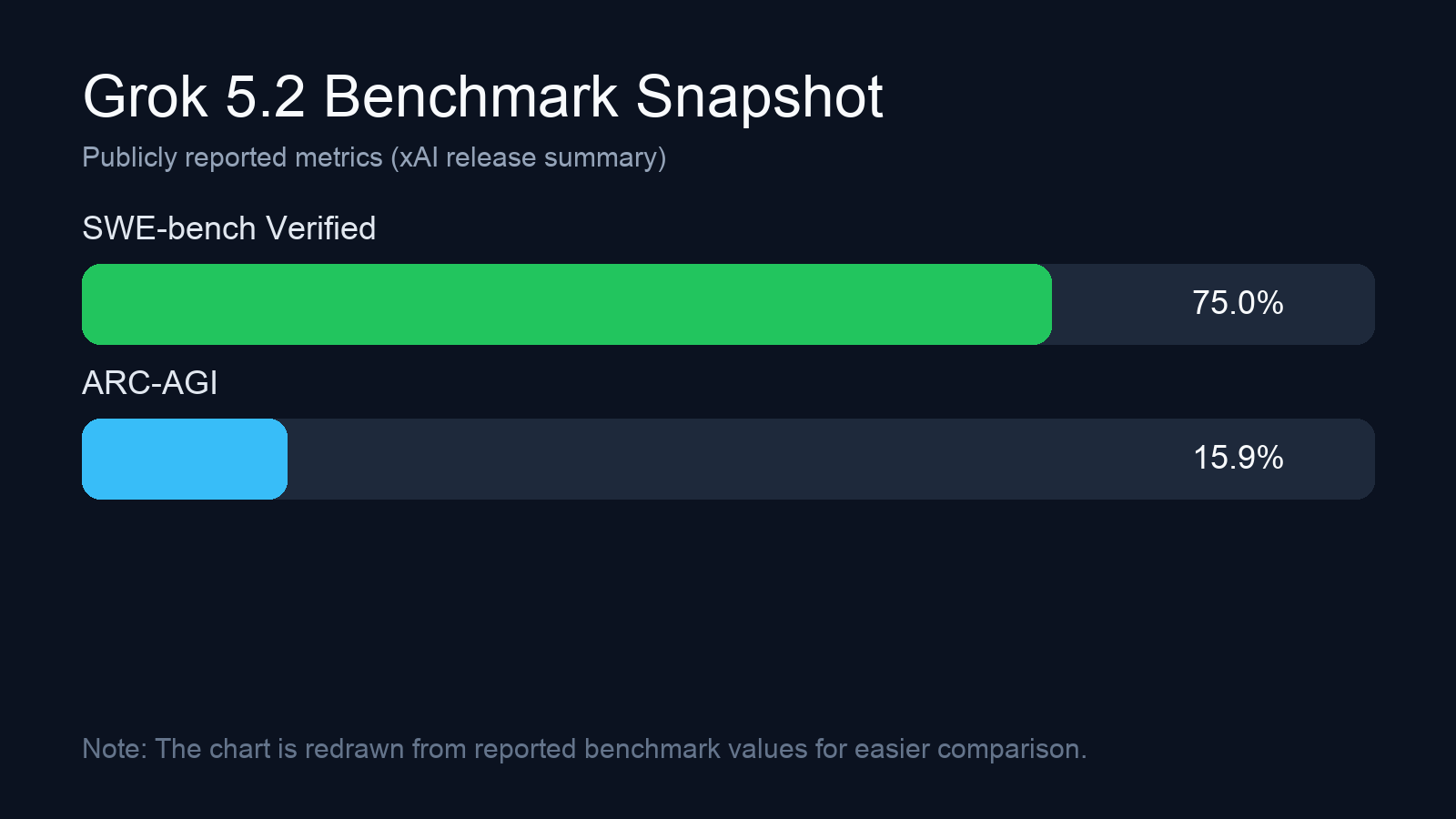
6. Grok 5.2 (xAI, 2/17)
xAI의 Grok 5.2는 약 1T 파라미터, 256K 컨텍스트 윈도우를 갖춘 모델로 소개되었다. 4개 전문 에이전트가 병렬로 사고한 뒤 결론을 종합하는 구조가 특징이며, SWE-bench 75%, ARC-AGI 15.9%를 기록했다. SuperGrok(\$30/월) 또는 X Premium+(\$40/월)로 접근할 수 있다.
7. Gemini 3.1 Pro (Google, 2/19) - SOTA 탈환
Gemini 3.1 Pro는 Google의 가장 진보한 복잡 작업용 모델이다. 출시 이후 Artificial Analysis Intelligence Index에서 Opus 4.6을 제치고 종합 1위를 탈환했다.
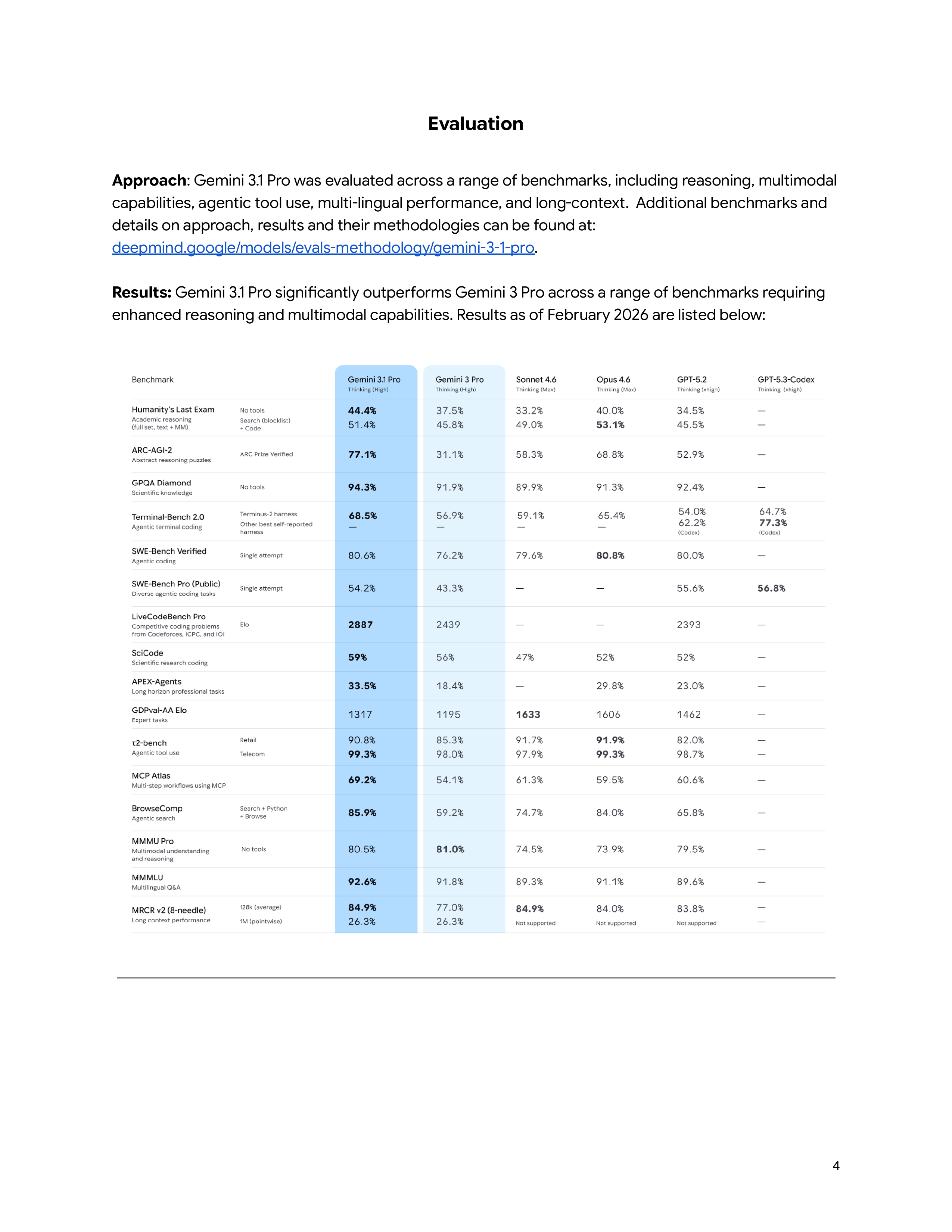
ARC-AGI-2 벤치마크에서 77.1%를 달성해 전작(Gemini 3 Pro) 대비 추론 성능이 2배 이상 향상되었다. Humanity’s Last Exam에서도 Gemini 3.1 Pro가 64.4%를 기록해, Opus 4.6의 51.4%(no tool)를 크게 앞섰다.
다만 롱 컨텍스트 성능은 아쉬운 부분이다. 1M 토큰 기준 MRCR v2(8-needle) 벤치마크에서 Gemini 3.1 Pro는 26.3%에 그친 반면, Claude Opus 4.6은 같은 조건에서 76.0%를 기록했다.
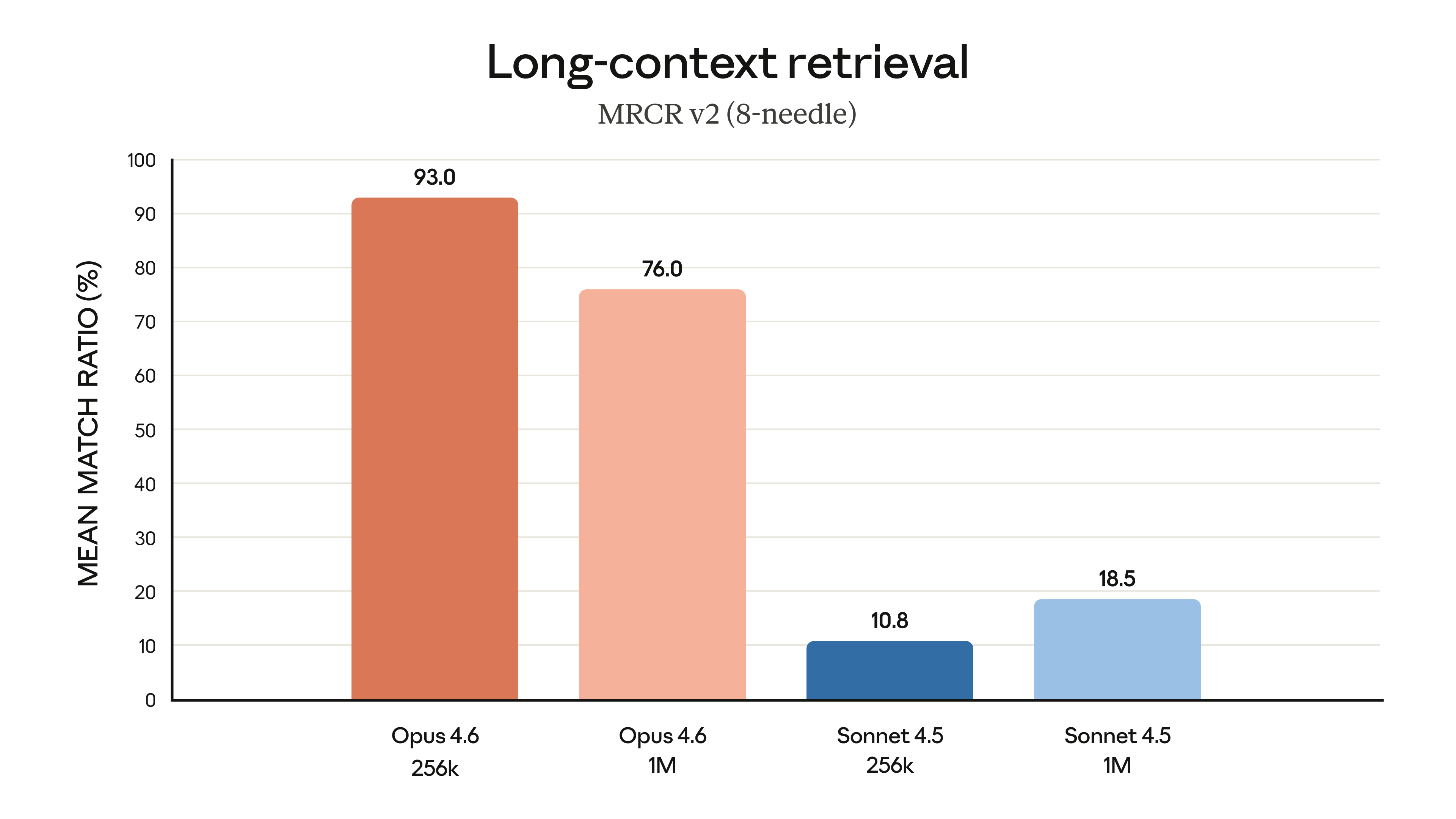
추론 능력은 뛰어나지만, 긴 컨텍스트가 필요한 대규모 코드베이스 분석 등의 작업에서는 Claude 모델 대비 성능이 떨어질 것으로 보인다.
Gemini 앱, NotebookLM, Vertex AI, Gemini CLI 등에서 사용할 수 있다.
참고: Gemini 창작 기능 포스트
Gemini의 창작 기능 확장(Lyria 3 + Nano Banana 2)은 별도 포스트에서 통합 정리했다. Gemini 창작 기능 확장 포스트
후기
Opus 4.6이 SOTA를 달성하며 2월의 문을 열었고, 불과 2주 뒤 Gemini 3.1 Pro가 이를 다시 탈환했다. 그 사이 GLM-5, Qwen 3.5, Sonnet 4.6, Grok 5.2가 연이어 출시되며 치열한 경쟁이 이어졌다.
모델 간 SOTA 경쟁이 빠르게 순환하는 가운데, 각 모델의 강점은 명확히 갈리고 있다. Gemini 3.1 Pro는 추론에서 압도적이지만 롱 컨텍스트에서는 Claude에 한참 뒤처지고, 오픈소스 진영의 GLM-5와 Qwen 3.5는 가격 대비 성능으로 빠르게 추격하고 있다.
AI 모델 경쟁은 단일 지표의 SOTA가 아니라, 용도에 맞는 최적의 모델을 선택하는 시대로 접어들고 있다.
댓글남기기